Hack 73. Mix File and Database Storage


Just because you can store files in a database does not mean you should.
On sites that generate dynamic web content, storing everything (even things such as files) in the database can sound attractive. It would give a single metaphor for accessing data. It also offers a simple interface that is free from locking and reliability worries. Databases give you useful features, such as error recovery and transactions. If you use files to store data you have to write code to protect the files yourself. So, having files in the database as well should save you from writing lots of code.
There is a problem, however. Although database systems do support large pieces of data, such as pictures and binary application files, they tend to slow down the database queries. These data items are often big, so transferring them from the database is time consuming. They are implemented using special type definitions, such as BLOB and CLOB, and these store the data on disk using a different algorithm from that used for normal data. This can make retrieval and searching slower. Database backups are much slower due to the huge size of the data set.
Consider the problem of having pictures on your web site. If you had them in the database, you would receive a request for each picture present on a page. Each request would open a database connection, and return the picture and the right MIME type to the requesting browser. It would be much easier just to have a directory of pictures and let the web server handle the pictures itself. You can see this approach in "Store Images in a Database" [Hack #46].
One approach to mixed data requirements is to use the database to store only things which SQL can actually query. Currently images cannot be queried with questions such as WHERE image LIKE 'a red boat' (but people are working on this). Images in a database do give good version control capabilities, but you don't actually need to store images in a database to allow the database to look after your image versioning. You can, after all, store an image filename in a database and have a similar effect.
You should still use a database for large-file storage if the access and modification pattern has many serialization issues, and it is therefore too risky to do your updates with simple files.
9.10.1. Adding and Removing Files
Suppose you need to store and retrieve files as part of a software repository application. You have decided not to use a 100 percent database solution, and you want to store binaries as files in the filesystem. You could use a structure such as that shown in Table 9-5.
| User | App name | Lastmod | Filename | Version |
|---|---|---|---|---|
| Gordon | Firebox | 2007-03-01 | 50 | 1 |
| Gordon | Firebox | 2007-03-02 | 51 | 2 |
| Andrew | Firebox | 2007-03-01 | 52 | 3 |
User Gordon wants to upload a new version of Firebox to the repository. You must reserve a filename for the new file, even though the upload has not yet completed. You can do this in a single SQL statement:
INSERT INTO filelist SELECT 'Gordon','Firebox',CURRENT_DATE,MAX(filename)+1,0 FROM filelist;
You can find the new filename with this query:
SELECT filename FROM filelist WHERE user='Gordon' AND version=0
Once the upload has completed, you run this:
UPDATE filelist SET version=(SELECT MAX(version)+1 FROM filelist WHERE user='gordon' AND appname='Firebox') WHERE user='gordon' AND version=0;
You have to do a little housekeeping yourself with this approach. Sometimes uploads will fail, so every day, run this:
SELECT filename FROM filelist WHERE lastmod<(sysdate( )-1) AND version = 0;
Any filenames returned can be assumed to have been involved with partial uploads which have failed, and you could write a script to run over that list and delete the files involved. Once all the file deletions have completed, delete the row from the database.
By using this approach you can store files in a directory, but never have orphaned files in the filesystem. Because you have used single SQL statements there should be no problems with race conditions, unless an individual attempts to upload two files at the same time. If that is a risk you can extend the filelist table with a session ID.
9.10.2. Too Many Files
As the number of files grows, the directory listing for the directory that stores the files grows too. Soon commands will start to complain that the command line is too long, commands will take a long time to find the file in question, and library routines may start to die. Not every operating system likes having 100,000 files in a directory.
The solution is to hash the filename and use that value for a subdirectory name. A simple hashing algorithm example would take the first character of the filename. Keeping with the numeric filenames from the previous example, Figure 9-5 shows a possible layout for these.
Figure 9-5. Hash directory structure
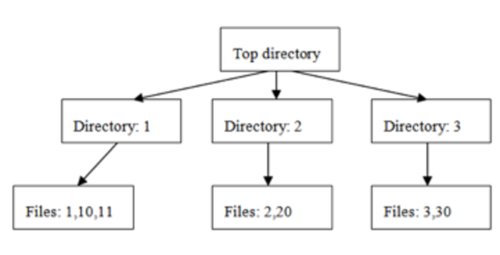
In this structure example, there are only three subdirectories and no sub-subdirectories. All the files and directories can still be listed with normal commands. In Linux, Unix, and Mac OS X (and on Windows using Cygwin), if you really want all the files for one operation, you can use find.
