| This section explains the architecture of the IP instance in the Linux kernel. We will use the path a packet takes across the IP layer to introduce the basic properties of the Internet Protocol. We assume that this is a normal IP packet without special properties, to ensure that our explanations will be clear and easy to understand. All special functions of the Internet Protocol, such as fragmenting and reassembling, source routing, multicasting, and so on, will be described in the next chapters. The objective of this section is to introduce the fundamental operation of the IP implementation in Linux, to be able to better understand more complex parts later on. This section also serves as an entry point into the other chapters of this book, because each packet passes the IP layer, where it can take a particular path (e.g., across a firewall or a tunnel). It is necessary to understand how the Internet Protocol is implemented in the Linux kernel to understand later chapters. An IP packet can enter the IP instance in three different places: Packets arriving in a computer over a network adapter are stored in the input queue of the respective CPU, as described in Chapter 6. Once the layer-3 protocol in the data-link layer has been determined (which is ETH_PROTO_IP in this case), the packets are passed to the ip_rcv() function. The path these packets take will be described in Section 14.2.1. The second entry point for IP packets is at the interface to the transport protocols. These are packets used by TCP, UDP, and other protocols that use the IP protocol. They use the ip_queue_xmit() function to pack a transport-layer PDU into an IP packet and send it. Other functions are available to generate IP packets at the boundary with the transport layer. These functions and the operation of ip_queue_xmit() will be described in Section 14.2.2. With the third option, the IP layer generates IP packets itself, on the Internet Protocol's initiative. These are mainly new multicast packets, new fragments of a large packet, and ICMP or IGMP packets that don't include a special payload. Such packets are created by specific methods (e.g., icmp_send()). (See Section 14.4.)
Once a packet (or socket buffer) has entered the IP layer, there are several options for how it can exit. We generally distinguish two different roles a computer can assume with regard to the Internet Protocol, where the first case is a special case of the second: End system: A Linux computer is normally configured as an end system it is used as a workstation or server, assuming primarily the task of running user applications or providing application services. Also, a Web server and a network printer are nothing but end systems (with regard to the IP layer). The basic property of end systems is that they do not forward IP packets. This means that you can recognize an end system easily by the fact that it has only one network adapter. Even a system that has several network accesses can be configured as a host, if packet forwarding is disabled. Router: A router passes IP packets arriving in a network adapter to a second network adapter. This means that a router has several network adapters that forward packets between these interfaces. When packets arrive in a router, there are generally two options: they can deliver packets locally (i.e., deliver them to the transport layer) or they can forward them. The first case is identical with the procedure of packets arriving in an end system, where packets are always delivered locally. Consequently, a router can be thought of as a generalization of an end system, with the additional capability of forwarding packets. In contrast to end systems, generally no applications are started in routers, to ensure that packets can be forwarded as fast as possible.
Linux lets you enable and disable the packet-forwarding mechanism at runtime, provided that the forwarding support was integrated when the kernel was created. The directory /proc/sys/net/ipv4/ includes a virtual file, ip_forward. You will see in Appendix B.3 that there is a way to change system settings from within the proc directory. If a 0 is written to this file, then packet forwarding is disabled. To activate IP packet forwarding, you can use the command echo '1' > /proc/sys/net/ipv4/ip_forward. Figure 14-4 shows the path an IP packet takes across the Internet Protocol implementation in Linux. The gray ovals represent invoked functions, and the rectangles show the position of the netfilter hooks in the Internet Protocol. Figure 14-4. Architecture of the Internet Protocol implementation in Linux. 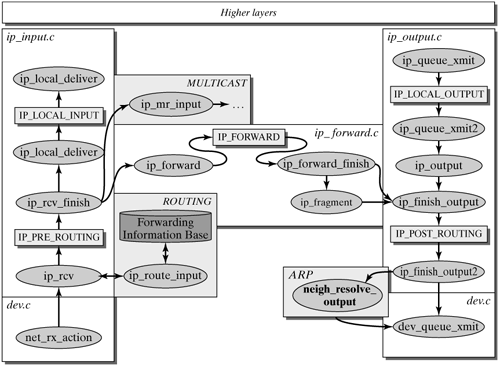
The following sections describe different paths a packet can take across the IP implementation in the Linux kernel. We begin with incoming packets, which have to be either forwarded or delivered locally. The next section describes how packets are passed from the transport layer to IP. 14.2.1 The Path of Incoming IP Packets Chapter 6 introduced the path of an incoming packet up to the boundary of layer 3. Once the NET_RX tasklet has removed a packet from the input queue, netif_rx_action() chooses the appropriate layer-3 protocol. Next, the Internet Protocol is selected, and the ip_rcv() function is invoked on the basis of the identifier in the Ethernet protocol field (ETH_PROTO_IP) or from appropriate fields of other MAC transmission protocols. ip_rcv() | net/ipv4/ip_input.c |
