Creating and Defining Databases
| The first object to be concerned with is the database itself. Creating a database from the SQL Server Management Studio is a simple task. In most cases, all you need to do is provide a name for the database and then click OK. When initializing a database, you should also think about the location of the data and log files. Other than that, initial database creation is somewhat lackluster, particularly if you have a well-configured logical data model. In the default database creation process, you see a list of the properties present in the model system database. The model is essentially a template database for each new database created. It is a good idea to review the properties of the model database; you will likely want to change the recovery model option to Full so that every database created is set up for full recovery. As you create databases and other objects, information about the objects is maintained inside the master database. The master database contains a set of system tables that track most of the objects on the server. Objects not stored in the master pertain to the automation objects that fall under the control of the SQL Server Agent. The automation objects controlled by the SQL Server Agent are maintained instead in the msdb database. On the 70-431 exam, the database itself is considered a moot point. It exists, and it has predictable settings, but the exam includes no questions that involve creation of a database over and above the default scenario. It is worth looking at the CREATE and ALTER DATABASE statements, however, because they are used to create and alter most objects. Using T-SQL to Create and Alter a DatabaseThe T-SQL CREATE DATABASE statement allows for the creation of a new database and the files used to store the database. A database can also be created by attaching a database to the server from the files of a previously created database. The CREATE statement is also used to create a database snapshot. After you create a database, you can use the ALTER DATABASE statement to modify it. You can make changes to the files and filegroups associated with the database, add or remove files and filegroups, change the attributes of the database or its files and filegroups, change the database collation, and set any of the database options. Note In previous releases of SQL Server, you could use sp_dboption to programmatically set any of the database options. The sp_dboption stored procedure will be removed in a future version of Microsoft SQL Server. You should therefore use ALTER DATABASE to set any of the options previously set through sp_dboption. To retrieve current settings for database options, you use the sys.databases catalog view within a standard query. The sp_dboption stored procedure is still available and can be used for immediate information in this release. If desired, you can run sp_dboption as a query from SQL Server Management Studio, but sp_dboption is not recommended for any coded solution. The Makeup of a DatabaseA database is made up of a variety of objects and information. The data is stored in files in a manner that allows the database engine to access the objects and information in an effective manner. Often, the database is thought of as a container for data and nothing more. However, the purpose of a database is to support applications. To this end, a variety of objects provide useful functionality to these applications, as described in this chapter. You can use the SQL Server Management Studio to quickly view all the objects associated with a database. The Database Diagram tool and the objects it creates allow you to quickly display a group of tables and their properties and to print out the information. For documentation purposes, however, this tool significantly lacks features that database designers use, such as logical data modeling and data dictionary development. The remaining objects are far more useful than the diagram objects, and they support the database. By opening the tree, as shown in Figure 2.1, you can get a quick glance at the various objects that SQL Server uses. Figure 2.1. A database object tree within SQL Server Management Studio.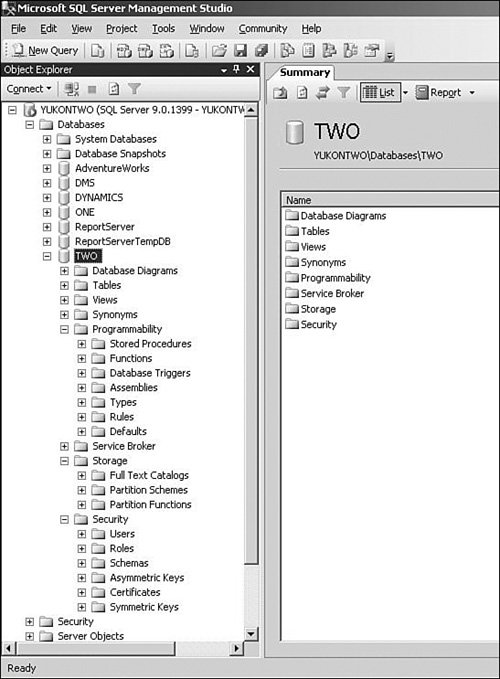 From a data perspective, the main object that the database maintains is the table, an object consisting of rows and columns that is used to store data. The columns represent an attribute, and the rows represent a set of attributes for one distinct occurrence of the data item. A table contains or is directly associated with a set of objects of its own. We look more closely at tables and their related objects later in this chapter, in the section "Defining SQL Server Tables." SQL tables act as the actual data stores within the database environment. A view is a virtual table whose information is defined by an SQL query. Defined as a virtual table, a view does not normally hold any data itself. Like a table, a view is a set of columns and rows. But the data for the view is stored in the underlying tables of the database. Unless it is indexed, a view does not store data values. Views are versatile and can be used in many situations where a table