3.3 Moving and Restructuring Data
|
|
3.3 Moving and Restructuring Data
Inaccurate data is often created from perfectly good data through the processes used to move and restructure data. These processes are commonly used to extract data from operational databases and put it into data warehouses, data marts, or operational data stores. It may also restage the data for access through corporate portals. This is an area often overlooked as a source of data inaccuracies and yet it contributes significantly to the inaccuracy problem. When you hear complaints that the data in a data warehouse or data mart is wrong and unusable, a major contributing factor might be flawed data movement processes as opposed to the data being inaccurate in the source databases.
Moving and restructuring data is commonly done through ETL (extract, transform, and load) processes. There may also be data scrubbing processes involved. Sometimes this is performed through packaged tools and sometimes through in-house-developed scripts or programs. When packaged tools are used, the errors are not coming from them but rather from faulty specifications used for them.
Entire classes of tools and software companies emerged to support this activity. The two primary tool categories are ETL and data cleansing. What was missing was tools to help understand the data in enough detail to effectively use the tools and to design decision support systems correctly. The recent emergence of data profiling tools is intended to fill this gap and is showing dramatically positive effects when used.
The irony of it is that most projects claim to be extracting the data and cleaning it up before it is moved into the data warehouses, when in fact they are making it dirtier, not cleaner. Data is generated and stored in a database based on the initiating application. This is generally a transaction system that collects the data and performs updates. The database is generally designed to meet the requirements of the initiating application and nothing more. The design of the data and the database is generally poorly documented and almost always not kept up to date.
There are also a host of other reasons for moving data to a database of a different structure. These include migration of applications to newer technology or to packaged applications. For many applications, this may be the first time they have been subject to a major reengineering effort. Another reason is the need to consolidate databases. Consolidations occur for two reasons: corporation mergers and acquisitions, and the need to centralize databases from local or divisional databases.
An important fact of migrations and consolidations is that you cannot leave the old data behind. Most databases require a continuity of information over long periods of time. You cannot move to a new personnel system and not move the existing personnel information behind. You cannot move to a new supply chain system and not move the inventory or the inventory history data. Figure 3.3 lists projects for which database restructure and/or data movement should be a serious consideration.

Figure 3.3: List of projects that require restructuring and movement of data.
There are two major problems frequently found in moving and restructuring data. The first is that to effectively accomplish the movement of the data to another database you have to fully understand everything about the source database (and the target, if it is not a new database). The reality is nothing close to this. The other problem is that the source systems were never designed with the thought of having to give up their data to another database. This is particularly the case for a database of a different type, designed very differently and combining it with data from other sources.
The software industry supported moving and restructuring data by creating two disjointed types of products: ETL products and data cleansing products.
ETL products provide support for extracting data from source systems, transforming values in the data, aggregating data, and producing suitable load files for target systems.
Data cleansing companies provide support for processing selective data fields to standardize values, find errors, and make corrections through external correlation. Their target has been primarily name and address field data, which easily lends itself to this process. It has also been found to be usable on some other types of data.
In spite of very good software from these companies, a lot of data inaccuracies filter through the process and a lot of new inaccuracies are generated. None of this is the fault of the products from these companies. They all execute as advertised. The problem is that they will not work correctly unless accurate specifications of the source data and the work to be done are entered. The problem is that the tools cannot help if they are fed inaccurate or incomplete specifications.
This has led to the emergence of a third product type: data profiling products. Data profiling is intended to complete or correct the metadata about source systems. It is also used to map systems together correctly. The information developed in profiling becomes the specification information that is needed by ETL and data cleansing products. This relationship is shown in Figure 3.4 at the end of this chapter.
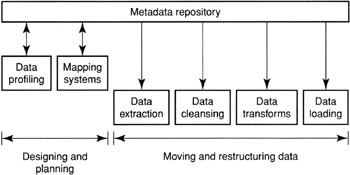
Figure 3.4: Steps in the data movement process.
Understanding Source Databases
Rarely do you have current, complete information available on transaction systems. Metadata dictionaries and repositories generally have very low accuracy. Even COBOL copybooks sport a high degree of mismatch between what they say and how the data is actually stored.
The poor attention paid to creating and maintaining accurate data in data dictionaries and metadata repositories is now hurting corporations to the tune of millions of dollars in unnecessarily complex data movement projects and/or in having to accept low-quality data (data that is even of lower quality than the source databases it is extracted from) for use in decision making.
The reasons for poor data quality in metadata repositories are many. Repository technology has lagged behind database design evolution. Repository solutions are generally insufficient in content to collect all the needed information. They are passive, which means that they can get out of step with the data without noticeable impacts on normal operations. There has been little motivation on the part of data administration staff to keep them current.
