Business-Tier Architecture Options
Business- Tier Architecture Options
Chapter 3 introduced the bigrez.com example application and described the Web application architecture chosen for the presentation tier. The next step in the construction is the selection of a business-tier architecture based on the general business-tier requirements outlined in the previous sections and our particular application requirements for bigrez.com .
We ll examine three candidate business-tier architectures in this chapter:
-
Stateless services using JDBC to perform SQL operations
-
Stateless services using entity beans for persistence operations
-
Combination of stateless services, entity beans, and direct interaction
Clearly there are many more candidates that might be considered , including Java Data Objects (JDO), the use of third-party object-relational mapping tools, such as CocoBase or TopLink and others. A complete survey of all possible architectures is beyond the scope of this book. Use the discussion in this chapter to aid you in choosing the right architecture for your application by applying a similar selection process that considers your particular business-tier requirements and limitations.
Stateless Services with JDBC
The first candidate business-tier architecture uses stateless services to encapsulate all business logic, a pass- by-value technique to accept and return business objects, and simple JDBC functionality to implement persistence. Figure 7.6 illustrates this architecture for a simple application containing a single service and business object. Services can be implemented as either stateless session beans or simple Java classes if the security, transaction, and pooling features of EJB technology are not required.
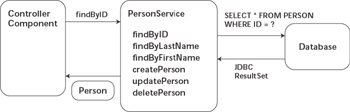
Figure 7.6: Stateless service JDBC architecture.
As shown in the figure, each business-tier request is implemented as a separate method on the service. Process encapsulation is achieved by creating coarse-grained methods on the service that encapsulate multistep processes. All of the object-relational mapping requirements and data access requirements are implemented with custom Java code and SQL statements. You can develop methods to find business objects by any number of criteria, and a general find method accepting the actual WHERE clause for the SQL statement is also possible.
The primary advantage of this architecture is its flexibility. All the business-tier requirements can be met with this architecture, although some require a large amount of custom coding. Table 7.2 presents a list of the business-tier requirements and describes the capabilities and limitations of this simple service- and JDBC-based architecture in each area.
| REQUIREMENT | HOW DOES ARCHITECTURE MEET REQUIREMENT |
|---|---|
| Process encapsulation | The use of stateless session beans or services provides a natural boundary for process encapsulation. Transaction control and propagation are normally handled in custom code. |
| Validation | Validation can be performed by business-tier components using data in value objects. |
| Simple O-R mapping | The SQL statements required for basic CRUD operations are coded in some component in the business tier and executed by business-tier components when necessary. JDBC results must be translated to value objects in code. |
| Objects spanning tables | The SQL statements can span multiple tables. |
| Aggregation (read operations) | Business-tier components must implement aggregation behavior in code. SQL statements can be designed to fetch shallow or deep. Value object graphs must be constructed from JDBC results. |
| Aggregation (other operations) | Business-tier components must implement all desired behavior for walking through the object graph and performing the proper SQL statements. The value object graph must be translated to variables in SQL statements by business-tier code. |
| Projection objects | The SQL statements can limit columns returned and span multiple tables. JDBC results must be translated to value objects in code. |
| Associations | Business-tier components must implement all desired behavior for walking through the object graph and performing the proper SQL statements. The value object graph must be translated to variables in SQL statements by business-tier code. |
| Inheritance | The SQL statements can implement any of the inheritance techniques described in this chapter. Value objects can inherit and share attributes. |
| Basic data access operations | All data access is performed using SQL statements executed through a JDBC connection. |
| Advanced data access operations | The SQL statement can implement any advanced feature available in JDBC and meet all of these requirements. A substantial amount of custom code will be required for most features. |
| Audit, logging, and instrumentation | The use of stateless session beans provides a natural audit and logging point. All SQL statements can be executed through a common service or helper, providing additional logging and instrumentation opportunities. |
| Security | Security is limited to method-level security on the stateless session bean methods. |
This architecture continues to be a very common and useful choice for many applications. You can essentially do anything in this architecture because you control, and are responsible for writing, everything in the service. You can optimize business logic and SQL queries for performance, making this architecture a good choice for high-volume OLTP applications. Recognize, however, that with this control and flexibility comes additional complexity: You must code everything yourself, including all O-R mapping and advanced data-access operations.
