Business-Tier Requirements
Business- Tier Requirements
As we stated in Chapter 2, always identify requirements before choosing a design. Before selecting the Struts-based presentation-tier architecture, we spent a fair amount of time identifying the many presentation-tier requirements present in Web applications. Key requirements such as error handling and form redisplay led us to the choice of a robust servlet-centric presentation-tier framework rather than a simpler JSP-centric approach. We ll now follow the same strategy and identify key business-tier requirements that drive our choice of architecture to ensure that we make the right decision.
As in Chapter 2, when we talk about business-tier requirements in this section we mean the general requirements of a business-tier architecture, rather than the specific requirements of a given application. Although the specific application requirements can matter in the architecture selection, there are many common business-tier requirements that should be considered in the decision process as a starting point.
We ll walk through the business tier from the business logic requirements through to the database access requirements and identify key requirements that will be useful in evaluating candidate business-tier architectures.
Business Logic Requirements
The first set of business-tier requirements is derived from the business logic requirements for the application. Most applications have specific business logic requirements based on the required application behaviors and functions. Unlike the common requirements for data access or object-relational mapping, however, it is difficult to generalize and identify business logic requirements that are common to all applications. We will simply identify a few common business logic requirements and include them in our analysis as a starting point.
Process Encapsulation
The first common requirement is the need to encapsulate complex or multistep processes in the business-tier components and to make them available to other tiers through a simple, straightforward interface. The user of the business-tier component should be insulated from the implementation details. In a distributed, transactional environment, this encapsulation also provides performance benefits by eliminating the need for multiple distributed requests from the user to the service.
The session fa §ade pattern is a typical solution for this requirement. As illustrated in Figure 7.1, the session fa §ade pattern uses a stateless session bean component to encapsulate all of the business logic, loading and storing of entity beans, and other activity required to process a particular request. Without the fa §ade, the client component might be required to begin and manage the transaction, make multiple calls to session beans, entity beans, and other business-tier components, and trap and handle all business exceptions. Clearly this is not the optimal solution.

Figure 7.1: Session fa §ade encapsulates complex business logic.
The business-tier architecture must therefore provide a mechanism for encapsulating complex business logic and providing a straightforward interface for client and controller components.
Validation
The second common requirement is for business-tier validation of objects and their data elements. As discussed in Chapter 2, the data values submitted by a Web application user are often validated both on the page itself, via JavaScript, and in a presentation-tier component such as the form bean or controller class. Many applications consider this level of validation sufficient and allow the business-tier components to perform operations on client-provided data without repeating the validation checks.
Other applications have more rigorous requirements, however, and must include validation checks on all data sent to the business-tier components. The need for business-tier validation may not be present in the original application, but it can occur once the component is reused in a subsequent application. For example, a component intended for use with a Web application having validation checks in the presentation tier might eventually be reused by a different application that does not include presentation-tier validation.
The business-tier architecture should provide a mechanism for validating objects and data and returning validation errors in much the same way the controller components provided this functionality in the presentation tier.
Object-Relational Mapping Requirements
Moving farther into the business tier toward the database, the next set of requirements defines the mechanisms for mapping objects to the relational database technology. These object-relational (O-R) mapping requirements define the functions necessary to translate between object technology and relational database representations of the data.
Mapping Simple Classes
The simplest form of object-relational mapping is the simple one-to-one mapping of a business object to a database table. Some of the characteristics of this type of mapping include the following:
-
The attributes in the business object are all scalars, strings, or other simple data types.
-
Each attribute maps to a single column in the database table.
The object-relational mapping techniques must allow for a straightforward mapping of business objects to tables, including support for basic create, read, update, and delete (CRUD) operations.
It is possible to design a database where a single business object is spread across multiple tables. Inserting the business object creates a row in both tables, removing the object deletes the corresponding row in each table, and modifying the object updates both rows as well. The O-R mapping techniques must allow for objects that span tables in a database, possibly across multiple databases.
