4.4 Stack ADT Implementations
In this section, we consider two implementations of the stack ADT: one using arrays and one using linked lists. The implementations are both straightforward applications of the basic tools that we covered in Chapter 3. They differ only, we expect, in their performance characteristics.
If we use an array to represent the stack, each of the methods declared in Program 4.4 is trivial to implement, as shown in Program 4.7. We put the items in the array precisely as diagrammed in Figure 4.1, keeping track of the index of the top of the stack. Doing the push operation amounts to storing the item in the array position indicated by the top-of-stack index, then incrementing the index; doing the pop operation amounts to decrementing the index, then returning the item that it designates. The construct operation (constructor) involves allocating an array of the indicated size, and the test if empty operation involves checking whether the index is 0. This code provides an efficient and effective pushdown stack of integers for a client program such as Program 4.5.
Program 4.7 Array implementation of a pushdown stack
When there are N items in the stack, this implementation keeps them in s[0], ... , s[N-1], in order from least recently inserted to most recently inserted. The top of the stack (the place for the next item to be pushed) is s[N]. The client program passes the maximum number of items expected on the stack as the parameter to the constructor for intStack, which allocates an array of that size, but this code does not check for errors such as pushing onto a full stack (or popping an empty one).
class intStack { private int[] s; private int N; intStack(int maxN) { s = new int[maxN]; N = 0; } boolean isEmpty() { return (N == 0); } void push(int item) { s[N++] = item; } int pop() { return s[--N]; } } To implement the class charStack for stacks of characters that is needed by Program 4.6, we can use the same code as in Program 4.7, changing to char the types of s, push's parameter, and pop's return value. Doing so amounts to defining and implementing a different ADT interface. We can use the same method to implement stacks for any type of item. This approach has the potential advantage of allow-ing us to specify different implementations tailored to the item type and the potential disadvantage of leaving us with multiple class implementations comprised of essentially the same code. We will return to this issue, but, for the moment, our focus is on different ways to implement stacks of integers.
We know one potential drawback to using an array representation: As is usual with data structures based on arrays, we need to know the maximum size of the array before using it so that we can allocate memory for it. In this implementation, we make that information an parameter to the constructor. This constraint is an artifact of our choice to use an array implementation; it is not an essential part of the stack ADT. We may have no easy way to estimate the maximum number of elements that our program will be putting on the stack: If we choose an arbitrarily high value, this implementation will make inefficient use of space, and that may be undesirable in an application where space is a precious resource. If we choose too small a value, our program might not work at all. By using an ADT, we make it possible to consider other alternatives, in other implementations, without changing any client program.
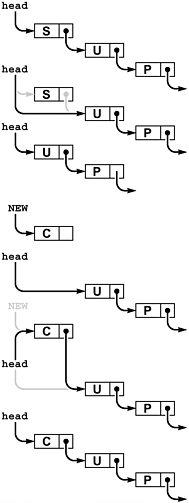
For example, to allow the stack to grow and shrink gracefully, we may wish to consider using a linked list, as in the implementation in Program 4.8. We keep the stack in reverse order from the array implementation, from most recently inserted element to least recently inserted element, to make the basic stack operations easier to implement, as illustrated in Figure 4.5. To pop, we remove the node from the front of the list and return its item; to push, we create a new node and add it to the front of the list. Because all linked-list operations are at the beginning of the list, we do not need to use a head node. Note that the constructor ignores its first parameter in this implementation.
Figure 4.5. Linked-list pushdown stack
The stack is represented by a pointer head, which points to the first (most recently inserted) item. To pop the stack (top), we remove the item at the front of the list by setting head from its link. To push a new item onto the stack (bottom), we link it in at the beginning by setting its link field to head, then setting head to point to it.
We could also change the types in Program 4.8 to get implementations of the charStack class for stacks of characters or classes for stacks of any other types of items. As mentioned for Program 4.7, this approach has the disadvantage of leaving us with different classes comprised of essentially the same code. In the next section, we consider alternate approaches that allow us to use existing code instead of having to write a new class each time we want to use a stack for a new type of item.