Note that there are many possible variations of the basic architecture. The SQL statements required for persisting objects can be defined in additional data access tiers, factory components, or in the objects themselves . JDBC RowSet objects can replace value objects as the mechanism for passing data between components. In all cases, however, persistence is accomplished through direct JDBC statements at some level in the architecture.
| Best Practice | Consider a service- and JDBC-based architecture when the ability to optimize performance and control all business and persistence operations is more important than the added complexity. |
Our bigrez.com application needs to perform well and contains a relatively simple object graph, so we could very well build it using an architecture such as this without too much difficulty. Let s move on to the next candidate and see if it represents an improvement.
Stateless Services with Entity Bean Persistence
The second candidate architecture resembles the first choice in some respects. It also uses stateless services, but it replaces the JDBC-based data access logic with an entity bean layer modeling the business objects. As shown in Figure 7.7, the stateless service acts as a session fa §ade encapsulating both business logic and the basic persistence operations for business objects.
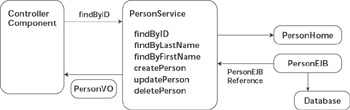
Figure 7.7: Stateless service entity-bean architecture.
Each business-tier request is implemented as a separate method on the service, meeting the process encapsulation, validation, and other business-tier requirements in the same manner as the last architecture. We ve simply swapped out the JDBC-based persistence layer and replaced it with entity beans. The entity beans are responsible for all data access services and for meeting some, if not all, of the object-relational mapping requirements. The entity beans can be either bean-managed persistence (BMP) beans or container-managed persistence (CMP) beans, although CMP beans are favored in this role. Using BMP entity beans behind a stateless service requires hand-creation of JDBC code in the bean callback methods, as discussed in Chapter 6, and provides little or no opportunity to optimize the persistence logic. Using CMP beans eliminates the hand-coding of persistence logic and provides access to all of the persistence optimization capabilities of the WebLogic Server EJB container.
Note that the client or controller component requesting the business service is not allowed to communicate directly with the entity bean in this architecture, nor can entity beans be passed to services or be returned by them. A separate value object is normally used to contain the data in the related entity bean for use in communicating with the service. These value objects almost invariably contain a mirror image of the attributes in the entity bean, but they are defined to be serializable to enable passing by value via remote (RMI) invocations. The stateless service is normally responsible for copying data back and forth between value objects and the related entity beans in addition to performing any business logic contained in the service itself.
Table 7.3 presents a list of the business-tier requirements and describes the capabilities and limitations of this service and entity bean architecture in each area. We re assuming the use of container-managed persistence in the entity beans in this analysis to maximize the benefits of entity beans.
| REQUIREMENT | HOW DOES ARCHITECTURE MEET REQUIREMENT |
|---|---|
| Process encapsulation | The use of stateless session beans provides a natural boundary for process encapsulation. Transaction control and propagation are normally handled by the EJB container automatically. |
| Validation | Validation can be performed by business-tier components using data in value objects or in the entity beans themselves. |
| Simple O-R mapping | CMP entity bean functionality is used for simple mapping. |
| Objects spanning tables | CMP multiple table spanning capability is employed. |
| Aggregation (read operations) | CMP relationship modeling provides aggregation mapping and desired behavior. WebLogic Server field groups and relationship caching are employed to control the depth of fetches. Value object graphs must be constructed from fetched entity beans. |
| Aggregation (other operations) | Business-tier components must implement all desired behavior for walking through the value object graph and performing the proper entity bean operations. Data in the value object graph must be translated to set methods on CMP beans by business-tier code. |
| Projection objects | It is difficult to provide flexible projection capability and multitable queries with CMP entity beans. New WebLogic Server finder and ejbSelect features may help. |
| Associations | Business-tier components must implement all desired behavior for walking through the value object graph and performing the proper entity bean operations. The data in the value object graph must be translated to set methods on CMP beans by business-tier code. |
| Inheritance | It is difficult to implement inheritance in CMP entity beans because of a lack of inherited CMP behaviors. Inheritance through aggregation is possible using container-managed relationships by creating unidirectional, one-to-one associations with base classes. |
| Basic data access operations | Substantially all data access is performed by CMP entity beans and related finders and ejbSelect methods. |
| Advanced data access operations | The ability to implement advanced data access operations is limited to the support present in the EJB container. WebLogic Server includes support for most of the advanced operations listed in the requirements. |
| Audit, logging, and instrumentation | The use of stateless session beans provides a natural audit and logging point. There is limited ability to log or instrument container-managed persistence operations. |
| Security | Security can be implemented at the method level on services and on each entity bean at the class or method level using standard J2EE security models. WebLogic Server adds additional policy-based security features. |
Clearly one big advantage of this architecture is the built-in separation between controller components and entity bean components provided by the stateless service. There are at least four resulting benefits:
Encapsulation. The callers use only the specified service-level interfaces, allowing business logic and persistence operations in the service to change without breaking client code.
