Location and the Information Perimeter
| < Day Day Up > |
| Location tells where the data that comprises information is. This helps to determine whether information is where it is expected to be or whether there is more than one copy of the data. Many ILM decisions will be based on location of the underlying data. Location helps determine the integrity of information. It is essential for managing multiple copies of the same information across an enterprise. Information PathOn one hand, location is a concrete element of information. Classification and state can be subjective. Location is, instead, physical and tangible. The problem is that file systems and structured data stores have different ways of expressing location. The manner in which a UNIX operating system describes where data is differs from the way in which the Windows family of operating systems does. Data stored on a network introduces additional ways to depict where data is. This can make location statements in ILM policies very difficult. Instead, it is more useful to use a virtual location that can be mapped to a real location. Called the information path, it is a way of describing where information is without subscribing to specific operating system nomenclature. The information path should include at least the following:
The network path should be a virtual path not a physical address. When combined with the hostname, a general data storage location can then be given as a virtual address. The file system name or application name is needed to accommodate structured and unstructured information. An application in this case is likely to be a structured data storage application, such as the name of a database. The local object name provides the unique identifier for the information, and the component names provide an additional level of identification if the ILM policy calls for it. The addition of a version identifier supports the ability to have information paths point to different versions of the same data. The information path could then be the same for multiple versions of the same information except for the version. Differences in these paths would point to different data, but the information would be the same. Information paths could look something like this: Techalignment.com: Spiderman: Oracle: Order_db: Order:Row 456: 1.02 Hightech_Net1: File_Server1: Window XP 2003: Big_company_contract.doc: 2.0 Local: myDesktop: eBooks: Adobe Acrobat: Data Protection Book: first edition The same information could have multiple information paths. If that sounds like being in more than one place at the same time, that's because it is. Multiple copies of the information are still the same information. This is critical to maintaining the integrity of information. For ILM policies to be carried out correctly, all copies of information must have the same rules applied to them at the same time. A copy is the same information, only in an additional location.
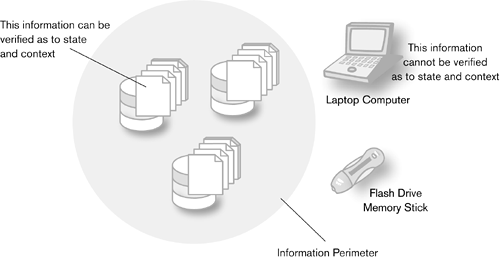
Information PerimeterWhen information is in certain locations on a laptop or home computer, for example the information cannot be verified as to whether changes in state have occurred. It is beyond the control of systems and monitoring. Subsequently, state changes to the information cannot be tracked. The boundary between where an ILM policy can expect to have control and where it cannot is called the information perimeter (Figure 8-3). Information stored beyond the information perimeter cannot be verified as to state, context, or even existence. Figure 8-3. The information perimeter
The information perimeter defines
Information Lifecycle Management policies must address what happens when information crosses the information perimeter. Specifically, there need to be procedures for deciding whether information that is outside the information perimeter is considered to be valid. |
| < Day Day Up > |
EAN: 2147483647
Pages: 122