A function for this kind of storage scheme would look like this:
sub hashname {
my ($filename) = @_;
my @level;
if ($filename =~ /^(.)/) {
return "$1/$filename";
}
}
In this case, hashname('12650') would return the string 1/12650, which can be used as the relative pathname and filename for the file 12650.
|
9.10.3. Hacking the Hack
Creating and deleting files using this mechanism is not difficult. But changing a file that already exists will present you with a load of potential problems. You need to think carefully before continuing with a file-based approach. Database systems provide locking, transactions, and reliability, all for free. It is not wise to try to write even a basic transaction system so that you can use simple files. You will end up implementing your own database systems, and there are already enough database systems in the world.
However, if you can guarantee that you will be appending only to the end of the files, you are in luck because you can do this easily and without significant data risks, all without touching the database.
Suppose you have a program which monitors network activity, and when it detects a packet it uses the database to work out which user that packet belongs to. It then appends the packet information to the end of the packet log for that user. A packet log for a single user can quickly grow to 100 MB in size, and you have 2,000 users, so things can get big fast.
You had implemented this using a database-only solution, but now the database is huge and hard to back up. This is doubly a pity because if you lose your database it will be a disaster, but if you lose the packet logs it will be only an annoyance. You can use files to help. In this case, you use the techniques shown earlier in this hack to use a number for the filename, and a hash structure for the directories. All you need is a routine to open the file in append mode, shown here in Perl:
#!/usr/bin/perl
use Fcntl qw(:DEFAULT :flock);
sub openlog {
my ($filename) = @_;
my $handle;
my $name = hashname($filename);
if ($name =~ m/^([^/])//) {
mkdir $1 if (! -d $1);
}
sysopen($handle,$name,O_WRONLY|O_APPEND|O_CREAT) || return;
flock($handle,LOCK_EX);
return $handle;
}
my $filename = '25640';
my $file = openlog($filename);
if ($file) {
print $file "
". "Packet 56 arrived from 10.0.0.10";
close $file;
}
There is a slight possibility that a problem or error could cause a partial write to occur in another program running this append routine, so you should always put the newline ( ) at the start of your output rather than at the end. In this way, partial writes damage only the lines they were writing, not your file.
Remember that if you want to read from this file, you should do a flock with LOCK_SH before reading. If you forget, it probably won't matter, but there is the possibility of reading a write which has not yet completed, which could lead to reading partial data.
SQL Fundamentals
- SQL Fundamentals
- Hack 1. Run SQL from the Command Line
- Hack 2. Connect to SQL from a Program
- Hack 3. Perform Conditional INSERTs
- Hack 4. UPDATE the Database
- Hack 5. Solve a Crossword Puzzle Using SQL
- Hack 6. Dont Perform the Same Calculation Over and Over
Joins, Unions, and Views
- Joins, Unions, and Views
- Hack 7. Modify a Schema Without Breaking Existing Queries
- Hack 8. Filter Rows and Columns
- Hack 9. Filter on Indexed Columns
- Hack 10. Convert Subqueries to JOINs
- Hack 11. Convert Aggregate Subqueries to JOINs
- Hack 12. Simplify Complicated Updates
- Hack 13. Choose the Right Join Style for Your Relationships
- Hack 14. Generate Combinations
Text Handling
- Text Handling
- Hack 15. Search for Keywords Without LIKE
- Hack 16. Search for a String Across Columns
- Hack 17. Solve Anagrams