COBOL copybooks also become inaccurate over time. Changes to fields are often done without updating the copybook. A character field may be reassigned to be used for an entirely different purpose. If the physical definition of the field satisfies the new use, the copybook change is not needed to make the program work. This results in the field name and comment text referring to the old meaning and not the new meaning. This can, and will, mislead anyone using it to make changes or to extract data.
In many instances, valuable application information was found stored in the space defined to COBOL as FILLER. This is a common and quick-fix way of implementing a change and of completely bypassing an update of the copybook or any other documentation that may exist.
Overloaded Fields
Older, legacy applications are filled with "overloaded" fields. An overloaded field is one that has information about multiple, different facts stored in the same field.
An example of an overloaded field is where a mainframe application developer needs a new field that has a binary representation such as YES or NO. They do not want to waste the space for a new field (a common concern for developers in the 1960 to 1980 time frame). Instead of creating a new field, they decide to use an unused bit of another, existing field. This could be one of the spare bits within packed decimal fields for IBM mainframes or the sign bit of a numeric field that can never be negative. The result is an overloaded field. Other examples of overloaded fields are to use each bit of a single byte to represent the value for a different binary-valued field or to use free-form text fields to encode keywords that mean different things.
An extreme case discovered in one system was that a person's NAME field had the characters *DECEASED appended to it within the same NAME field if the person was dead. So, for example, the value Jack Olson meant who I am and that I am alive, whereas the value Jack Olson *DECEASED meant who I am and that I am not alive.
The problem with overloaded fields is that they are generally never documented. The copybook definitions and dictionary definitions usually document only the underlying field or, in the case of multivalued keyword fields, document it only as a text field.
Analysts designing data movement and restructuring processes often do not become aware of the overloading and either incorrectly transform and move the data or reject some or all of the values in the field as being inaccurate. In the process of rejection, they are losing correct information on each of the separate facts recorded in the field.
Another real example of overloading fields is where a legacy system developer used the sign bit on the PAY_RATE field to represent a different fact because this field should never be negative. Neither this convention nor the meaning of the bit was ever documented. When they upgraded to a new packaged application for payroll, they moved the field as it existed, innocently thinking that they did not need to investigate such an obvious field. When they ran their first payroll, 30% of the checks had negative amounts. This is an example of a situation in which you absolutely must verify the content of every field against your expectations when you lift it out of one system and place it into another.
Sometimes the information needed about existing databases is not recorded anywhere. You often need detailed information on missing or exception conditions. This is often not available. You also need information on accuracy. This is never recorded anywhere.
Matching Source Databases to Target Databases
This is tricky business. You first need to have a total understanding of both systems. You then need to match data elements to determine whether the result makes sense.
In matching data elements you are saying that a particular field in the source system contains the content you need to put into a particular field in the target system. Many times this is an obvious match, such as a PAYTYPE field in one system and a PAY_TYPE field in the other system. However, when you get below the surface, differences can emerge that are highly significant and can create enormous problems if not addressed. The types of problems that can occur are
-
The actual representation of the values within the field may differ. One system, for example, may encode PAY_TYPE as H and S for hourly and salaried. The other may encode the same information as 1 and 2. You must look at the values to determine what is there.
-
The scope of values may differ. One system may have two types of PAY_TYPE, and the other may have three types. Are the differences reconcilable?
-
One system may record information to a lower level of granularity than the other system. For example, one may encode color as RED, BLUE, and GREEN, whereas the other system may have five values for shades of RED, four values for shades of BLUE, and so on. The issue then becomes whether the target system can deal with the differences.
-
The systems may handle NULL or NOT KNOWN differently. One system may not allow them, whereas the other does. One system may record a NULL as a blank and the other system as the? character.
-
Special meaning may be attached to specific values in one system. For example, a policy number of 99999999 may mean that the policy number has not been assigned yet.
It is not sufficient that the target system have a field of the correct data type and length as the source system field. It is necessary that every value in the source system can be translated to an acceptable value in the target system that has exactly the same semantic meaning. Failure to do this will turn acceptable (accurate) values in the source system into unacceptable (inaccurate) values in the target system.
Another problem comes into play in matching data elements when there are a different number of data elements between the source and target systems. When the target system has a data element that does not exist in the source system, a determination needs to be made on what to do about it. The target data element may be eliminated from the design, NULLS inserted, or values manufactured for the field. In any case, the result is less than optimal. This problem is compounded when merging data from multiple sources wherein some sources have values for this field and other sources do not. The result is a target data element populated with highly questionable data. Any attempt to use the field to generate aggregations for groups will yield inaccurate results.
When the source system contains excess data elements, a decision needs to be made on whether the information is, in fact, needed in the target system. Generally it is okay to leave it out, provided it does not have structural importance to other data elements.