Mapping Simple Aggregation
The term aggregation refers to ownership, or parent-child, relationships, in which the child cannot exist without the parent. Typically there is a one-to-many relationship between the parent and the child table. If it was a one-to-one relationship, you could simply fold the child data back in to the parent table in most cases.
A good example is the person and address example from Chapter 6. Each person can be related to zero or more addresses, but every address must be associated with a single person. There is a dependent, one-to-many relationship between these tables. The O-R mapping technique must provide a mechanism for identifying children for a particular parent, normally through the use of a foreign key, and must also provide methods for accessing and manipulating children.
Some basic rules apply in aggregation:
-
Deleting the parent is dependent on having no remaining children in the database. This is normally enforced by the referential integrity (RI) constraints in the database. Automatic deletion of children during a parent delete is possible, but it must occur before the parent is deleted.
-
Inserting child rows also depends on the existence of the parent row for the RI constraints to allow the insert.
-
Updating the parent primary key becomes a pain, requiring a multistep process of copying the parent row, changing the children to reference the new parent row, and then deleting the original parent row. This operation is costly and should be avoided by using immutable keys for primary key identifiers if at all possible.
Note that aggregation looks different in memory than it does in a database. In memory, objects are normally linked via memory pointers or references in an object graph .
The object-relational mapping technique must provide a mechanism for both creating the interconnected series of objects in memory when reading parent and child tables and writing out the interconnected objects to the proper database tables when making changes.
Ideally, the O-R mapping technique should be capable of the following:
-
Automatically creating the object graph during a fetch operation, linking business objects to their children, and prefetching some or all of the graph during the initial database operation
-
Automatically walking through all of the parent, child, and grandchild relationships in the object graph and performing the necessary and appropriate CRUD operations on the objects to save any changes
One final topic related to aggregation and relationships in general: You often want to defer the fetching of child objects until the time they are actually required. In many cases, the parent may be all that is required to perform a calculation or present some business data to the user, and it is a waste of resources to fully populate the object graph with all child objects. This technique of waiting to fetch children is sometimes referred to as lazy instantiation .
Note that with this lazy instantiation technique, you also need a mechanism to determine whether child objects have been fetched. Parent objects often have a child- fetched flag for each child object or list.
The O-R mapping technique should therefore allow the following:
-
Fetching a parent object plus all of its children and grandchildren. This is called a deep or full fetch of the entire object graph starting with the parent object.
-
Fetching only the parent without fetching any children, often called a shallow fetch.
-
Fetching some or all of the children objects of the parent without refetching the parent itself as part of a lazy instantiation technique, often called a children-only fetch, which can itself be deep or shallow.
Projection Objects and Queries
You may often want to use objects that contain arbitrary subsets of data from one or more tables. One good example of such a projection object is a query result object that contains a subset of data from a table needed for the presentation of search results.
For example, the actual Person table might have 20 or more columns , so a result list containing many full Person business objects would represent a large amount of memory, network bandwidth, and so on. If the user interface needs to display only the first and last name , a specialized projection object could be defined that contains only those two attributes from the Person table plus the table primary key. The O-R mapping technique must allow fetching a list of these projection objects from the table using SQL statements that fetch only the required fields.
It is also valuable to create projection objects that span multiple tables, again containing only the attributes required for the specific requirement being satisfied. A highly normalized database will require multitable projection objects for best query performance. The query that fetches the multitable projection object should perform the join using the database rather than trying to fetch objects for each table in to memory and joining them by hand. The O-R mapping technique should allow for projection objects that define a subset of columns from one or more tables.
Mapping Associations/Relationships
Associations are more general forms of relationships between objects than the pure dependent form of association, aggregation. One common form of association is the many-to-many relationship between two tables that are not dependent on each other. For example, in Figure 7.2, the relationship between students at a school and the courses offered at the school is contained in a separate relationship table, Enrollment .