is used. Standard Views, Indexed Views, and Partitioned ViewsA view can be a simple SQL query that filters the number of columns and rows in a single table to provide a more meaningful and useful display of the data. A standard view can be a little more complex and combine multiple tables in JOIN relationships or UNION relationships. In this respect, the complexity of displaying information can be hidden from the user, and the appearance of a singular set of records simplifies information handling. The standard view is a powerful tool. It can be used in place of a table for most data query operations. Through horizontal and vertical filtering, it helps improve performance and efficiency by limiting the data sent across the network. It can efficiently process and organize data on the server to then be sent to reporting applications at the client for attractive display. Views provide many benefits and are therefore common throughout an enterprise database environment. The number-one reason a view is created is to protect data from inquisitive eyes. This means that the developer has to worry only about allowing access to the view and further restricting the rows that are returned. Views provide many other benefits as well, including the following:
A standard view can also make data import and export more easy to perform. Selecting just the correct data in the correct sequence and then putting the data into a form that is ready to use can be very helpful. Spreadsheets, accounting packages, and interactive websites can all make use of data that is quickly exported into other formats through the use of views. Note Views that produce aggregated data (for example, SUM, COUNT, MAX), use four or more tables in join operations, contain subquery operations, perform complex calculations, or operate through cascading table relationships can produce a significant amount of overhead. Beyond the standard view lie some interesting tangents that you can implement to improve performance and capacity within a database. A standard view can be a significant amount of processing overhead due to the production of aggregates, the joining of data, or other hierarchical table issues. There may be a more efficient method of performing a view than dynamically building the data every time the view is called. In views that are frequently used by the application accessing the data, you can often improve performance by storing data within a standard view and creating an indexed view. Using Indexed ViewsIndexed views can help improve performance in systems where views are frequently used to return large amounts of data. To create an indexed view, you can add a unique clustered index on the view. In this style of view, the data is stored within the database, just like a table. Because the data no longer has to be dynamically prepared when the view is executed, performance is drastically improved. Indexed views are best applied in situations in which data is infrequently updated. As data in the underlying tables changes, SQL Server must update the correlating data within the indexed view. If the data is changed often, the maintenance cost of the view may outweigh any performance gain. When an indexed view is created, the SQL Server Query Optimizer can make use of its existence. If the Query Optimizer recognizes that the data to resolve a query is contained within the view, it might deem it more efficient to pull data from the view than to pull it directly from the tables. The Query Optimizer can perform these activities even when the view is not directly referred to in the query. A considerable number of settings must be in place to implement indexed views:
To configure these settings, you use a SET command, specify the option that you are setting, and specify the setting state as either ON or OFF, as in the following example: SET ANSI_NULLS ON Exam Alert There are many restrictions in terms of what elements cannot be used in an indexed view. You might want to read more about the use of indexed views, but other than those on the basic designs and use of indexed views, there are not a lot of questions on the 70-431 exam about the setup and coding of views. You need to know the options for creation, how to use SCHEMABINDING, and advantages and disadvantages of the use of indexed views. You can use the SCHEMABINDING clause when creating a view to create a relationship between the view and the underlying tables. When binding is in place, you cannot alter any object that is bound to the view. Let's look at an example of creating an indexed view. First, you need to create a database to use as an example: USE MASTER GO CREATE DATABASE ONE GO You must set the environment options for the table, view, and index to use. The following example uses the previously created database and creates a table, view, and associated index on the view: USE ONE GO SET ANSI_NULLS On SET QUOTED_IDENTIFIER On SET ANSI_PADDING On SET ANSI_WARNINGS On SET CONCAT_NULL_YIELDS_NULL On SET NUMERIC_ROUNDABORT Off GO CREATE TABLE dbo.GLAccts( ActIndex int NOT NULL, ActNumber_1 char(9) NOT NULL, ActNumber_2 char(9) NOT NULL, ActNumber_3 char(9) NOT NULL, ActAlias char(21) NOT