ip_rcv(skb, dev, pkt_type) does some work for the IP protocol. First, the function rejects packets not addressed to the local computer. For example, the promiscuous mode allows a network device to accept packets actually addressed to another computer. Such packets are filtered by the packet type (skb->pkt_type PACKET_OTHERHOST) in the lower layers. Subsequently, the basic correctness criteria of a packet are checked: If the actual packet size does not match the information maintained in the socket buffer (skb->len), then the current packet data range is adapted by skb_trim(skb, iph->total_len). (See Section 4.1.) Now that the packet is correct, the netfilter hook NF_IP_PRE_ROUTING is invoked. Netfilter allows you to extend the procedure of various protocols by specific functions, if desired. Netfilter hooks always reside in strategic points of certain protocols and are used, for example, for firewall, QoS, and address-translation functions. These examples will be discussed in later chapters. A netfilter hook is invoked by a macro, and the function following the handling of the netfilter extension is passed to this macro in the form of a function pointer. If netfilter was not configured, then the macro ensures that there is a direct jump to this follow-up function. We can see in Figure 14-4 that the procedure continues with ip_rcv_finish(skb). ip_rcv_finish() | net/ipv4/ip_input.c |
The function ip_route_input() is invoked within ip_rcv_finish(skb) to determine the route of a packet. The skb->dst pointer of the socket buffer is set to an entry in the routing cache, which stores not only the destination on the IP level, but also a pointer to an entry in the hard header cache (cache for layer-2 frame packet headers), if present. If ip_route_input() cannot find a route, then the packet is discarded. In the next step, ip_rcv_finish() checks for whether the IP packet header includes options. If this is the case, then the options are analyzed, and an ip_options structure is created. All options set are stored in this structure in an efficient form. Section 14.3 describes how IP options are handled. Finally in ip_rcv_finish(), the procedure of the IP protocol reaches the junction between packets addressed to the local computer and packets to be forwarded. The information about the further path of an IP packet is stored in the routing entry skb->dst. Notice that a trick often used in the Linux kernel is used here. If a switch (variable value) is used to select different functions, then we simply insert a pointer to each of these functions. This saves us an if or switch instruction for each decision of how the program should continue. In the example used here, the pointer skb->dst->input() points to the function that should be used to handle a packet further: ip_local_deliver() is entered in the case of unicast and multicast packets that should be delivered to the local computer. ip_forward() handles all unicast packets that should be forwarded. ip_mr_input() is used for multicast packets that should be forwarded.
We can see from the above discussion that a packet can take different paths. The following section describes how packets to be forwarded are handled (skb->dst->input = ip_forward). Subsequently, we will see how skb->dst->input = ip_local_deliver handles packets to be delivery locally. Forwarding Packets If a computer has several network adapters, and if packet IP forwarding is enabled (/proc/sys/net/ipv4/ip_forward 1), then packets addressed to other computers are handled by the ip_forward() function. This function does all the work necessary for forwarding a packet. The most important task routing was already done in ip_input(), because it is necessary to be able to discover whether the packet is to be delivered locally or has to be forwarded. ip_forward() | net/ipv4/ip_forward.c |
The primary task of ip_forward(skb) is to process a few conditions of the Internet Protocol (e.g., a packet's lifetime) and packet options. First, packets not marked with pkt_type == PACKET_HOST are deleted. Next, the reach of the packet is checked. If the value in its TTL field is 1 (before it is decremented), then the packet is deleted. RFC 791 specifies that, if such an action occurs, an ICMP packet has to be returned to the sender to inform the latter (ICMP_TIME_EXCEEDED). Once a redirect message has been checked, if applicable, the socket buffer is checked to see if there is sufficient memory for the headroom. This means that the function skb_cow(skb, headroom) is used to check whether there is still sufficient space for the MAC header in the output network device (out_dev->hard_header_len). If this is not the case, then skb_realloc_headroom() creates sufficient space. Subsequently, the TTL field of the IP packet is decremented by one. When the actual packet length (including the MAC header) is known, it is checked for whether it really fits into the frame format of the new output network device. If it is too long (skb->len > mtu), and if no fragmenting is allowed because the Don't-Fragment bit is set in the IP header, then the packet is discarded, and the ICMP message ICMP_FRAG_NEEDED is transmitted to the sender. In any case, the packet is not fragmented yet; fragmenting is delayed. The early test for such cases prevents potential Don't-Fragment candidates from running through the entire IP protocol-handling process, only to be dropped eventually. ip_forward_finish( ) | net/ipv4/ip_forward.c |
