Observing the Object Difference
Is Figure 1-1 or Figure 1-2 a better visual depiction of an object?
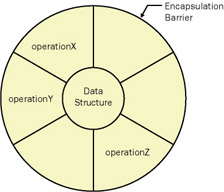
Figure 1-1: A graphical object model using UML graphical syntax.

Figure 1-2: A person as visual metaphor of an object.
A traditional developer will almost always pick the diagram in Figure 1-1. (Ken Auer calls this a soccer ball diagram because the segmentation resembles that of a soccer ball.) An object thinker, on the other hand, will pick the photograph. The soccer ball diagram has the advantage of familiarity to a traditional developer. It employs terms that are readily understood , and more important, it reinforces premises critical to the mindset of traditional developers and computer scientists. The diagram embodies Dykstra s definition of a program as data structures plus algorithms along with the idea of black box (enabled by the encapsulation barrier ) modularization .
Anthropomorphization ” a big word for the practice of projecting human characteristics onto objects ”is fundamental to object thinking, which accounts for the selection of the person depicted in the photograph by object thinkers. As a thinking device ”a metaphor or mental model ”the soccer ball diagram impedes object thinking by perpetuating old mental habits. For example, if the diagram is an accurate depiction of an object, what is the difference between an object and a COBOL program? There is none. A COBOL program encapsulates data (data division) and operations (procedure division) and allows communication among programs (communication division). Object development ”using this model ”will have a tough time being anything more than the creation of lots of tiny COBOL programs.
| Note | A COBOL program is, of course, a very large object. Inside the program is a lot of messy stuff that s not at all object-like. Object COBOL differs from COBOL primarily in its ability to create smaller programs ”closer to the scale of classes/objects in other programming languages ”and enhancement of the communication division. No substantial changes have been made ”object COBOL is merely COBOL rescaled. This is perhaps the best example of how the soccer ball diagram reinforces traditional program thinking. |
Another illustration of where the object difference might be observed : the answer to the question of how many objects (classes actually) are required to model a complete spectrum of typical business forms. Stated another way, how many objects are required to create any possible business form? Your objects will need the ability to collect a variety of information values (dollar amounts, alphabetic strings, dates, and so forth) and make sure that each item collected on the form is valid. When this question is posed as a class exercise, students, traditional developers all, typically list 10 to 20 objects, including all kinds of managers, controllers, and different widgets for each type of data to be collected on the form ( integerDataEntryField , stringDataEntryField , dateDataEntryField , and so on).
An object thinking solution would tend to limit the number of objects to four: a Form , acting as a collection; Strings , each label or text element being but an instance of this single class; entryFields , a widget object that displays itself and accepts input from a person; and selfEvaluatingRules , a special kind of object that embodies a business rule or, in this case, a data value validation rule. Both entryFields and Form objects would have a collection of selfEvaluatingRules that they could use to validate their contents.
| Note | selfEvaluatingRules will be discussed in detail in Chapter 10. For now, think of a self-evaluating rule as an expression (for example, widget contents = integer object) in the form of an ordered sequence of operators, variables, and constants. When the rule is asked to evaluate itself, each of its variables is asked to instantiate itself (become a known value), after which the rule resolves itself (applies the operators in the expression) to a final value ”a Boolean true or false, for example. A widget on a form is likely to have at least two rules, one to determine whether the entered value is of the correct class (for example, an integer or a character) and one to determine whether the value is consistent with the range of allowable values for that widget. If both of these rules resolve to true, the widget can say its contents have been validated . |
Here s a final example (for now) of places to observe the object difference: three different models of a customer . Figure 1-3a is an entity model: customer as data. Figure 1-3b is a UML class, and Figure 1-3c is an object model. Both Figure 1-3a and Figure 1-3b reflect typical thinking about customers as a collection of facts that must be remembered by the system. Both examples name the object and list its attributes. An attribute is the name of some characteristic, the value of which must be remembered (stored by) the system. The UML model (Figure 1-3b) differs from the entity model (Figure 1-3a) only because it also lists operations ”functions that manipulate the attributes ”collocated with the attributes themselves . The similarity between entity and UML models tends to ensure that the latter are subject to the same rules of normalization as entities. This means that attributes of an object tend to get dispersed among several different objects, increasing the total number of classes created to hold facts about customers.