- Hack 18. Sort Your Email
Date Handling
- Date Handling
- Hack 19. Convert Strings to Dates
- Hack 20. Uncover Trends in Your Data
- Hack 21. Report on Any Date Criteria
- Hack 22. Generate Quarterly Reports
- Hack 23. Second Tuesday of the Month
Number Crunching
- Number Crunching
- Hack 24. Multiply Across a Result Set
- Hack 25. Keep a Running Total
- Hack 26. Include the Rows Your JOIN Forgot
- Hack 27. Identify Overlapping Ranges
- Hack 28. Avoid Dividing by Zero
- Hack 29. Other Ways to COUNT
- Hack 30. Calculate the Maximum of Two Fields
- Hack 31. Disaggregate a COUNT
- Hack 32. Cope with Rounding Errors
- Hack 33. Get Values and Subtotals in One Shot
- Hack 34. Calculate the Median
- Hack 35. Tally Results into a Chart
- Hack 36. Calculate the Distance Between GPS Locations
- Hack 37. Reconcile Invoices and Remittances
- Hack 38. Find Transposition Errors
- Hack 39. Apply a Progressive Tax
- Hack 40. Calculate Rank
Online Applications
- Online Applications
- Hack 41. Copy Web Pages into a Table
- Hack 42. Present Data Graphically Using SVG
- Hack 43. Add Navigation Features to Web Applications
- Hack 44. Tunnel into MySQL from Microsoft Access
- Hack 45. Process Web Server Logs
- Hack 46. Store Images in a Database
- Hack 47. Exploit an SQL Injection Vulnerability
- Hack 48. Prevent an SQL Injection Attack
Organizing Data
- Organizing Data
- Hack 49. Keep Track of Infrequently Changing Values
- Hack 50. Combine Tables Containing Different Data
- Hack 51. Display Rows As Columns
- Hack 52. Display Columns As Rows
- Hack 53. Clean Inconsistent Records
- Hack 54. Denormalize Your Tables
- Hack 55. Import Someone Elses Data
- Hack 56. Play Matchmaker
- Hack 57. Generate Unique Sequential Numbers
Storing Small Amounts of Data
- Storing Small Amounts of Data
- Hack 58. Store Parameters in the Database
- Hack 59. Define Personalized Parameters
- Hack 60. Create a List of Personalized Parameters
- Hack 61. Set Security Based on Rows
- Hack 62. Issue Queries Without Using a Table
- Hack 63. Generate Rows Without Tables
Locking and Performance
- Locking and Performance
- Hack 64. Determine Your Isolation Level
- Hack 65. Use Pessimistic Locking
- Hack 66. Use Optimistic Locking
- Hack 67. Lock Implicitly Within Transactions
- Hack 68. Cope with Unexpected Redo
- Hack 69. Execute Functions in the Database
- Hack 70. Combine Your Queries
- Hack 71. Extract Lots of Rows
- Hack 72. Extract a Subset of the Results
- Hack 73. Mix File and Database Storage
- Hack 74. Compare and Synchronize Tables
- Hack 75. Minimize Bandwidth in One-to-Many Joins
- Hack 76. Compress to Avoid LOBs
Reporting
- Reporting
- Hack 77. Fill in Missing Values in a Pivot Table
- Hack 78. Break It Down by Range
- Hack 79. Identify Updates Uniquely
- Hack 80. Play Six Degrees of Kevin Bacon
- Hack 81. Build Decision Tables
- Hack 82. Generate Sequential or Missing Data
- Hack 83. Find the Top n in Each Group
- Hack 84. Store Comma-Delimited Lists in a Column
- Hack 85. Traverse a Simple Tree
- Hack 86. Set Up Queuing in the Database
- Hack 87. Generate a Calendar
- Hack 88. Test Two Values from a Subquery
- Hack 89. Choose Any Three of Five
Users and Administration
- Users and Administration
- Hack 90. Implement Application-Level Accounts
- Hack 91. Export and Import Table Definitions
- Hack 92. Deploy Applications
- Hack 93. Auto-Create Database Users
- Hack 94. Create Users and Administrators
- Hack 95. Issue Automatic Updates
- Hack 96. Create an Audit Trail
Wider Access
- Wider Access
- Sharing Data Across the Internet
- Hack 97. Allow an Anonymous Account
- Hack 98. Find and Stop Long-Running Queries
- Hack 99. Dont Run Out of Disk Space
- Hack 100. Run SQL from a Web Page
Index
EAN: 2147483647
Pages: 147
