2.2 Referential Integrity and Tuning
|
| < Day Day Up > |
|
How Referential Integrity and tuning are related is twofold. Firstly, decide whether to use or implement Referential Integrity at all and secondly, if implementing, how?
2.2.1 Using Referential Integrity or Not
Should Referential Integrity be implemented? If so, how? The question should be, "Should you implement Referential Integrity at all"? You should but for the sake of performance sometimes it is not needed. For the sake of maintaining the integrity or correctness of your data you should implement Referential Integrity. It is always advisable to implement Referential Integrity partially, at least on critical relationships. For instance, some static entities do not necessarily need to have Referential Integrity checks even if it is advisable. Continual Referential Integrity checking will affect performance.
Use Referential Integrity where it is needed. When data is changing constantly we continually need to check that the data changes are valid. This is where Referential Integrity comes into play. Consider for instance a data warehouse. Typically data warehouse databases or reporting databases are used to report data or store large amounts of data and hence require throughput. Throughput implies large amounts or processing and database access at once. Reporting databases report, they read data. If they are updated they are often mass updated in batches that can be recovered and executed again. Is Referential Integrity required in data warehouse databases with no OLTP or client-server like updating activity? That is often a very resounding "No!" Referential Integrity is required to validate changes to the database.
If generic static entities are used Referential Integrity is inadvisable on these entities. A generic static entity is a table including multiple types of static data items, which are unrelated to each other in any way other than structurally. Repeating the diagram from the Introduction, as shown in Figure 2.1, we can see an example of a generic static entity. Please be aware that the creation of generic static entities is not anything to do with Normalization. Generic static entities allow for more modular application coding and not Referential Integrity. Efficient data modeling and Normalization does not always benefit when created from the perspective of creating better application code. If you have generic static entities get rid of them if possible!
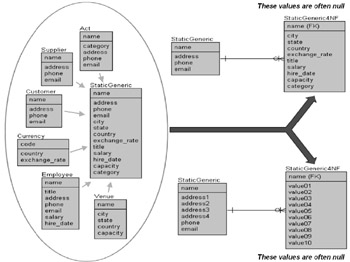
Figure 2.1: Static Generic Entities
| Tip | Generic static entities are often created to allow for ease of programming. Structuring the data model from the perspective of creating generic application code does not necessarily lend itself to an efficient data model. Keep generic code in the application and out of the database if possible. If some aspect of a data model makes application coding easier it is probably detrimental to database performance. |
If generic static entities must be used it might be best to enforce Referential Integrity in the application and not in the database since those generic aspects stem from the application.
2.2.2 How to Implement Referential Integrity
Referential Integrity can be implemented at the database level or in the application. The chances are that coding referential data checks in the application will produce messier code, which is less granular or modular than is desirable. This is because application code will be performing tasks probably meaningless to application functionality. The functionality of an application can sometimes have little to do with Normalization of data. Including Referential Integrity in application code might perform better than at the database level since processing is distributed. However, distribution does not necessarily mean better response time for the customer since client or middletier machines will be performing extra processing.
At the database level Referential Integrity can best be implemented using primary and foreign key constraints. Using triggers should be avoided like the plague! Triggers are notoriously slow. Oracle Database triggers usually perform at speeds up to at least 10 times slower than using constraints for Referential Integrity. Triggers are written in interpretive PL/SQL code, which is slow to execute. Additionally triggers do not allow COMMIT or ROLLBACK commands because they are event driven and can drive other events; they can as a result produce large transactions. It is commonplace that Referential Integrity is implemented using triggers when an organization has a lack of data modeling skills and programming skills are abundant. Obviously the reverse will be true when programming skills are lacking, but problems in other areas could arise.
Changes later on, such as disabling some referential checks, will be much easier to find and change in the database when implemented with constraints. Sifting through a lot of trigger code or application code in order to change Referential Integrity constraints could be very time consuming. Also any technical manager knows that each programmer has an individual style and approach to writing code. Since personnel in the computer industry are notorious for job-hopping, new coders working on someone else's code can be very problematic indeed, especially if the original coder was very messy. Building Referential Integrity with constraints is much more manageable. Skills required are an understanding of Normalization plus simple constraint creation using DDL administration commands or Oracle Enterprise Manager. These skills are easily learned with a little practice.