NULL, ActType smallint NOT NULL, ActDesc char(51) NOT NULL, ROW_ID int IDENTITY(1,1) NOT NULL, CONSTRAINT PKGL00100 PRIMARY KEY NONCLUSTERED(ActIndex ASC) WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] GO CREATE VIEW dbo.v_AccountList WITH SCHEMABINDING AS SELECT ActNumber_1, ActNumber_2, ActNumber_3, ActDesc FROM dbo.GLAccts GO CREATE UNIQUE CLUSTERED INDEX i_AList ON v_AccountList(ActNumber_1, ActNumber_2, ActNumber_3) GO Note that when you are creating a view, you use the SCHEMABINDING clause to create a relationship between the view and the underlying tables. With binding, a view or function is connected to the underlying objects. Any attempt to change or remove the objects fails unless the binding has first been removed. Once the SCHEMABINDING clause is in place, you cannot alter any object that is bound to the view. In this example, you would be able to add a column to the table, delete a column not related to the view, or change any of the columns not contained in the view. You cannot make changes to four field definitions (ActNumber_1, ActNumber_2, ActNumber_3, and ActDesc) unless you first drop the view. After you complete the creation, you should check your results in SQL Server Management Studio. Figure 2.2 illustrates what the Object Explorer would now show for the ONE database. Figure 2.2. The ONE database object tree, showing Table, View, and Index attached to View. You do not necessarily use the SCHEMABINDING clause only for indexed views. You can use it any time you want to attach an underlying table definition to a view or user-defined function. When you use it, however, it significantly changes the functionality. Using Partitioned ViewsA partitioned view can span a number of physical machines. Partitioned views fall into two categories:
A distinction is also made between views that are updatable and those that are read-only. The use of partitioned views can aid in the implementation of federated database servers, which are multiple machines set up to share the processing load. With federated server implementations, multiple server operations balance the load so that updates are potentially separated from queries and so query load can be spread across multiple machines. Federated servers are beyond the scope of the exam and therefore this book as well. However, for more information on federated server implementations, see SQL Server Books Online, "Designing Federated Database Servers." Partitioned views drastically restrict the underlying table designs and require several options to be set when indexes are used. Constraints need to be defined on each participating server so that only the data pertaining to the table(s) stored on that server is handled. To use partitioned views, you horizontally split a single table into several smaller tables, and you make sure each has the same column definitions. You set up the smaller tables to accept data in ranges. You can enforce the data entry into each ranged server by using constraints. Although constraints are not needed to return the correct results, they enable the Query Optimizer to more appropriately select the correct server to find the requested data. Then you can define the distributed view on each of the participating servers. To do so, you add linked server definitions on each of the member servers. The following is an example of a distributed view definition: CREATE VIEW AllProducts AS Select * FROM Server1.dbo.Products9999 UNION ALL Select * FROM Server2.dbo.Products19999 UNION ALL Select * FROM Server3.dbo.Products29999 Partitioning attempts to achieve a balance among the machines being used. Data partitioning, as mentioned previously, involves the horizontal division of a single table into a number of smaller tables, each dealing with a range of data from the original and split off onto separate servers. Attempting to ensure that the correct query goes to the appropriate server also helps to improve performance while minimizing bandwidth use. Designing for partitioned views requires appropriate planning of front-end applications to ensure that, whenever possible, data queries are sent to the appropriate server. Middleware, such as Microsoft Message Queue or an application server or other third-party equivalents, should attempt to match queries against data storage. When preparing for data communication with the front-end application, the operating system settings of the server affect the server's interaction with the application. Miscellaneous SQL Server ObjectsA number of SQL Server objects not discussed so far are also important: tables, the Service Broker, programmability, and security objects. Each of these topics is very hefty in its own right. These topics are therefore broken into their own sections in the remainder of the chapter. As you peruse a database using the Object Explorer in SQL Server Management Studio, you might notice a few objects that are new to SQL Server. Many of the objects are not tested on the 70-431 exam. To be thorough, however, this chapter does discuss them. Although these objects may provide some useful functionality, you are unlikely to find them on the exam:
|

EAN: 2147483647
Pages: 200