Figure 1-3c models a customer only in terms of what it does ”what services it might provide. (The front- facing facet of the cube model contains a list of these behaviors or responsibilities.) What is known (by the system or anyone else) about the customer is not important to understanding the object itself. What the customer object needs to know to satisfy its advertised responsibilities is important and is evident (partly) in the left facet of the object cube depiction.
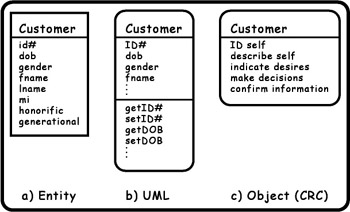
Figure 1-3: Customer depictions.
Entity modeling is most used in database applications where normalization is required to build the underlying database properly. UML models need not be normalized, but if you intend to fully utilize an automated tool, such as Rational s Rose, it becomes increasingly difficult to avoid normalization and the explosion of classes that results from applying normalization rules. Object models are seldom (if ever) concerned with normalization. The knowledge stored in an object (leftmost facet of the model in Figure 1-3c) might be arbitrarily complex and need not be related in any formal way to whatever bit of knowledge uniquely identifies the object.
| Note | There are advantages to modeling objects differently from entities. Here are two simple examples. First, it isn t necessary to create two different entities (classes) just because one object has an additional attribute or needs to know an additional piece of information in comparison with the other object, which reduces the total number of classes. Second, it s possible to aggregate a number of attributes into a single collection of values (which we will later call a valueHolder ). The object has an instance variable named description , for example, which contains a collection of discrete labeled values (dob:11/23/76, gender:F, height:63, and so forth). The collection is itself an object with behaviors that allow it to add and delete label : value without the need to redefine an entity and database schema and recompile the database. |
It s not necessary to fully accept the Whorf-Sapir hypothesis (see sidebar) to acknowledge that what and how we think varies with the language we employ . Every mathematician knows the difficulty of translating elegant equations into English prose . Likewise, every programmer who has used more than one programming language knows that statements easily and elegantly made in one language (Smalltalk or Lisp, perhaps) are cumbersome and verbose when translated into another (C++ or Java, perhaps). Developers are aware that different programming languages have very different idioms and styles despite being, deep under the covers, equivalent.
| |
Benjamin Lee Whorf and Edward Sapir advanced a theory (overstated here) to the effect that what you could and did think was determined by the language you spoke and that some languages allowed you to think better than others. Whorf was particularly interested in the Hopi language.
The Whorf-Sapir hypothesis is not fully accepted because most linguists and cognitive scientists believe that the hypothesis is flawed by overstatement and that the theory reflects some basic errors in the understanding of the Hopi language. However, most cognitive scientists do believe there is an element of truth in the hypothesis. In recent years , George Lakoff and others have advanced a similar theory with regard to language and thought. Lakoff s work centers on metaphor, a particular aspect of a language, and shows how metaphor influences what and how we think. Both Whorf and Lakoff are part of a school of philosophy and cognitive science focused on the role of language as a shaper of thought. The arguments for object thinking in this book reflect and are supported by this kind of cognitive science research.
| |
These simple examples, which I ll return to and expand upon later in this book, point to some of the differences resulting from object thinking, but other more general comments can also be made about object differences. Consider the continuum depicted in Figure 1-4. At the far left, the developer is thinking about the problem and its intrinsic nature, and at the far right, the developer is thinking of the most precise details of implementing a program. As we move from left to right, we tend to think using different languages. At the far left, we employ (or, since most of you are developers, you collaborate with someone who employs) natural language and the vocabulary of domain experts. At the far right, our vocabulary and syntax are essentially equivalent to an instruction set embedded on a processor chip.

Figure 1-4: Difference continuum.