We can see in Figure 14-4 that the ip_forward() function is split into two parts by a netfilter hook. Once the NF_IP_FORWARD hook has been processed, the procedure continues with ip_forward_finish(). This function has actually very little functionality (unless FASTROUTE is enabled). Once the IP options, if used, have been processed in ip_forward_options(), the ip_send() function is invoked to check on whether the packet has to be fragmented and to eventually do a fragmentation, if applicable. (See Section 14.2.3.) ip_send() | include/net/ip.h |
ip_send(skb) decides whether the packet should be passed to ip_finish_output() immediately or ip_fragment() should first adapt it to the appropriate layer-2 frame size. (See Section 14.2.3.) ip_finish_output() | net/ipv4/ip_output.c |
ip_finish_output(skb) initiates the last tasks of the Internet Protocol. First, the skb->dev pointer is set to the output network device dev, and the layer-2 packet type is set to ETH_P_IP. Subsequently, the netfilter hook NF_IP_POST_ROUTING is processed. The exact operation of netfilter and the set of different hooking points within the Internet Protocol are described in Section 19.3. It is common for netfilter hooks to continue with the inline function ip_finish_output2() after their invocation. ip_finish_output2() | net/ipv4/ip_output.c |
At this point, the packet leaves the Internet Protocol, and the Address Resolution Protocol (ARP) is used, if necessary. Chapter 15 describes the Address Resolution Protocol. For now, it is sufficient to understand the following: If the routing entry used (skb->dst) already includes a reference to the layer-2 header cache (dst->hh), then the layer-2 packet header is copied directly into the packet-data space of the socket buffer, in front of the IP packet header. The output() function used here is dev_queue_xmit(), which is invoked if the entry in the hardware header cache is valid. dev_queue_xmit() ensures that the socket buffer is sent immediately over the network device, dev. If there is no entry in the hard header cache yet, then the corresponding address-resolution routine is invoked, which is normally the function neigh_resolve_output().
The procedure described above was optimized so that a packet can pass the router quickly without special options. However, it became clear where there are junctions to the corresponding handling routines (e.g., netfilter, multicasting, ICMP, fragmenting, or IP packet options). Delivering Packets Locally The previous section described the route a packet travels when it has to be forwarded. If ip_route_input() is the selected route, then the packet is addressed to the local computer. In this case, branching is to ip_local_deliver() rather than to ip_forward(). This section describes the path of packets to be delivered locally. At this point, too, instead of using a conditioned if instruction to distinguish the two options, a pointer (skb->dst->input()) is used, which points to ip_local_deliver() in this case. At the end of ip_input(), the procedure continues with the packet's local delivery. ip_local_deliver() | net/ipv4/ip_input.c |
The first (and only) task of ip_local_deliver(skb) is to reassemble fragmented packets, using ip_defrag(). Section 14.2.3 describes in detail how packets are fragmented and defragmented. For now, it is sufficient to understand that all fragments of a packet are collected over a certain period of time, until all fragments of an IP datagram have arrived, so that they can be passed upwards as a whole. Subsequently, it is almost mandatory to call a netfilter hook (NF_IP_LOCAL_IN) when the procedure continues with the ip_local_deliver_finish() function. ip_local_deliver_finish() | net/ipv4/ip_input.c |
The packet has now reached the end of the Internet Protocol processing. It is checked to see whether the packet is intended for a RAW-IP socket; otherwise, the transport protocol has to be determined for further processing (demultiplexing). All transport protocols are managed in the ipprot hash table on the IP layer in Linux. At the end of the IP processing, there is now a special data structure, instead of simple query sequences and simple commands. The reason lies mainly in the nature of the Internet Protocol. Unless a packet includes special options, IP processing is very simple, and so IP is efficient and easy to implement. The complexity of IP packet options normally necessitates several more complex programming methods. The protocol ID of the IP header modulo (MAX_INET_PROTOS - 1) is used to calculate the hash value in the ipprot hash table. The hash table is organized so that there are no collisions. If a new transport protocol would ever have to be integrated, then the assignment in the hash table should be checked. If the corresponding transport protocol can be found, then the appropriate handling routine (handler) of the protocol is invoked. The following handling routines are most common: tcp_v4_rcv(): Transmission Control Protocol (TCP) udp_rcv(): User Datagram Protocol (UDP) icmp_rcv(): Internet Control Message Protocol (ICMP) igmp_rcv(): Internet Group Management Protocol (IGMP)