Remotable. It is easy to modify interfaces defined at the service level to support remote method invocation. This provides additional deployment flexibility and may aid in the creation of separate Web services that invoke business services.
Single entry point. Transaction and security controls can be set in the service alone.
Separate value objects. Value objects can be simple mirrors of entity bean data or specialized structures useful to the presentation layer, possibly containing data from multiple beans or formatting data in some convenient manner.
This architecture is very popular and useful for applications of all sizes. The CMP entity bean technology in EJB 2.0 is leveraged to provide automatically generated persistence services rivaling the best handwritten JDBC code, and the stateless services provide the encapsulation and other benefits required for a robust business-tier architecture. With the big improvements in CMP entity beans in EJB 2.0 and the new WebLogic Server-specific caching and optimization features, it is hard to beat this architecture for most J2EE applications.
| Best Practice | The combination of stateless services and CMP entity beans is a very strong candidate for most J2EE applications. Consider this architecture for more complex applications requiring maximum deployment flexibility. |
This architecture is not perfect, however. There are some subtle, but significant, drawbacks inherent in the conversion from value objects to entity beans in the services. As indicated in Table 7.3, the handling of aggregations and associations can be significantly more complex when all relationships must be represented in the value object graph for the purposes of communication with the services.
As a simple example of this drawback, consider the case of a parent-child relationship between two objects and the logic required in the services to maintain these objects and their relationships. You would need methods on the stateless service to perform at least the following set of services:
-
Fetching one or more parent objects using supplied criteria, and returning the parent objects plus children objects for each parent if desired by the client. The service would fetch the parent entity beans, walk through the list creating the parent value objects, optionally iterate on the children relationship fields to fetch each child entity bean, create a value object for each child, and place it in the object graph.
-
Fetching one or more child objects using supplied criteria, including the parent object for each child if desired by the client. The service would fetch the child entity beans, walk through the list creating each child value object, optionally traverse the relationship to the parent entity bean, create a value object for the parent, and place it in the graph.
-
Updating a parent object, including the update of any attached children objects. The service must determine the proper insert, update, or delete operation to perform for each child value object in the graph. Child value objects would require a status flag set by the client, or separate lists of child objects would have to be supplied by the client representing each desired type of operation. The service would fetch and update the parent entity bean using the data in the parent value object, then fetch and process each child object according to the required operation.
The difficulty in using value objects only intensifies when many-to-many relationships and other complex associations are modeled in the entity beans. The simple copying of value objects to entity beans becomes a nightmare very quickly if the object graph becomes large and complex. Remember that making multiple calls to the service to process portions of the object graph may not be a viable solution if you have strict requirements for transactional consistency. To ensure consistency, the service must begin and end the transaction in a single method call, so all of the required value objects, relationships, and required CRUD operations must be represented by the parameters and data structures passed to the service in that single method invocation.
Despite this limitation, the service and entity bean architecture remains a very strong candidate for many J2EE applications, including our bigrez.com example application. We could stop here and simply build the application using this architecture, and no one would be likely to argue with the decision. We want to examine one additional candidate, however, and see if there is some way to eliminate the minor drawbacks of this architecture and truly leverage the built-in persistence services defined in the CMP entity beans.