To summarize, changing application code will always introduce new bugs, some completely unexpected! Trigger code is less likely to cause problems than application code in this respect because it is centralized and in one place in the database, not in multiple applications. Changing constraints involves simple changes to the Oracle Database metadata. What could be easier? In short, the more Referential Integrity is implemented without using constraints the more problems you will have. Changes to the data model, for instance, will probably not be possible if Referential Integrity is implemented at the application level. On the other hand, changing simple database-level constraints will not effect the application in any way whatsoever. The only possible effect on the application is if the application is using the tables in a way which is violating Referential Integrity. This of course is positive since data integrity errors will be detectable and can be corrected, probably in development and testing.
| Tip | Every form of implementation depends on the current situation and circumstances, both from a technical and business perspective. In other words, everything is relative to the resources available: time plus personnel and financial resources. If changes cannot be made easily to poorly built software then try resolving potentially business-threatening problems in little steps. You do not have to do everything at once. |
So what's the "skinny" on implementing Referential Integrity?
-
Implement Referential Integrity at the database level using primary and foreign key constraints. This is usually the best way both for the short term and the long term.
-
Avoid placing Referential Integrity code into the application because later changes for the purposes of helping performance could be problematic, both for tuning the data model and SQL code. The result is likely to be application bugs and little potential for tuning. Coding Referential Integrity into application code will not only over-code but introduce more complexity into application code and will ultimately hurt speed and maintainability.
-
Remove or disable any Referential Integrity constraints from the database at a later stage as required and if necessary. There is much which can be done to keys, indexes, tables, and all sorts of other things in the database itself, easily and in one place.
Using Constraints (Primary and Foreign Keys)
Now we want to examine using constraints to implement Referential Integrity. Referential Integrity establishes relationships between entities. In the case of the relational database model those relationships are most commonly one-to-many in nature. The result is what could be perceived as a hierarchical structure where an entity could contain links to collections of other entities, such as that shown in Figure 2.2.
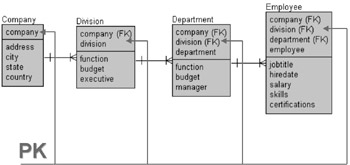
Figure 2.2: A Hierarchy of Relational Entities
In Figure 2.2 note that many divisions are in a company, many departments are in each division, and each department has many employees. Each successive child entity, passing from companies down through to employees, inherits the primary key of its parent entity. Thus the Company table has a primary key called Company, the Division table has a primary key made up of a concatenation of both the company name and the division name, and so on.
The primary and foreign keys, denoted in Figure 2.2 as PK and FK, are what apply Referential Integrity. Thus in order for a division to exist it must be part of a company. Additionally, a company cannot be removed if it has an existing division. What Referential Integrity does is to verify that these conditions exist whenever changes are attempted in these tables. If a violation occurs an error will be returned. It is also possible to cascade or pass changes down through the hierarchy.
Tuning the structure of the keys will be covered in a later chapter. However, it will suffice at this stage to state that the primary key structures represented in Figure 2.2 are not as efficient as they could be. How would we make these primary keys more efficient?
Efficient Keys
In a purist's or traditional relational data model keys are created on actual values such as those shown in Figure 2.2. The primary key for the Company table is created on the name of the company, a variable length string. Always try to create keys on integer values. Integer values make for more efficient keys than alphanumeric values since both range and exact searches through numbers is mathematically much easier than with alphanumeric values: there are 10 possible digits to compare and many more alphanumeric characters. Sorting and particularly hashing is much more efficient with numbers.
Always try to avoid creating keys on large fixed or variable length strings such as Oracle Database VARCHAR2 data types. Dates can also cause problems due to implicit conversion requirements, and differences between dates and timestamps. Creating keys on anything other than integers or short, fixed length string values is generally asking for trouble. Numbers require less storage and thus shorter byte lengths. Oracle Database NUMBER field values occupy a maximum number of bytes based on the number of digits in a value. The only negative aspect is that as the numbers grow, predicting space occupied becomes more difficult. Sometimes it may be useful to create keys using short fixed length character strings. An Oracle Database CHAR(3) datatype will use exactly 3 bytes, a known and predictable value. However, short fixed length character strings were often used in the past as substitute coded values for large variable length strings. This is rare in modern relational data models due to the object nature of application development tools such as Java.