If no transport protocol can be found, then the packet either is passed to a RAW socket (if there is one) or it is dropped and an ICMP Destination Unreachable message is returned to the sender. The chapters dealing with the TCP and UDP transport protocols describe how a packet is further handled in the transport layer. Chapter 17 describes IGMP packets, and ICMP packets are discussed in Section 14.4. The following section describes the path a packet takes as it passes from the transport layer to the Internet Protocol for transmission. 14.2.2 Transport-Layer Packets Packets created locally and passed from the transport layer to the Internet Protocol are handled in a way totally separate from the procedures introduced so far. (See Figure 14-4.) First of all, there is not just one single function available to the transport layer, but several, including ip_queue_xmit() and ip_build_and_send_pkt(). Each of these functions is specialized and optimized for a specific use. This section considers only the ip_queue_xmit() function, because this is the one normally used for data packets; ip_build_and_send_pkt() is used for SYN or ACK packets that do not transport payload. Figure 14-5. Hash table used to multiplex transport protocols. 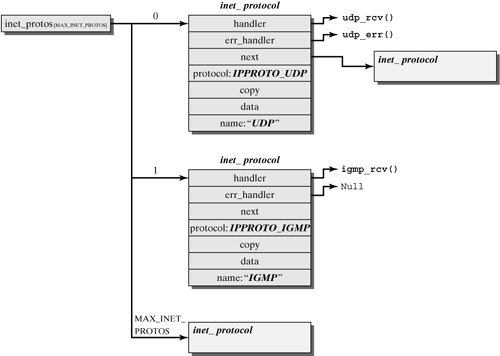
ip_queue_xmit() | net/ipv4/ip_output.c |
At the beginning, ip_queue_xmit(skb) checks for whether the socket structure sk->dst includes a pointer to an entry in the routing cache and, if so, whether this pointer is actually valid. The route for a packet is stored in the skb->sk socket structure, because all packets of a socket go to the same destination. Storing a reference means that expensive searches for routes can be avoided. If no route is present yet (e.g., when the first packet of a socket is ready), then the ip_route_output() function is used to choose a route. Once this route has been entered in the routing cache, its use counter is incremented to ensure that the route is not inadvertently deleted as long as there is still a socket buffer referencing it. Subsequently, the fields of the IP packet are filled (version, header length, TOS field, fragment offset, TTL, addresses, and protocol). Next, ip_options_build() handles options, if present, and the netfilter hook NF_IP_LOCAL_OUTPUT is invoked. ip_queue_xmit2() | net/ipv4/ip_output.c |
The next function, ip_queue_xmit2(dev) of the netfilter hook NF_IP_LOCAL_OUTPUT, sets the output network device as specified in the routing cache entry. Now it is necessary to check once more how much headroom is available in the socket buffer, although the buffer reservation is already complete. Also, it is necessary to learn the network device used and its MTU size. Unfortunately, it can happen that a socket buffer was created for the device dev1 (with mtu1), but the route has changed in the meantime, and the packet is sent over device dev2 with a smaller MTU. This means that, infrequently, the available headroom has to be increased. Subsequently, the packet is checked for fragmentation, and the checksum is computed (ip_send_check(iph)). Subsequently, the packet created locally crosses the path for forwarding packets. The function pointer dst->output(), which is set during the routing process, causes the ip_output() function to be invoked, which executes the last steps in the Internet Protocol, primarily guiding the packet across the netfilter hook NF_IP_POST_ROUTING. 14.2.3 Fragmenting Packets The Internet Protocol has to be capable of adapting the size of IP packets to the respective network type in order to be able to send IP datagrams over any type of network. Each network has a maximum packet size, which is called Maximum Transfer Unit (MTU). Only packets within this size can be transported over the network. For example, if packets have to be sent over a token-ring network, they must not be larger than 4500 bytes, and 1500 bytes must not be exceeded by Ethernet packets. If the MTU of a transmission medium is smaller than the size of a packet, then the packet has to be split into smaller IP packets. However, it is not sufficient to let the transport-layer protocols transmit smaller packets independently. The reason is that a packet can traverse several networks with a different MTU each on the way from the source host to the destination host. This means that we need a more flexible method that can create smaller packets, also in a router, on the IP layer. This method is called fragmenting. Fragmenting means that the IP protocol in each IP computer (router or end system) has to be capable of splitting incoming packets, if necessary, and to transport them over a subnetwork (with a smaller MTU) all the way to the destination computer. In addition, each end system must be able to put these fragments together to rebuild the original packet. This method is called reassembling. Each fragment of a split IP datagram is treated like an independent IP packet and contains a complete IP packet header. The Fragment ID field in the IP packet header can be used to identify all fragments of an IP datagram and to allocate them to their original datagram. However, the Fragment ID field alone is not a unique key to identify fragments arriving from different computers. For this reason, the following packet header fields are used additionally sender address, destination address, and protocol. All the fragments of a datagram can take different paths to travel to the destination computer, and they may be fragmented more than once along these paths. The position of a fragment's data within the original IP datagram is marked by the Fragment Offset field. All fragments, except the last one, have the MF (More Fragments) bit set, which means that more fragments are to follow. Figure 14-6 shows the example of an IP datagram that has to be fragmented several times. Figure 14-6. Fragmenting an IP datagram. 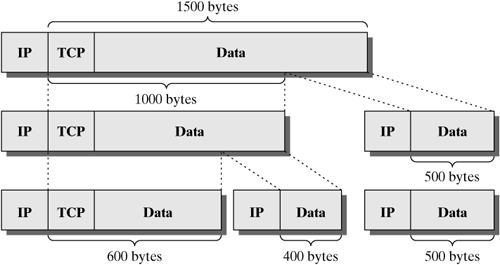
We will describe below how fragmenting and reassembling of IP datagrams is implemented in the Linux kernel. Remember that IP packets can be fragmented in each IP node along the path to the destination (router or end system), but can be reassembled only in the destination computer. Fragmenting Large IP Datagrams ip_fragment() | net/ipv4/ip_output.c |
ip_fragment(skb, output) is responsible for fragmenting an IP datagram into smaller IP packets, if the IP datagram is too big to be transmitted over the network device. The size for the new smaller packets is selected so that they do not exceed the maximum frame length of the transmission medium. First, the maximum packet size is computed, and then IP fragments are created in a while loop until the datagram has been completely divided into smaller packets. Next, alloc_skb() is used to create a new socket buffer for each new fragment. Initially, the IP packet header is copied from the original packet to the new one, and then the payload to be transported in this fragment is copied to the fragment. It should be mentioned once more that previously fragmented datagrams can be fragmented again in one or more routers later along the path. Subsequently, the new value for the Fragment Offset field has to be set in the new fragment. This field specifies the position of payload in the original IP datagram. Also, the MF bit has to be set, unless it is the last fragment. Before the output() function (pointer to the transmit function set in the routing process) can send the packet, the function ip_options_fragment() handles IP options, if present, and ip_send_check() computes the checksum. Once all fragments have been created, the original packet is released by kfree_skb(). Collecting and Reassembling Packets Fragmented IP datagrams are reassembled in the end system only. To this end, the function ip_local_deliver() passes all fragmented IP packets to ip_defrag(). The fragments are then managed in the fragment cache, until either all fragments of a datagram have arrived, so that the packet can be delivered to the local machine, or the maximum wait time for the fragments of a datagram (ipfrag_time, ~30 seconds) has expired, which means that the datagram will be discarded. The fragment cache consists of a hash table with ipq structures. Each of these ipq structures represents a fragmented IP datagram. The individual fragments of the datagram are collected in a linked list (fragments). All fragments of a datagram are ordered in the same sequence as they occur in the original packet. (See Figure 14-7.) Figure 14-7. A fragment cache manages all incoming IP fragments. 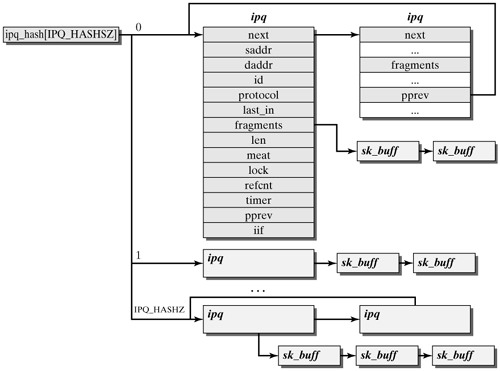
The parameters of the ipq structure have the following meaning: next and pprev are used to link ipq structures in a hash row. This means that this is a doubly linked list and a linear collision resolution in the hash table. The saddr, daddr, id, and protocol elements are keys for the hash function and the allocation of incoming fragments to their IP datagrams. last_in stores a flag that specifies whether all fragments have arrived and whether the first and the last fragments of a datagram have arrived. fragments is a list of linked socket buffers that stores all incoming fragments in the sequence required later to reassemble the complete datagram. len specifies the length of the original IP datagram, and meat specifies the number of bytes already stored in the fragment cache. When meat reaches the value of len, then all fragments of the datagram have arrived, and the fragment can be reassembled. lock is used to protect against parallel operations on the ipq data structure. timer is a pointer to a timer_list structure. The associated timer restarts when the IPFRAG_TIME interval expires, and it checks for whether all fragments have arrived. iif contains an index to the network device and is used for ICMP replies.