Object thinking occurs across the continuum illustrated in Figure 1-4, but it s far more critical when engaged in activities to the left of the spectrum than to the right. In fact, if you apply object thinking correctly when you are conceptualizing and decomposing your problem space, you create a context that frames and guides your thinking as you move to activities on the right half of the spectrum. Object thinking and object decomposition yield a very different set of objects (modules) than would result from using traditional decomposition thinking based on an understanding of data structures and algorithms.
Objects exist in the world. They are observed by and interact with other objects ”some of them human beings ”in that world. Human objects come to have expectations about the nature and the behaviors of other objects in their world and are disconcerted if an object appears different or if it behaves in a manner contrary to their expectations. The naive or natural expectations of objects represent a kind of integrity ”what Alan Kay called a user illusion ”that must be respected.
The set of objects produced by object thinking must eventually be designed and implemented, ideally without violating the integrity of the objects themselves and without contravening any object principles or ideals. This poses a new set of problems for developers as they design classes and code methods . As we move rightward on the continuum, thinking is constrained by the languages (remember Whorf and Sapir) that we must employ. Programming languages can lead us far from object thinking. Even if the language is relatively benign (a pure OO programming language), it is still quite possible to write nonobject code.
As I ve said, although object thinking will yield observable differences across the thinking continuum, the differences will be far more evident, and their correctness will be essential, on the left. On the right of the continuum, the differences will tend to be collective rather than individual. For example, idiosyncrasies of syntax aside, it can be very difficult to differentiate a specific object-oriented method from a similarly specific procedural function. But the complete set of methods and the manner in which they are distributed among the objects (modules) will be quite different than would be the case in implementations conditioned upon traditional computer thinking.
| Note | I refer once again to COBOL programs to illustrate some differences. It was the case that a single COBOL program would encapsulate a bunch of functions, data structures, and some overall control logic. Object orientation is not achieved, however, merely by breaking up the monolith of a traditional COBOL program. Object COBOL implementations will use a greater number of objects (each one a separate program), but absent object thinking, each little program will be a mirror of the larger single program they collectively replaced : data structures, functions, and control logic. Without object thinking, the developer repeats old thinking habits on a smaller scale. One specific example of the perpetuation of this kind of thinking is the treating of data as something passive that must be protected, manipulated, and managed. In COBOL, data is defined separately from all the functions that operate on that data; it just sits there, and it is used (and frequently corrupted) by functions elsewhere in the program. Uniting data and procedure is far more complicated and difficult to do than is implied by the soccer ball model (discussed earlier), which simply shows the same old things stuffed in smaller containers. |
In what other ways will object thinking manifest itself? What metrics will be different? Dramatic and frequently claimed measures include the oft-cited reductions in lines of code and the amount of lead time required to deliver an application. Lines of code, for example, in a well-thought-out object application will be at least an order of magnitude fewer (sometimes two orders of magnitude). This means that a 1 million “line program, written conventionally by developers thinking like a computer, can be duplicated with object thinking in 100,000 lines of code or fewer. Time to delivery is reduced by at least 50 percent and often by as much as 70 percent. Projects scheduled to take 2 years to complete can be done in 8 to 12 months.
Dramatic results were routinely reported in the early days of object enthusiasm but have died off in recent years because, I would claim, of a return to dominance of old thinking habits. This does not mean that object thinkers reverted to form ”merely that as the number of people using OO programming languages and tools but not object thinking expanded dramatically, the collective ratio of object thinking to traditional thinking became smaller. When entire teams were object thinking and were almost certainly engaged in the rich iterative communication practices advocated by XP, the results were dramatic. If less than 10 percent of the team members are object thinking and the others are thinking traditionally, the overall effort will reflect the thinking style of the majority.
Mark Lorenz [3] and Jeff Kidd published a set of empirically derived metrics for successful object projects. (Although their book is somewhat dated, metrics derived from my own consulting experience ”which continues to the present ”are consistent with those reported by Lorenz and Kidd.) Following is a selection of metrics based on the results reported by Lorenz and Kidd but modified by my own consulting experience and observations. The debt to Lorenz and Kidd must be acknowledged , but they should not be held accountable for my interpretations and extensions.
-
Application size : between 1 and 40 stories, with stories being roughly equivalent to the story cards talked about in XP or one-fifth of the use cases advocated in UML.