Stateless Services, Entity Beans, and Direct Interaction
The final candidate architecture builds on the previous service and entity bean architecture by combining the use of stateless services, entity bean persistence, and the direct interaction of client and presentation-tier controller components with the entity bean components when performing certain operations. The goal is to reduce or eliminate the need for value objects and eliminate the creation of methods in the service that mirror the basic persistence and relationship-handling methods already present in the entity beans themselves.
For example, the simple fetch operation depicted in Figure 7.8 is performed by the controller component directly using the home interface for the entity bean. This request returns a reference to the entity bean, and the controller component interrogates the bean directly for its data using get methods on the bean s local interface.
As described in Chapter 3, all access to the entity bean must be done in a transaction started by the controller component to avoid multiple loads from the database in a noncached environment. Clearly, the controller component should also be collocated in the same instance of WebLogic Server to avoid remote communication with the entity bean as the individual get methods are called on the bean to retrieve its contents. These two drawbacks represent the largest arguments against the use of direct interaction, and they are not minor drawbacks, but let s examine what we gain in this architecture before we jump to any conclusions.
Recognize that this architecture does not eliminate stateless services completely. Business logic and multiple-step processes are still placed in stateless services to provide process encapsulation and other benefits described previously. Even when employing a service in this way, however, the use of value objects for parameters and return types is discouraged in favor of entity bean references. Figure 7.8 does not include a service because in the case of the PersonService depicted in Figures 7.6 and 7.7, there were no methods defined on the service that could not be performed directly using home-interface finder methods or direct interaction with the entity bean.
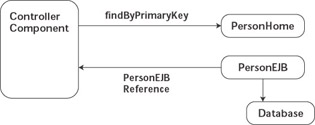
Figure 7.8: Direct interaction eliminates value objects.
Table 7.4 presents a list of the business-tier requirements and describes the capabilities and limitations of this combined service, entity bean, and direct interaction architecture in each area.
| REQUIREMENT | HOW DOES ARCHITECTURE MEET REQUIREMENT |
|---|---|
| Process encapsulation | The use of stateless session beans provides a natural boundary for process encapsulation. The EJB container normally handles transaction control and propagation automatically. |
| Validation | Validation can be performed by business-tier components using data in the entity beans or in the entity beans themselves. |
| Simple O-R mapping | CMP entity bean functionality is used for simple mapping. |
| Objects spanning tables | CMP multiple-table spanning capability is employed. |
| Aggregation (read operations) | CMP relationship modeling provides aggregation mapping and desired behavior. WebLogic Server field groups and relationship caching are employed to control the depth of fetches. Collections of parent bean references are returned to the caller. WebLogic Server automatically provides lazy fetching logic as the caller traverses relationships. |
| Aggregation (other operations) | Modifications made to any child beans or relationships are automatically persisted at the end of the transaction by WebLogic Server CMP facilities. No business-tier logic is required to identify the required operations or walk value object graphs. |
| Projection objects | It is difficult to provide flexible projection capability and multitable queries with CMP entity beans. New WebLogic Server finder and ejbSelect features may help. |
| Associations | Modifications made to any relationships are automatically persisted at the end of the transaction by WebLogic Server CMP facilities. No business-tier logic is required to identify the required operations or walk value object graphs. |
| Inheritance | It is difficult to implement inheritance in CMP entity beans because of a lack of inherited CMP behaviors. Inheritance through aggregation is possible using container-managed relationships by creating unidirectional, one-to-one associations with base classes. |
| Basic data access operations | Substantially all data access is performed by CMP entity beans and related finders and ejbSelect methods. |
| Advanced data access operations | The ability to implement advanced data-access operations is limited to the support present in the EJB container. WebLogic Server includes support for most of the advanced operations listed in the requirements. |
| Audit, logging, and instrumentation | The use of stateless session beans provides a natural audit and logging point. There is limited ability to log or instrument container-managed persistence operations. |
| Security | Security can be implemented at the method level on service and on each entity bean at the class or method level using standard J2EE security models. WebLogic Server adds more policy-based security features. |
This table is very similar to Table 7.3 because the architectures are, in fact, very similar. The primary benefit of direct interaction with entity beans is in the aggregation and association object-relational mapping requirements. There is no value object graph to walk or complex business logic to code in order to determine the proper set of entity beans to enlist in the transaction and the proper set of operations to perform. Whatever changes were made to the entity beans through their own attribute and relationship set methods will be persisted by the CMP facilities at the end of the transaction. That, in a nutshell , is the benefit we are after.