The following functions are used to reassemble fragmented IP datagrams: ipq_unlink() | net/ipv4/fragment.c |
ipq_unlink(qp) removes the ipq entry from the fragment cache referenced by the qp pointer. The counter for arrived fragments, ip_frag_nqueues, is decremented by 1. ipq_frag_destroy() | net/ipv4/fragment.c |
ip_frag_destroy(qp) releases an ipq fragment list. First, frag_kfree_skb() releases all socket buffers of individual fragments. Subsequently, frag_free_queue() releases the ipq structure of the fragment cache. ip_evictor() | net/ipv4/ip_fragment.c |
ip_evictor() is invoked by ip_defrag() when fragmented packets use too much memory. Normally, the threshold for maximum memory in the fragment cache (sysctl_ipfrag_high_thresh) is 256 Kbytes. Next, all hash rows of the fragment cache are checked within this function, and entries are deleted. More specifically, ipq structures and their socket buffers are deleted until the bottom threshold (normally 192 Kbytes) is reached. The two threshold values, ipfrag_high_thresh and ipfrag_low_thresh, and the maximum wait time for fragments, ipfrag_time, can be changed from within the proc directory (/proc/sys/net/ipv4). ip_expire() | net/ipv4/ip_fragment.c |
ip_expire() is a handling routine for the timer that starts for the fragments of an IP datagram. If this timer expires before all fragments of the packet have arrived, the entry in the fragment cache is deleted. This function does nothing, if all fragments have been received (COMPLETE). If some fragments are still missing, but at least the first one is present, then an ICMP error message of the type (ICMP_TIME_EXCEEDED/ICMP_EXC_FRAGTIME) is sent, and then the IP datagram is discarded. ip_frag_create() | net/ipv4/ip_fragment.c |
ip_frag_create(hash, iph) creates a new entry in the fragment cache and uses the parameters from the IP packet header of the fragment that just arrived to initialize this entry. The new entry represents an IP datagram that could not be transmitted fully and had to be fragmented. This entry is created when the first fragment of an IP datagram arrives and is held in the fragment cache until either the wait time for all fragments (IP_FRAG_TIME) expires or all fragments of that IP datagram have arrived. ip_find() | net/ipv4/ip_fragment.c |
ip_find(iph) searches the fragment cache for the ipq entry for an IP datagram with the iph packet header. To this end, ipqhashfn() is used to compute the hash value of this entry from the sender address, destination address, protocol ID, and fragment IP from the packet header fields. Based on these parameters, different fragmented datagrams can be distinguished, and incoming fragments can be allocated to each datagram. Collisions of several ipq structures with identical hash values are resolved linearly in a doubly linked list. (See Figure 14-7.) If ip_find() cannot find a matching entry for the iph fragment, then a new ipq entry is created in the fragment cache (ip_frag_create()). ip_frag_queue() | net/ipv4/fragment.c |
ip_frag_queue(qp, skb) orders a new fragment, as it arrives, within the queue of fragments for an IP datagram (represented by the ipq structure qp). The function checks first for whether the datagram is complete, which would mean that a new fragment is a duplicate. If this is not the case, the position (offset and end) of the fragment in the original IP datagram is computed from the Fragment Offset parameter in the IP packet header. Subsequently, the MF flag is used to check on whether this is the last fragment of a datagram (LAST_IN is set). Subsequently, the list of received fragments (pq->fragments) is searched for the correct position, and the socket buffer is placed at this position. The meat parameter in the ipq structure of the datagram is increased by the length corresponding to the fragment just added. As mentioned earlier, the meat parameter specifies the number of bytes received for a fragmented IP datagram. ip_frag_reasm() | net/ipv4/ip_fragment.c |
This function is invoked by ip_defrag(); it reassembles all fragments of a packet (qp->len == qp->meat) arrived and treats them as a single IP datagram. First, a new socket buffer with a headroom of length qp->len is created, and the IP datagram header is initialized. Next, the IP payload of each single fragment is copied to the headroom of the new socket buffer. ip_defrag() | net/ipv4/ip_fragment.c |