Some applications create primary and foreign key structures using alphanumeric object pointer representations. This is generally not efficient because the representations of these pointers will require variable length strings using Oracle Database VARCHAR2 datatypes. This approach should be avoided in a relational data model and is much more appropriate to an object data model.
A possibly more efficient key structure for the data model in Figure 2.2 would be as shown in Figure 2.3 where all variable length strings are relegated as details of the entity by the introduction of integer primary keys.
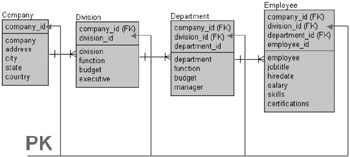
Figure 2.3: A Hierarchy of Relational Entities Using Integer Keys
Another variation on the data models in both Figures 2.2 and 2.3 would be the data model shown in Figure 2.4 where the relationships become what is known as nonidentifying. In Figure 2.4 each entity contains its own unique integer identifier as a primary key and all parent unique integer identifiers are removed from the primary key, becoming foreign keys where applicable. Foreign keys not directly related to immediate parent entities are removed altogether. Thus entities in Figure 2.4 allow unique identification of every row within each table based on the primary key. This is a little closer to the object model and is more consistent with modern object application development environments such as Java. Consistency is always beneficial. However, the Employee table in Figure 2.4 could additionally include the COMPANY_ID and DIVISION_ID columns as foreign keys to allow for better flexibility. The same would apply by including the COMPANY_ID column in the Department table.
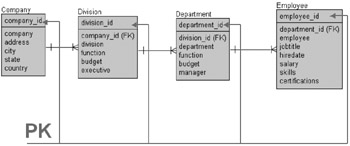
Figure 2.4: A Hierarchy of Relational Entities Using Unique Integer Identifier Keys
Unique integer identifiers are most efficiently created in Oracle Database using sequence number generators. Never create unique identifiers for new rows in tables using something like SELECT MAX(identifier) FROM table. This approach will execute a full table scan whenever a new row is added, which is extremely inefficient. Maximum integer identifier values stored in a separate central table of sequence numbers would create hot blocks and concurrency issues but might be more efficient than using a MAX function for every new row required, especially for large tables. Oracle Database sequence objects are by far the most efficient method for integer identifier value generation.
| Tip | In Referential Integrity primary keys and foreign keys are known as "keys." Keys are not explicitly called indexes because the two are not quite the same thing. |
Indexing Foreign Keys and Locking Issues
Oracle Database automatically creates indexes on primary keys and not on foreign keys. An index is automatically created on a primary key because it is required to be unique. Uniqueness implies that when a new primary key is inserted into a table the whole table must be searched to make sure that the new insertion is not duplicating an already existing key.
If indexes are required on foreign keys they must be created manually. Generally it is essential to create indexes on foreign keys to avoid locking problems. These locking problems occur due to full table scans and potential shared or exclusive locks on the child table when doing updates or deletes in the primary key table.
In a highly concurrent environment, when changes constantly occur to rows in parent and child tables, serious wait times for lock releases on the child table could result when changing primary key parent tables. Why? Oracle Database searches for the existence of child table foreign keys when update or deletion occurs on a parent table.
| Tip | Updates should not occur to primary keys because they are static in nature, especially in the case of abstracted integer identifier primary keys. Primary key updates are more likely in more traditionally designed relational databases but should not happen very often. |
When Oracle Database searches into the child table, if no key exists on a foreign key, a full table scan will result on the child table because every foreign key must be checked. This can cause locking on the child table. Other concurrent DML activity occurring on the child table would exacerbate the problem. Concurrency issues can be addressed but only up to a point.
The result of creating indexes on foreign keys will be much better performance, particularly in highly concurrent environments. It reduces locking and contention on the child table, since only the index on the foreign key is checked. SQL which is continuously table scanning as a result of no foreign key indexes could kill the performance of your system.
The more sound your data model is the more foreign key indexes will help performance, since the data model key structure should match application requirements. Build indexes on foreign keys to prevent locking issues, not only for Referential Integrity constraint checking but also for SQL performance.