-
Classes per application: fewer than 100, which are a mix of key classes (for example, business objects such as customer, account, inventory item) and support classes (for example, collections, strings, numbers , widgets). (See the sidebar "How Many Objects" in Chapter 4 for a discussion regarding the number of classes expected in a domain class hierarchy.)
-
Number of classes required to model an entire domain (business enterprise): approximately 1000.
-
Number of development iterations (conceive, develop, deploy, evaluate ”what Grady Booch called a roundtrip ): three, on average. Because XP iterates at the level of story and of release, this metric needs to be reinterpreted. But some variation of three cycles per defined effort seems consistent in both traditional and agile development.
-
Amount of code discarded at each iteration: 25 to 30 percent. This metric is a proxy for the learning that took place and the refactoring of code done at each iteration.
-
Responsibilities per class: average of seven. (We are using the term class in this context as an exemplar object ”so these responsibilities are really object responsibilities , a distinction that will be made clearer in Chapter 4, Metaphor: Bridge to the Unfamiliar. The same is true when we talk about methods.)
-
Methods (the blocks of code that are invoked to fulfill a responsibility) per class: average of 12.
-
Lines of code per method: average of fewer than seven for Smalltalk (15 for languages such as C++ and Java).
-
Percentage of methods requiring inline (comments) documentation: about 60. Practitioners of XP would think this a very high percentage. Refactoring, naming conventions, other idioms, and coding standards should move this figure much closer to 0 percent.
-
Average method complexity using the following weights for each occurrence of the noted item ”API calls 5.0, assignments 0.5, arithmetic operators or binary expressions 2.0, messages with parameters 3.0, nested expressions 0.5, parameters 0.3, primitive calls 7.0, temporary variables 0.5, messages without parameters 1.0: average fewer than 20 total points per method.
-
Number of case statements, nested conditionals, and nested branching statements in methods: zero (0). Lorenz and Kidd are quite careful to cite a range for all of their metrics ”a range that I have omitted for dramatic purposes. The nature of the domain being modeled , the application problem within the domain, and the relative skill of the developers will affect the metrics cited. Treat the numbers as if they were channel buoys ”markers placed in the middle of the channel. You do not have to hit the number, but sail too far to the side, and you risk running aground.
Failing to achieve the metrics reported by Lorenz is a clear sign of the absence of object thinking. In cases in which traditional thinking prevails, the lines of code, the number of methods, and the complexity of methods will increase dramatically. In cases in which thinking derived from database design and data modeling prevails, the number of classes required to model any domain and to build any application in that domain explodes. [4] Another sign of the ascendancy of traditional thinking over object thinking will be a plethora of classes with the word controller or manager embedded in the class name.
As the discussion of objects and object thinking proceeds, I ll note many other ways in which the object difference is observable. By the end of this book, you should be able to clearly differentiate between object thinking and traditional thinking solutions to problems. You should also be able to distinguish between good and better object solutions to a problem ”recognizing that design always yields a spectrum of potential solutions to any problem and that evaluation of those solutions is partially subjective . Given that observable and real differences exist between designs that result from object thinking and from traditional thinking, what accounts for those differences? A full answer will require the rest of this book, but I ll introduce one essential difference immediately.
[3] Lorenz, Mark, and Jeff Kidd. Object-Oriented Software Metrics . Englewood Cliffs, NJ: Prentice Hall. 1994. ISBN 0-13-179292-X.
[4] One of the largest object projects of which I am aware through my consulting practice was tainted by datacentrism. At the inception of the project, management mandated the translation of a recently completed enterprise data model into the domain class hierarchy ”each entity in the data model became a class in the object model. Despite using the right language, having some of the best object developers available in the country at that time, and having significant corporate support, the project took two to three times as long to complete as necessary, cost far more than it should have, and encountered numerous problems and complications that could have been avoided if the development team had been allowed to rethink what they were doing using object thinking principles. Management deemed the project successful because it was completed with no major overruns and saved the company a lot of money. Compared to what might have been, however, it was a dismal failure.
EAN: 2147483647
Pages: 88