What about the four advantages listed in the previous section? Let s review them and see how direct interaction stacks up:
Encapsulation. Callers continue to be separated from business and persistence operations using interfaces, although in this architecture these interfaces are located in services, home interfaces, and bean interfaces. You can also encapsulate all operations in services as long as entity bean references are returned instead of value objects.
Remotable. Entity bean home interfaces, bean interfaces, and services that return entity bean references are not remotable through simple declarative techniques. Web applications and EJB components must be collocated in the same enterprise application, and separate interfaces supporting remote invocation and pass-by-value semantics must be created if required.
Single entry point. Transaction and security controls must be set in the service and in all entity beans accessed by controllers or other client code.
Separate value objects. Specialized value objects are still possible, if desired, although the direct interaction approach avoids the use of value objects for normal operations. Entity beans can easily be extended to include methods that return formatted data or simulate flattened projection objects.
Did we gain enough benefit in the use of direct interaction to offset the drawbacks? We ve eliminated value objects and their constant copying and creation, dramatically simplified the services layer by eliminating all methods related to persistence and object-relational mapping, and leveraged all of the lazy-instantiation and caching features in WebLogic Server to the fullest extent. Not too shabby.
Obviously, the appropriateness of this architecture depends largely on the complexity of the object model and the related benefits provided by the direct interaction approach. Recognize that EJB 2.0 introduced many of the new features being leveraged by this architecture, so it is not surprising that the industry has not examined direct interaction as a viable alternative to value objects prior to EJB 2.0. Now that relationships are handled very efficiently in the entity beans themselves, however, it deserves some attention.
| Best Practice | Consider the use of direct interaction with entity beans in applications that can leverage local interfaces and the improved aggregation and association handling afforded by this architecture. |
Chosen Architecture for bigrez.com
We ve chosen to implement the bigrez.com application using a combination of stateless services, value objects, and direct interaction with entity bean components. We ll introduce a handful of stateless session beans and use them to encapsulate complex or multistep business processes, but we will allow controller components to interact directly with the entity beans for most queries, data retrieval, and data update operations.
As shown in Figure 7.9, the bigrez.com application requires a fair number of business objects and relationships to model the business domain. Implementing all of the business-tier requirements for this object model using only stateless services and value objects would be possible, of course, but the chosen design allows us to explore the benefits of direct interaction for a realistic object model to gain additional insight.
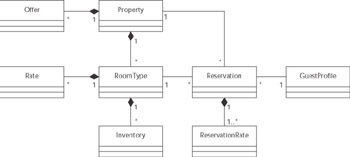
Figure 7.9: Object model for bigrez.com application.
We ve introduced three stateless session beans ( InventorySessionBean , OfferSessionBean , and ReservationSessionBean ) and implemented eight CMP entity beans representing the primary business objects in the object model. There are also a variety of helper classes, utility classes, base classes, and a handful of value objects. The value objects are used to encapsulate data for communication with the session beans in certain operations.
One thing you might note about the components in this application is the lack of administration-related business-tier components. All of the property-related data can be edited through the administration Web site, as discussed in Chapter 4, but very few business-tier components are required to support this functionality. This is a direct result of the choice of direct interaction with entity beans for the majority of persistence behaviors. Most administration Web components do not require stateless session beans and other business-tier components to find, create, read, update, or delete business objects or their relationships because these operations are performed directly through the entity bean interfaces.
The remainder of this chapter will walk through the construction of a number of these business-tier components to highlight choices made, techniques used, and best practices that can be applied to your development efforts.
EAN: 2147483647
Pages: 125