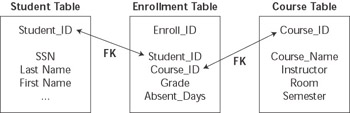
Figure 7.2: The relationship table implements a many-to-many association.
Clearly students can exist without courses, and courses can exist without students, so the two entity tables are not related to each other directly via aggregation. The Enrollment relationship table exists to indicate that a particular student is taking the specific course and can also include additional information related directly to this relationship. In this example, the student s grade in the specific course would be stored in the Enrollment table, not in the Student or Course table.
A complete discussion of O-R mapping techniques appropriate for general relationships of this sort is beyond the scope of this chapter. Solutions generally fall into one of two categories:
Direct mapping of relationships. Business objects implement relationships directly through internal pointers and lists of pointers to related objects. In this solution, Student and Course business objects contain lists of pointers to intermediate Enrollment objects according to the relationships stored in the enrollment table, and Enrollment objects maintain pointers to both types of objects. This technique is illustrated in Figure 7.3.
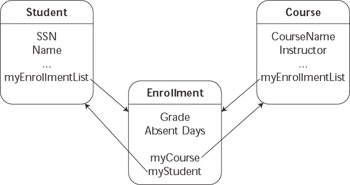
Figure 7.3: Business objects can implement relationships directly.
Simplified mapping of relationships. Specialized projection objects are used to present simplified views of the relationships and related business objects. In this solution, a student object would contain a list of CourseEnrollment projection objects with the required elements from both the Enrollment table and related Course table, a technique illustrated in Figure 7.4.
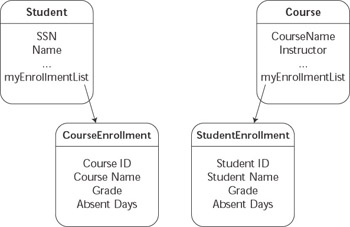
Figure 7.4: Projection objects are used to manage relationships.
Both techniques have advantages and disadvantages. The appropriate technique depends on your specific business requirements and the importance of simplifying the object graph. In either case, the chosen business-tier architecture must support flexible, efficient, and safe techniques for modeling and managing complex relationships.
Mapping Inheritance
Java is an object-oriented language, and one of the strengths of object-oriented technology is the concept of inheritance. Inheritance can be difficult to implement in an object-relational mapping environment, however, because normal database systems do not provide a native technique for inheriting and extending tables.
Three primary techniques are available for mapping inheritance to a set of database tables: horizontal partitioning, typed partitioning, and vertical partitioning. Figure 7.5 depicts these three techniques for a simple example containing a single base class, Person , and two subclasses, Employee and Customer .
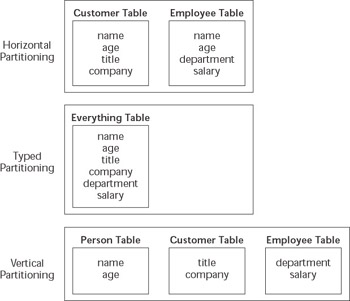
Figure 7.5: Options for O-R mapping of inheritance.
In horizontal partitioning, only concrete subclass objects are mapped to tables. These tables include all of the base class and subclass attributes. This approach may improve performance because only one table needs to be accessed for instances of a given concrete class.
In typed partitioning, all classes in an inheritance tree are mapped to a single table containing all attributes required for all subclass objects. A type column is used to distinguish which type of object is stored in each row of the table, and many type-specific columns in the table will be empty for a given object.
Finally, in vertical partitioning, every class in the inheritance tree maps to a table in the database. Fetching data for a concrete subclass involves a join operation between the base table and the concrete subclass table.
