6.1. The Hardware Generation Flow When your application is processed by the Impulse C compiler, a series of steps are performed, some of which are dependent on the platform target you have selected. Figure 6-1 illustrates the design flow, beginning with C source files representing the hardware and software elements of the application. Figure 6-1. The C-to-hardware generation flow. 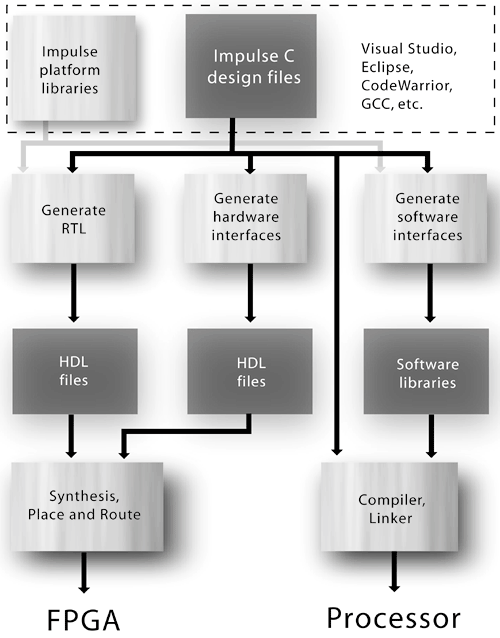
In this flow, design entry and initial desktop simulation and debugging are performed using common C development tools such as Visual Studio or gcc and gdb. The Impulse libraries provide the needed functions (as described in the preceding chapters) for software emulation of parallel processing. Once an application has been developed and simulated in the context of standard C programming tools, it can then be targeted to a specific platform and compiled into hardware and software binary files. For software functions (those that will be compiled to an embedded processor, for example) the process is relatively straightforward and uses standard cross-compiler tools in conjunction with platform-specific runtime libraries provided with the Impulse compiler. The hardware generation process is somewhat more complex and is summarized in the next section. Optimization and Hardware Generation Those portions of an Impulse C application that are intended for hardware (as specified using the co_process_config function) are analyzed by the RTL generator and optimized using a series of compiler passes. The optimization and hardware generation passes are summarized here and in Figure 6-2: C preprocessing. As in a traditional C compiler flow, the first step is a preprocessing pass that incorporates such things as include file references, macro expansion, and the like. If you have taken advantage of the preprocessor's #ifdef features, this is where C (or C++) statements that are related only to desktop simulation might be removed. C analysis. This compiler step is where, for example, the hardware and software processes of your application are identified. Specifically, this is where your application's co_initialize and configuration functions are examined to determine which processes you have configured as hardware processes, as defined by your use of the co_process_config function. Streams, signals, shared memories, and related elements are also identified here in preparation for hardware generation and for the generation of any needed hardware/software interfaces. Initial optimization. This phase performs various common optimizations on your hardware processes. (Software processes are not optimized or compiled at this point because they are processed later by a standard compiler environment for the target microprocessor.) Optimizations performed at this point might include constant folding, dead code elimination, and other such techniques. Certain compiler preoptimizations in support of later parallel optimizer passes are also performed at this point. Loop unrolling. This phase finds any uses of the UNROLL pragma and performs a corresponding expansion of loops into equivalent (typically larger) parallel statements. If the UNROLL pragma has been used on a loop that cannot be unrolled (for example, one with a nonstatic termination count), an error is generated. Instruction stage optimization. In this pass, a number of important optimizations are performed in order to extract parallelism at the level of individual C statements and at the level of blocks of statements. For example, two or more statements that appear in sequence but that have no interdependencies might be collapsed into a single clock cycle. Additionally, this optimizer pass performs loop pipelining if such pipelining has been requested via the PIPELINE pragma. Hardware generation. In this pass, the optimized and parallelized code is translated into equivalent hardware descriptions, resulting in a set of synthesizable (and simulatable) HDL files. These files contain descriptions of each hardware process, as well as references to the required stream, signal, and memory components. These latter components are referenced from a hardware library provided for a specific FPGA target.
Figure 6-2. The C-to-hardware optimization and generation steps. 
For software processes, the compiler simply copies the relevant C source files to a location (typically a subdirectory of your project) and generates one or more related C and/or assembly language files that define the software-to-hardware interfaces, which are typically memory-mapped I/O routines. This flow can change slightly for certain types of platforms, but it is representative of the work that is done by the compiler in preparing a C application (one consisting of both hardware and software elements) for mapping onto a programmable platform. It is important to understand, however, that more needs to happen before you can run your code on the FPGA target. These additional steps include the following: - Logic synthesis and FPGA technology mapping. This is performed by the FPGA synthesis software provided by your FPGA vendor-supplied tools, or using third-party synthesis tools as appropriate. During this process, the hardware descriptions generated in the steps just described are further optimized (for example, to take advantage of FPGA-specific features such as multipliers and other "hard macros") to create an FPGA netlist, which is typically in EDIF format. (It should be noted here that some C-to-hardware design flows bypass this step and compile C code directly to EDIF netlists. This can provide the user and/or the optimizer with more opportunities for low-level hardware control.)
- FPGA place-and-route. In this step, the FPGA netlist created in the previous step is analyzed, and its many component references (which represent such things as registers and gate-level logic, as well as references to higher-level FPGA macros), are assigned to locations in the FPGA. The result of this step is an FPGA bitmap that can be downloaded to the device via a JTAG or other interface.
Due to the size of modern FPGAs, the complexity of the interconnect structures, and the need to decompose the logic into elements suitable for the particular structure of the FPGA, the preceding two steps can take many minutes, or even hours, to complete. These steps take even longer if it is necessary to synthesize, place, and route other elements of the design, such as an embedded soft processor and its peripherals, in order to map the complete design to hardware. For this reason it can be helpful to make use of hardware simulators (when practical) and verify the results of hardware generation at the level of the HDL files generated by the C compiler passes. Doing so can provide a much faster design and debug experience. We'll provide an example of hardware simulation a bit later in this chapter. |