New primary key insertions do not require indexes on child table foreign keys since no activity occurs on the child table. Figure 2.5 attempts to show a picture of potential foreign key locking activity.
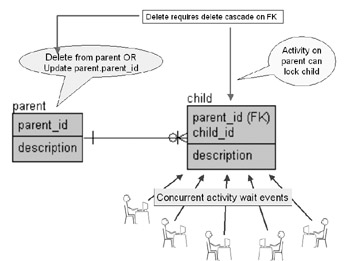
Figure 2.5: Avoiding Locking on Foreign Keys
Sacrificing Referential Integrity for Performance
Can performance be increased by removal of primary and foreign keys plus foreign key indexes? Yes sometimes, but it is extremely risky in relation to maintaining the integrity of rows between parent and child tables.
Creating indexes on foreign keys is required when parent tables are updated or deleted from, not inserted into. It may be difficult for a database administrator to be certain of this given limited knowledge of applications and any future changes. In fact the database administrator's knowledge is probably limited to being outside the scope of development. Database administrators are often not included in the development process. Some companies may not even hire a database administrator until the development process is complete or nearing completion.
In cases where child tables are static and very small, perhaps Referential Integrity checks between the parent and child tables are less necessary. In this case one must assume applications always validate the existence of foreign key child rows when adding or changing primary keys. Again, the child table has to be small! The Optimizer will usually full table scan small tables, regardless of the presence of indexes. This further builds the case where small static tables can simply be excluded from Referential Integrity checks by removing or disabling any child table foreign key constraints. Under these rare circumstances it may also be expedient to remove or disable the primary key constraint from the child table as well. Since the table is static there may never be a need to ensure that the primary key remains unique.
Once again this strategy is risky and inadvisable but could be utilized under extreme circumstances when creating indexes on foreign keys has not fully resolved concurrency and locking performance issues. The full strategy is one of two options:
-
Always create indexes on foreign keys for all types of tables.
-
For small static tables, if indexes are not created on foreign keys, it may be best to exclude a child table from Referential Integrity altogether by disabling child table foreign key constraints. If this is acceptable the child table primary key constraint may as well be disabled.
Coding Business Rules in the Database
We have already established that Referential Integrity can be implemented in the database by using either constraints or triggers. Constraints are usually more easily maintained than triggers, depending on the skills available. Using triggers to implement Referential Integrity will be much slower. Triggers may be more easily maintainable during development, especially if the data model is continually changing. Constraints are more easily maintainable in production since changes are less likely to cause errors. Code changes are always likely to introduce unexpected bugs. If constraints are continuously being changed then the system should still be under development. If the data model is not correct at the time of your first production release then you may have all sorts of other problems too.
So what are business rules? This term is used offhandedly where it could quite possibly have different meanings. Some technical people will insist on placing all business rules into the database and some will insist on the opposite. This is quite often because of a lack of skilled personnel in development, database administration or data modeling. Many development projects are top heavy with developers and lacking in administration and modeling skills. A technical manager will often quite sensibly tend to guide system development in the direction of the skill sets available, be those skills development or otherwise. An ideal situation is having all skills. Coding business rules in the database or not is often a problem with terminology, namely the term "business rules". Therefore, let's categorically avoid a definition for the meaning of that term. We will concentrate not on what should or should not be in the database but what could be in the database.
There are two important areas:
-
Referential Integrity: can be implemented in the database using constraints or triggers.
-
General database access using SQL code: stored procedures and functions.
Using Triggers for Referential Integrity
The case often made for triggers rather than constraints is that triggers are more easily managed. This is often the case when programmers rather than database administrators or data modelers are building those constraints. Programmers are usually frustrated with having to enable, disable, and perhaps even temporarily drop constraints in order to change tables. In fact most table changes do not require constraint changes unless the primary or foreign keys are being changed directly; primary and foreign keys restrict data in tables not the structure of those tables. Where a database administrator would carefully alter a table and never drop a table it is quite normal for developers, during the development process, to simply drop tables. Dropping tables and recreating tables in a production environment is very risky. This sort of practice is common during the development process.