All three techniques for mapping inheritance in the database are viable , but there are clear advantages and disadvantages present in some of them. Designing the database to match the object inheritance tree exactly, represented in the vertical partitioning technique, can dramatically affect performance and complicate the data access services by requiring joins during all CRUD operations. On the other hand, the placement of all attributes for all object types in a single table, the typed partitioning technique, sacrifices a great deal of flexibility and maintainability to achieve fast and simple queries and CRUD operations. The horizontal partitioning scheme often represents the best compromise between flexibility and performance, and it can also be implemented easily with a variety of O-R mapping technologies including CMP entity beans.
| Best Practice | Horizontal partitioning provides the simplest and most efficient method for modeling inheritance in a relational database. |
All of the object-relational mapping requirements discussed in this section are important in real-world applications containing large, complex object models. Simple architectures may have no problem implementing the business logic and simple object-relational mapping requirements discussed in this section, but they often break down when they encounter more complex requirements in the object model such as nested aggregation or multiple sets of associated objects. Don t adopt an architecture that will not support the long-term needs in these areas.
Data Access Requirements
The business tier must provide basic data access services to support the object-relational mapping and business logic requirements outlined previously. Although this is not a complete list, most applications require at least the following set of data access services and functions:
-
Basic create, read, update, and delete operations at an object level to meet basic object persistence requirements
-
Support for more complex object-relational requirements, such as the lazy instantiation of children and persisting associations between objects
-
Flexible mechanisms for performing queries against tables to retrieve single business objects, arrays of business objects, and arrays of projection or custom query objects
-
Creation of custom SQL statements to perform complex logic without resorting to fetching objects and performing logic in business-tier components
-
Standardized mechanisms for handling large result sets and limiting returned results
-
Standardized mechanisms for handling and reporting data-related errors
-
Efficient bulk insert, update, and delete mechanisms to avoid reading and updating multiple objects one at a time
-
Concurrency control to eliminate the loss of data in the event of multiple simultaneous update transactions
Other Business-Tier Requirements
Finally, many applications have additional business-tier requirements in the following areas:
-
Creation of detailed audit trails of business-tier service requests, data access, data manipulation, and other activity. The audit tracks who, what, when, and even why these activities were performed.
-
Robust logging and instrumentation capability. It is used to troubleshoot system problems during system development and to provide usage profiling information during production operation.
-
High levels of performance and scalability. These are normally expressed as overall system requirements, of course, but the business-tier architecture plays a large role in ensuring good performance. The architecture must represent sound design principles and leverage all of the clustering, caching, and performance-related features of the application server hosting the components.
-
Security implemented in all tiers and services in the architecture. Requiring authentication and authorization at each business-tier interface provides a higher level of security than simply authenticating at the Web application level and allowing services to be called with impunity.
Review of Business-Tier Requirements
Table 7.1 summarizes all of the requirements outlined in this section and provides the set of criteria we ll use to evaluate candidate business-tier architectures for the bigrez.com application.
| REQUIREMENT | DESCRIPTION |
|---|---|
| Process encapsulation | Straightforward technique available to encapsulate complex or multistep business processes |
| Validation | Ability to perform business-tier validation |
| Simple O-R mapping | Basic create, read, update, and delete operations on simple objects that map onetoone with tables |
| Objects spanning tables | Basic CRUD operations on objects representing data from multiple tables |
| Aggregation (read operations) | Ability to perform deep fetching of parents and children, shallow fetching with lazy instantiation, and fetching of only children to support the lazy-fetching process |
| Aggregation (other operations) | Ability to automatically walk through an object graph and perform correct CRUD operations on each object according to its status |
| Projection objects | Ability to fetch objects containing subsets of columns from one or more tables |
| Associations | Ability to map relationships and perform all required CRUD operations on complex object graphs |
| Inheritance | Ability to map inheritance in object model to the database |
| Basic data access operations | CRUD operations, queries, persisting associations |
| Advanced data access operations | Limiting result sets, performing dynamic queries, supporting queries across multiple tables, projection objects, bulk operations, and concurrency controls |
| Audit, logging, and instrumentation | Techniques available to log, audit, and instrument business-tier activity at the method level |
| Security | Deep security providing authentication/ authorization throughout business-tier architecture |
EAN: 2147483647
Pages: 125