Program 4.8 Linked-list implementation of a pushdown stack
This code implements the pushdown stack ADT using a linked list. The data representation for linked-list nodes is organized in the usual way (see Section 3.3), including a constructor for nodes that fills in each new node with the given item and link.
class intStack { private Node head; private class Node { int item; Node next; Node(int item, Node next) { this.item = item; this.next = next; } } intStack(int maxN) { head = null; } boolean isEmpty() { return (head == null); } void push(int item) { head = new Node(item, head); } int pop() { int v = head.item; Node t = head.next; head = t; return v; } } Programs 4.7 and 4.8 are two different implementations for the same ADT. We can substitute one for the other without making any changes in client programs such as the ones that we examined in Section 4.3. They differ in only their performance characteristics. The array implementation uses the amount of space necessary to hold the maximum number of items expected throughout the computation. The list implementation uses space proportional to the number of items, but it always uses both extra space for one link per item and extra time to allocate memory for each push and (eventually) deallocate memory for each pop. If we need a huge stack that is usually nearly full, we might prefer the array implementation; if we have a stack whose size varies dramatically and other data structures that could make use of the space not being used when the stack has only a few items in it, we might prefer the linked-list implementation.
These same considerations about space usage hold for many ADT implementations, as we shall see throughout the book. We often are in the position of choosing between the ability to access any item quickly but having to predict the maximum number of items needed ahead of time (in an array implementation) and the flexibility of always using space proportional to the number of items in use while giving up the ability to access every item quickly (in a linked-list implementation).
Beyond basic space-usage considerations, we normally are most interested in performance differences among ADT implementations that relate to running time. In this case, there is little difference between the two implementations that we have considered.
Property 4.1
We can implement the push and pop operations for the pushdown stack ADT in constant time, using either arrays or linked lists.
This fact follows immediately from Programs 4.7 and 4.8. 
That the stack items are kept in different orders in the array and the linked-list implementations is of no concern to the client program. The implementations are free to use any data structure whatever, as long as they maintain the illusion of an abstract pushdown stack. In both cases, the implementations are able to create the illusion of an efficient abstract entity that can perform the requisite operations with just a few machine instructions. Throughout this book, our goal is to find data structures and efficient implementations for other important ADTs.
The linked-list implementation supports the illusion of a stack that can grow without bound. Such a stack is impossible in practical terms: at some point, new will raise an exception when the request for more memory cannot be satisfied. It is also possible to arrange for an array-based stack to grow and shrink dynamically, by doubling the size of the array when the stack becomes half full, and halving the size of the array when the stack becomes half empty. We leave the details of implementing such a strategy as an exercise in Chapter 14, where we consider the process in detail for a more advanced application. On the other hand, it is sometimes useful to have the client pass the maximum stack size to the constructor (for example, suppose that an application needs a huge number of small stacks).
The code in Programs 4.7 and 4.8 does not check for errors such as popping an empty stack, pushing onto a full stack, or running out of memory. To make our code robust for practical applications, we can modify it to check for such conditions and throw exceptions as appropriate (see Exercises 4.19 and 4.20). To keep our code compact and focus on algorithms, we generally do not show such error checks, but it is good programming practice to include them at every opportunity. Note that exceptions constitute a change in the interface, since clients should know which exceptions might be thrown; but fully capturing exception-handling in our client-interface-implementation scenario is a complicated matter.
Exercises
4.17 Give the contents of s[0], ..., s[4] after the execution of the operations illustrated in Figure 4.1, using Program 4.7.
test if empty by count, which should return the number of items currently in the data structure. Provide implementations for count for the array representation (Program 4.7) and the linked-list representation (Program 4.8).
4.19 Modify the array-based pushdown-stack implementation in the text (Program 4.7) to throw exceptions if there is not enough memory available from new to allocate the stack in the constructor, if the client attempts to pop when the stack is empty, or if the client attempts to push when the stack is full.
4.20 Modify the linked-list based pushdown-stack implementation in the text (Program 4.8) to throw exceptions if the client attempts to pop when the stack is empty, if the client attempts to push when the stack is full, or if there is no memory available from new for a push. Hint: You need to keep a counter that keeps track of the number of items in the stack.
4.21 Modify the linked-list based pushdown-stack implementation in the text (Program 4.8) to use an array of integers and an array of indices to implement the list (see Figure 3.7).
4.22 Write a linked-list based pushdown-stack implementation that keeps items on the list in order from least recently inserted to most recently inserted. You will need to use a doubly linked list.
4.23 Develop an ADT that provides clients with two different pushdown stacks. Use an array implementation. Keep one stack at the beginning of the array and the other at the end. (If the client program is such that one stack grows while the other one shrinks, this implementation will use less space than other alternatives.)
| Top |
EAN: 2147483647
Pages: 158