2.3 Optimizing with Alternate Indexes
|
| < Day Day Up > |
|
Alternate indexes are sometimes known as secondary indexes. The use of the terms alternate and secondary is somewhat confusing because they mean different things in English. In the context of a relational database they are one and the same. Alternate implies another option and secondary implies in addition to. This means the same thing so now we are all completely confused. The precise meaning of the terms in this context is really immaterial.
The problem is this. We create alternate indexes because the primary and foreign key indexes in our data model do not cater for everything our applications require for filtering and sorting. Filtering and sorting SQL statements is what uses indexes to access the database quickly by accessing much smaller amounts of physical space, in a required sorted order.
Having a lot of alternate indexes means your database has a lot of indexes to maintain. Whenever a table is changed every index created on that table must be changed as well. Thus, inserting a single row into a table with four indexes actually requires five additions and not one. That will hurt performance, sometimes very badly. If your database has a large number of alternate indexes a number of possibilities could be responsible.
-
The most obvious is imposition of reporting-type functionality over the top of OLTP-type functionality. More traditional relational database structures such as those shown in Figures 2.2 and 2.3 include composite primary keys and are more compatible with reporting efficiency. Structures such as that shown in Figure 2.4 do not have composite primary keys. Imposition of reporting requirements on the structure in Figure 2.4 would probably require composite alternate indexes.
-
When creating alternate indexing essential to reporting, SQL statements may require filtering and sorting, different to primary composite keys such as those shown in Figures 2.2 and 2.3. When existing composite primary keys do not cater for requirements then perhaps either further Normalization or Denormalization is a possibility, or current structures simply do not match application requirements. However, changing the data model at a later stage is difficult and further Normalization can cause other problems, particularly with recoding of application and stored procedure code.
-
A less obvious and often overlooked possibility is that the database has been ported directly from development to production. Developers have a habit of creating a lot of indexes whilst coding. Quite often they will not clean up and remove indexes no longer in use.
-
Sometimes in object structures such as that in Figure 2.4, since abstract unique identifiers are used for primary keys, items such as names of people or departments may be required to be unique. These unique keys are not part of Referential Integrity but they can be important, and are best maintained at the database level using constraints.
In summary, there is no cut and dried answer to which alternate keys should be allowed and how many should be created. The only sensible approach is to keep control of the creation of what are essentially "extra" keys because they were not thought about in the first place or because an application designed for one thing is expanded to include new functionality such as reporting.
Alternate indexing is not part of the Normalization process. It should be somewhat included at the data model design stage, if only to avoid difficulties when coding. Programmers may swamp database administrators with requests for new indexes if they were not added in the data modeling process. Typically alternate keys added in the data modeling stage are those most obvious as composites where foreign keys are inherited from parent tables, such as the composite primary keys shown in Figures 2.2 and 2.3. Note that this does not apply in the object-like hierarchical structure represented in Figure 2.4 since the parent of the parent is not present on the child table as a foreign key; it is not required to be.
The structure in Figure 2.4 is very typical of modern Java object application environments where every table's primary key is unique to the entire database, within that table. In other words, a row in a child table can be accessed using its primary key without the necessity for obtaining the parent table primary key first; there is no direct dependency between the parent and child tables, at least in an abstract sense. Figure 2.4 is more like an object database than a relational database. Figure 2.4 represents an object to relational mapping solution and functions very well with OLTP systems and very poorly for reporting. This is one reason why Java application driven Oracle database designs often result in two databases, the first an OLTP database and the second a data warehouse. The data warehouse database takes care of the reporting and contains all the alternate and composite indexing required for reporting. The only likely composite indexes sometimes in existence in OLTP object-like relational databases are the primary keys of many-to-many join resolution entities, something like the Actor entity in Figure 2.6.
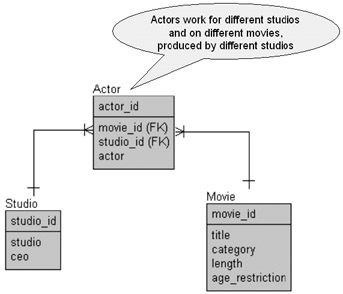
Figure 2.6: An Object-Like Many-to-Many Join Resolution Entity
Figure 2.7 contains an equivalent traditional, non-object-like representation of the schema snippet shown in Figure 2.6.
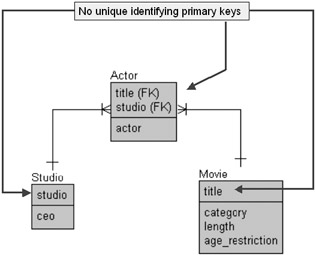
Figure 2.7: A Traditional Relational Version of Figure 2.6
The sheer scale and size of OLTP Internet databases can sometimes be horrifying to even the most seasoned of database administrators. Many hundreds of gigabytes are common and when OLTP and reporting processing is mixed in the same database. Enormous amounts of money can be spent on very expensive hardware to maintain performance at a level acceptable to customer satisfaction. Additionally, Development cannot possibly be coded and tested against databases of such magnitude. The result is often applications that are coded to small-scale databases and unexpected if not disappointing performance in production. Extensive tuning is often required. The larger the database the more likely that a dual database architecture has to be adopted, of OLTP plus data warehouse architecture.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 164