Source and target systems need to be matched at the structural level as well as at the data element level. This is a step often either not done or done very poorly. The result can be failures in attempting to move the data or, worse yet, inaccurate results in the target systems.
Structural matching involves checking to see if data element functional dependencies and referential constraints in the source systems match those in the target systems. This is discussed in detail in Chapter 9.
For example, if the data elements of one system are not part of a primary key and they correspond to data elements in the other system that are part of a primary key, an error can easily occur in trying to move the data. Another example is where in one system the DISCOUNT is applied to the order, and in the other system it is applied to individual line items within the order. If the target system has the discount on the order, a problem exists in trying to move the data.
A large number of errors are routinely made when trying to force data into a target structure in circumstances where the two systems are structurally different and not reconcilable. The reason so much force fitting is done is that the information about these differences usually does not surface until the actual implementation phase of projects. By then, the project team is trying to make things work at any cost.
Once data is understood and matched, the project must construct processes to extract the data from the source databases, run them through any data cleansing needed, apply transforms, and load the data into the target systems. Shortcomings in analyzing the source data and in matching elements and structures often lead to serious problems in executing these procedures or result in corrupt data in the target systems.
Extraction
Extracting data normally involves reading the source databases and building output files suitable for use in the subsequent processes. These output files are almost always expected to be in a normalized form. This means that they are tables of values, hopefully in "third-normal" form. (Normal forms of data are explained in Section 9.1.)
Source systems are not always easy to unwind into a set of normalized flat files. Depending on the complexity of how data is stored in the source systems, this can be a monumental task that is susceptible to all sorts of errors.
For example, a mainframe VSAM application covered by COBOL copy-books may store information in the same data file for many different records and have variations embedded within. Liberal use of the REDEFINE and OCCURS clauses can provide a challenging structural situation that must be studied thoroughly before developing the extraction routines.
A program cannot automatically figure this out for you. Many extraction programs have been constructed that automatically read the copybook and develop extraction logic from it. There are a number of problems with this approach. A REDEFINE may be used to recast the same facts or to indicate a different set of facts depending on some other value in the record. Only a human can determine which is meant. In one case you need to select the representation to include in the output; in the other you need to normalize the facts within the REDEFINE into separate data elements. A similar situation exists for OCCURS clauses. Do they represent n occurrences of the same fact or n different facts? One case calls for normalization into a separate file, and the other does not.
A company was trying to move a VSAM application for which over 200 different record types were encoded within the same VSAM file using a record type field to distinguish them and an equal number of record-level REDEFINEs. There were also liberal uses of REDEFINE and OCCURS within many of these record types. In essence, the user had cleverly defined an entire relational database structure within the VSAM file structure for a single file. Unfortunately, his cleverness caused great pains for subsequent analysts who needed to extract data from this file. As you might expect, he was no longer with the company when this was needed. Unraveling it into the proper relational definition was not easy.
Converting nonrelational structures to normalized files may also require key generation in cases for which the connection between records is done through positioning or internal pointers. Failure to recognize this and provide the keys will result in files that lack the ability to JOIN objects later or to enforce referential integrity constraints.
Extraction routines also need to handle overloaded fields. Often, they merely look at the source data as being in error and just reject the values or substitute a NULL or blank/zero value in its place. This is generating wrong information from correct information.
Source systems are often denormalized. Denormalization was a common trick used in earlier systems (especially early relational systems) to obtain adequate performance. Failure to recognize that the source data is denormalized results in denormalized flat files, which can lead to denormalized targets, which can lead to statistical errors when using the data. This is another area rarely documented in source systems.
The inverse is also true. Extraction routines that "flatten" data from hierarchical structures often generate denormalized flat files from structures that were correctly normalized. Most general-purpose extraction programs have the potential for doing this. For example, in an IMS database containing multiple segment types, if only one output file is generated for the entire database, it is denormalized if multiple occurrences of child segments are allowed for each parent instance. This output file will generate errors in the target system if the denormalization is not corrected somewhere else in the process.
Data Cleansing
Data cleansing involves identifying incorrect data values and then either correcting them or rejecting them. They deal with INVALID values in single data elements or correlation across multiple data elements. Many products are available to help you construct data cleansing routines. They can be helpful in improving the accuracy of data or they can result in less accurate data, depending on how carefully they are used.
Data cleansing becomes a problem when you lack an understanding of the source data and reject values that have special meaning. For example, if the source system had a convention of putting a value of * in a STATE field to indicate local state, the scrubbing routine may infer that * is invalid and either reject the row or put a null in its place. Even though the convention is unusual, it was correct in the source system, whose applications understood the convention.