The ip_defrag(skb) method is invoked in ip_local_deliver() for each IP fragment. As described in Section 14.2.1, this path of the Internet Protocol is taken only by packets to be delivered to the local machine (i.e., fragmented IP datagrams are reassembled in the destination system). The first thing here is to check on whether there is sufficient buffer space in the fragment cache for the new fragment. If this is not the case, then ip_evictor() removes entries until the bottom threshold value, sysctl_ipfrag_low_thresh, is reached. Subsequently, ip_find() searches the fragment cache for the relevant entry. As mentioned earlier, a new ipq structure is created as soon as the first fragment of an IP datagram arrives. Finally, ip_frag_queue() adds the new fragment to the list of present fragments. As soon as all fragments of the IP datagram have arrived, which can be checked by pq->len == pq->meat, reassembly of the datagram (ip_frag_reasm()) can start. 14.2.4 Data of the IP Instance The primary task of an IP instance (in a router) is to forward IP packets. To this end, several network devices have to be configured for the IP instance. These network devices (INET devices), which are to be used by the Internet Protocol, are managed mainly by the functions stored in the file net/ipv4/devinet.c. We will call these network devices IP network devices in the further course of our discussion. This section is aimed at briefly introducing the structure of IP network-device management. This point represents the binding member between several functions of the Internet Protocol. For example, the data structures introduced below can be used to manage IP addresses and network devices of the IP instance and active multicast groups or different IP configuration parameters (Packet forwarding permitted?, Accept redirect packets?, etc.). The data structure in_device represents the starting point for IP network device management: struct in_device | include/linux/inetdevice.h |
An in_device structure is created for each network device that was configured for the Internet Protocol. This structure manages the configuration data for this IP network device. Figure 14-8 shows that the net_device structures of IP network devices have an ip_ptr parameter each, which references the pertaining in_device structure. There is no explicit list for IP network devices. The list is accessed with dev_base. Figure 14-8. Data structures to manage IP network devices and their parameters. 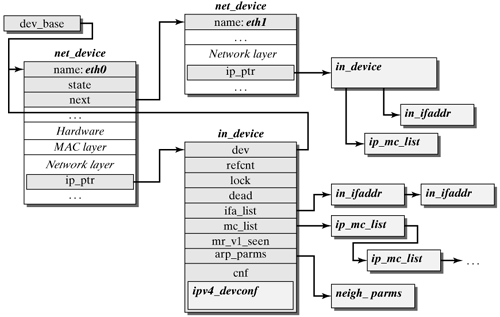
The file net/ipv4/devinet.c includes functions to manage IP network devices, including inetdev_init() to initialize an IP network device. The structure and the elements of the in_device structure are as follows: struct in_device { struct net_device *dev; atomic_t refcnt; rwlock_t lock; int dead; struct in_ifaddr *ifa_list; /* IP ifaddr chain */ struct ip_mc_list *mc_list; /* IP multicast filter chain */ unsigned long mr_v1_seen; struct neigh_parms *arp_parms; struct ipv4_devconf cnf; };
dev points to the net_device structure of the network device configured for the Internet Protocol. refcnt stores the number of references to this structure, orthe number of instances currently used by this IP network device. The refcnt variable essentially is changed by the functions in_dev_get() and in_dev_put(). (Both are defined in <linux/inetdevice.h>.) lock is used to protect against errors caused by parallel manipulation in the in_device structure. dead shows whether the IP network device is still valid. ifa_list points to a list of in_ifaddr structures, which stores the IP addresses of this IP network device. This is a list, because Linux lets you allocate more than one IP address to a network device (alias function). In addtion to the IP address (ifa_address), the in_ifaddr structure stores other parameters (e.g., the subnet mask (ifa_mask), the broadcast address (ifa_address), etc.). The content of the in_ifaddr structure is as follows: struct in_ifaddr { struct in_ifaddr *ifa_next; struct in_device *ifa_dev; u32 ifa_local; u32 ifa_address; u32 ifa_mask; u32 ifa_broadcast; u32 ifa_anycast; unsigned char ifa_scope; unsigned char ifa_flags; unsigned char ifa_prefixlen; char ifa_label[IFNAMSIZ]; };
mc_list is a list consisting of ip_mc_list structures. Each element in this list stores information for an IP multicast group to which the IP instance is currently subscribed, and receives it over the current network device. Section 17.4.1 describes the content of the ip_mc_list structure. mr_vl_seen is used by IGMP. (See Section 17.3). arp_parms points to a structure of the type neigh_parms, which stores the most important parameters of the ARP protocol. (See Chapter 15.) cnf points to an ipv4_devconf structure, which stores important settings for the IP instance. ipv4_devconf is described below.