Programmers generally make poor database administrators because the approach to database administration is generally a slower and more careful one. In defense of the programming community, database administrators often make terrible programmers. I have seen some database administrators with Unix backgrounds construct and write entire systems using Unix scripting, even avoiding a primitive programming language such as PL/SQL. This little story I hope makes it more palatable for a developer to understand that database administration is a much more meticulous process, particularly in production. The skills of coding and administration are very different in approach but both are required, even during the development process. In fact database administrators tend to subdivide themselves into one of two camps, Production DBAs and Development DBAs. The acronym "DBA" stands for database administrator.
| Tip | Older relational databases and perhaps very ancient versions of Oracle Database required dropping of tables in order to make structural columnar changes: adding, changing, or deleting columns. For many years Oracle Database has been extravagantly equipped with both object CREATE and ALTER commands, allowing more or less any change to a table even when tables are online and actively being used. |
So what does all this mean? It means triggers are a hopeless substitute for constraints as a method of enforcing Referential Integrity. Triggers make implementation easier for a programmer but will seriously affect performance in the long run, perhaps even making your application as much as 10 times slower than it could be.
Using Triggers for Event Trapping
In some relational databases triggers can be used to trap specific database events in addition to SQL insert, update, and delete events. In Oracle Database this is not the case. Triggers are a less efficient substitute for constraints when implementing Referential Integrity.
Trigger code is slow because coded PL/SQL will execute much slower than Oracle Database internal constraint checks. Trigger code must be parsed and compiled before execution and uses explicit SQL. Explicit SQL competes with all other SQL in the database for use of parsing and execution resources.
Triggers may require too much coding maintenance. Constraints should be created when the data model is first built such that a database administrator is in a position during production to be able to switch off specific constraints in order to help performance. This type of tuning can be difficult with triggers if individual triggers contain multiple aspects of functionality such as a trigger detecting all insert, update, and delete events for a table. A better approach could be a set of three triggers on that same table: one for each of insert, update, and delete event detection. Coders tend to amalgamate functionality and make things generic. Generic code is not consistent with an efficient data model, as in the case of the static generic entity shown in Figure 2.1.
I have worked with an application in the past where replacement of triggers with constraints gave a general performance increase of between five and tenfold. It is also unlikely that a single trigger cannot deal with all potential problems. The simple fact is that the more code an application has the more convoluted and difficult to maintain it will become over time. If you are creating triggers because they are easier to maintain then the data model is probably being built during the coding phase, which has its disadvantages.
Using Stored Procedures and Functions
Stored procedures and functions can be used for SQL activity as opposed to embedding SQL code in applications. I have encountered varying opinions on this subject and have seen both work and both fail. Stored procedures can include only SQL code or they can include some processing, either in the form of groups of SQL statements, to form transactional blocks, or even as far as including application logic; logic which should probably be at the application level but not necessarily.
In short PL/SQL is not a fully capable programming language. PL/SQL has programming language capabilities and a few bells and whistles, even some object and abstraction capability.
From my experience my recommendation is this. PL/SQL can be used to store database SQL code in one place. This has the effect of only allowing people with PL/SQL and Oracle database administration skills to build and change that code. However, since PL/SQL is essentially primitive as a programming language and developers make better programmers than database administrators, there is a strong case for minimizing use of PL/SQL.
Do not write your entire system using PL/SQL. When using PL/SQL to create database access SQL code think rather in terms of granularity, simple maintenance, and central control as good reasons for using PL/SQL. Modern application environments are very effective at managing and allowing creation of embedded SQL code. Using stored database procedures is probably faster but this is not always the case. Use of stored procedures is very much dependent on skills and the function of applications. Programmers should not be doing too much database administration and modeling because that is not a programmer's area of expertise. In terms of overcoding and perhaps overloading a database with stored procedures you may also overload your database administrators. Additionally, most Oracle database administrators have Unix backgrounds and will quite probably write PL/SQL stored procedures that look like scripts. HTML and JavaScript are scripting languages. Java is a programming language as PL/SQL is supposed to be.
Oracle Database will allow the creation of stored procedures using Java with a JVM embedded in the Oracle Database kernel. There is also a compiler called the Java Accelerator which will allow compilation of Java coded stored procedures into binary, allowing for fast execution times. Performance of Java coded stored procedures is unknown to myself as I have never used Java in Oracle Database as such. Java is an extremely rich coding environment. If even more complexity is required external binary compilations can be used, coded in high execution performance languages such as C.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 164