Another problem is when data cleansing routines reject a value that is clearly correctable. For example, multiple representations of a name in a text field may include misspellings or alternative representations that are clearly recognizable for what they should be in the source systems. For example, the entry blakc is clearly a misspelling for black, and Tex is clearly an alternative representation of the text Texas (or TX if two characters are the convention).
A poorly designed data cleansing routine will reject these values and substitute a NULL or blank. The result is that there is no way of correcting it in the target system because the original wrong value is lost.
Data cleansing routines can identify wrong values but generally cannot correct them. They can correct values only through synonym lists or correlation against tables showing valid combinations of values. Most of the time they identify a wrong value but cannot correct it. The only alternative is to change the value to unknown (NULL in most systems) or to reject the row in which the bad value is contained. If it is rejected, they can either leave it out of the target (creating a bigger problem) or manually investigate the value and reenter it into the target after correction.
Leaving rows out has multiple problems. First, you are losing some data. The correct data in other data elements of these rows may be more important to the target than the result you get by leaving the entire row out. Another problem is that you may create a structural problem relative to other rows in the same or other tables. For example, if you reject an order header, the order detail records in a different file will become orphans. Rejecting one row may have the effect of causing many other rows to be rejected later, when referential constraints are enforced upon load.
Transforms
Transforms are routines that change the representation of a value while not changing the content. For example, in one system, GENDER may be represented by 1 and 2, whereas in the target it is represented by M and F. The transformation routine simply translates 1s to M and 2s to F. Transformation routines can be simple or complex. Failure to properly specify transformations can result in correct data in the source becoming wrong data in the target.
Two areas that commonly introduce problems are code page crossovers and currency translation. For example, if you are building a central data warehouse from data coming from divisions around the world, you need to pay special attention to the effects either of these may have on the outcome. Code page conversions can lose special country codes that translate the special characters of another country into the USA code page. This may generate a name value that looks invalid to the target system.
Another problem sometimes overlooked is where a source system stores a dollar value as an integer. The application programs "know" that they are supposed to insert the decimal point after position 2 (effectively dividing the stored value by 100). A transform needs to occur when this data is moved. If the analyst fails to recognize the convention, the values are moved over as if they were full dollar amounts.
Loading
The last step of the data movement process is loading data. You would think that this step would be a safe bet and that all of the damage that can be done has already been done to the data. Assuming you have properly defined the target database, you only need to deal with a few issues.
You need to ensure that all of the data gets loaded in order for the target to be in a consistent state. This sounds simple. However, if data is coming from dozens of sources, you need to ensure that all of the data from all sources gets there and gets loaded together to create a complete target system. One of the important issues of data warehouse and data mart design is ensuring that this is done and that the data is not released to the user community until a complete load is accomplished.
Another issue is what you do with the data that is rejected upon load due to data type, key definition, referential constraint, or procedure violations. As in the case of data cleansing, you must decide if you substitute a value to make the structure work, leave rows out of the target, or investigate the cause and enter the correct values.
The quantity of rejections will determine the best way to handle this issue. A good data movement process will have found all of these values before they get to the load process.
This section has shown that there are many opportunities to make mistakes in the process of extracting data from one system and moving it to another. The majority of these mistakes are mistakes of omission. The developer of the processes does not have a correct or complete set of information about the source systems in order to know everything that needs to be done. The scary part of this is that we continually plow through projects with very low-quality metadata for the source systems and try to fix or reconcile the problems after the fact.
The other problem is that when we look at the data in the target system and determine that it is of low quality we instinctively blame the source systems instead of considering the movement processes as the culprit. Since source systems are difficult to change, little is generally done about the situation. Often the target system is just not used because of a lack of confidence in the data. Much of the time, the target system quality can be improved immensely through fixing the data movement processes.
Figure 3.4 diagrams the steps involved in the data movement process. Clearly, the more effort you make in completing the first two steps properly the fewer mistakes you make in the other steps. Mistakes result in inaccurate data in the target systems. Eliminating the mistakes makes the target systems more accurate and more usable.
Data Integration
The previous section covered what can go wrong when data is taken from one system to another. Data integration projects that fetch data from source systems and use them in new applications have all the same problems. They may be only fetching tiny amounts of data for each use. However, the data in the source systems, no matter how small, must be properly extracted, cleansed, transformed, and put into a form (usually a message) the target application understands. Virtually all of the topics covered for batch, bulk data movement apply to integration.
Failure to recognize this and do everything that needs to be done leads to inaccurate data being presented to new applications from correct databases. This can lead to incorrect processing of transactions because of wrong data values being presented to the integration transactions. This has a large potential for negative impacts on the business conducted through them.
|
|
EAN: 2147483647
Pages: 133