struct ipv4_devconf | include/linux/inetdevice.h |
The ipc4_devconf data structure can be used to activate or deactivate various properties of the IP instance for an IP network device. For this purpose, the proc directory /proc/sys/net/ipv4/conf includes a subdirectory for each IP network device, from which the properties mentioned below can be set. These properties will then be described briefly below. Appendix B discusses all proc entries for the Internet Protocol. struct ipv4_devconf { int accept_redirects; int send_redirects; int secure_redirects; int shared_media; int accept_source_route; int rp_filter; int proxy_arp; int bootp_relay; int log_martians; int forwarding; int mc_forwarding; int tag; int arp_filter; void *sysctl; };
accept_redirects accepts ICMP redirect packets. send_redirects enables the transmission of ICMP redirect packets. secure_redirects accepts ICMP redirect messages. accept_source_route accepts Source Route packets. rp_filter disables the sender IP address check. proxy_arp supports an ARP proxy. log_martians enables or disables the logging of "strange" addresses ("Martians"?see Section 16.2.2). forwarding enables this network device to forward packets. mc_forwarding enables multicast routing or forwarding over this IP network device.
14.2.5 Auxiliary Functions for the Internet Protocol The functions introduced in the previous sections operate mainly in the data path of the Internet Protocol: They process incoming IP packets. In addition to these functions, there are other things to be done in the Internet Protocol that do not directly relate to socket buffers or IP packets. These auxiliary functions are introduced below. Managing Transport Protocols The Internet Protocol operates on the network layer and offers an unreliable datagram service for the transport layer. In general, the TCP and UDP protocols are used in the transport layer. However, a layer-based architectural model should also allow us to use our own protocols. The Linux network architecture allows you to do that. You can register and use new protocols on top of the IP layer. In connection with kernel modules, this represents a flexible and highly dynamic property of the Linux network architecture. The Linux kernel includes two functions, inet_add_protocol() and inet_del_protocol(), which will be described below, to manage transport-layer protocols. Appendix F includes an example for a rudimentary transport protocol, which does nothing but output the length of incoming transport-layer PDUs. inet_add_protocol() | net/ipv4/protocol.c |
All protocols arranged immediately on top of the Internet Protocol are managed in a hash table, inet_protos. inet_add_protocol(prot) registers a new protocol for the transport layer and adds it to the inet_protos hash table. The required protocol information is passed in the prot structure of the type inet_protocol (as shown in Figure 14-5): handler() is a function pointer to the entry function of the transport protocol (handling routine), for example the tcp_v4_rcv() for TCP. The parameters passed here include the socket buffer and the length of the transport-layer PDU. Appendix F includes an example of a very simple transport protocol. All it does is output the length of a PDU. err_handler() is a handling routine for error cases. It is invoked only once in the current implementation, in the method icmp_unreach(). next is used to link inet_protocol structures in a hash table. id is the protocol identifier of the registered protocol. In the future, if an IP packet with this identifier in the protocol field of the IP packet header arrives, then it is passed to the handler() handling routine. If several protocols with the same id are registered, then a copy of the socket buffer is passed to each of these protocols. The copy bit specifies whether another protocol is registered with the same protocol ID. If a protocol with the same protocol ID is already registered when you register a new protocol, then the new protocol is also added to the hash table, and the copy bit of all previous protocols with the same ID is set to one. In this case, all protocols with the same ID get a copy of the packet. data points to private data of the protocol, if present. However, it is not used by any of the implemented protocols (TCP, UDP, ICMP, and IGMP). name stores the name of the protocol in a string.
The Linux kernel currently implements four protocols on the transport layer, where only TCP and UDP are actually true transport protocols. Though ICMP and IGMP also use IP to exchange data, they are normally thought of as belonging to the network layer. inet_del_protocol() | net/ipv4/protocol.c |
inet_del_protocol(prot) removes the protocol, together with the passed pointer to an inet_protocol structure, from the hash table inet_protos. If there is a second protocol with the same protocol ID, then the copy bit of this protocol is checked and deleted, if applicable. Useful Functions in_ntoa() | net/ipv4/utils.c |
in_ntoa(in) converts the IP address into the dotted decimal form, which is easier to read for humans (i.e., the 32-bit address 0x810D2A75 is converted into the string 129.13.42.117). in_aton() | net/ipv4/utils.c |
in_aton(str) converts the string str into a 32-bit IP address. |