2.8 Approximate String Matching
| You've most likely learned how to use regular expressions to find any of a set of possible patterns in a string. Approximate string matching is similar: an approximate string matching algorithm finds any of a set of possible patterns in a string. However, the two approaches are quite different in their capabilities and their ease of use. Simply stated, approximate string matching can find many close matches to a pattern that would be very tedious to specify using regular expressions. 2.8.1 Edit DistanceThere are several ways to measure the distance between two strings, and our algorithm will use one such measure. Some variants of this measure are considered in the exercises at the end of the chapter. Our algorithm uses the idea of edit distance to measure the similarity between two strings. The idea is quite simple. Assume that there are three things you can do to alter a string:
Now, let's say that every time you make any of these three edits, you incur an edit cost of 1. Now, call the edit distance between two strings as the minimum edit cost needed to change one string into the other. For instance, let's say there are two strings portend and profound . You can apply the following edits to portend : portend (delete o) prtend (insert o) protend (change t to f) profend (change e to o) profond (insert u) profound You can see that five edits were applied. Assuming you can't find a quicker way to change one string into the other, the edit distance between the two strings is 5. Clearly, you can also start from the other string and apply the same edits in reverse (just interchanging the deletions and insertions, and reversing the substitutions). So, starting from profound , delete u , change o to e , change f to t , delete o , and finally insert o , to arrive at portend . The relevance of this concept of edit distance to sequence alignment is simply: the smaller the edit distance, the better the alignment. We'll ignore for the moment whether these are the most biologically relevant types of edits. However, you may want to start thinking of "edits" as " mutations ," and consider whether the problem is perhaps formulated too simplistically to model the actual process of mutation. What about the differences between DNA and proteins in this regard? Should we permit switching the order of two adjacent characters as an edit? How about reversing a substring of the string, as in the known biological process of inversion? Does our assignment of an equal cost to each "edit" make biological sense? Keep these questions in mind; we may eventually want to improve the algorithm by incorporating some of the modifications suggested by these ideas. In approximate string matching, the problem is to find a (short) pattern in a (usually much longer) text. Of the many possible variants of this problem, let's find the location(s) in the text with the smallest possible edit distance from the pattern. We'll do so in the next section. 2.8.1.1 A string matching programNow that you've got an idea of the nature of the problem, its importance to biology, and the basic definitions that we'll use in approaching the problem, let's take a look at a Perl program that solves our problem using dynamic programming. This program uses the references and multidimensional arrays introduced earlier in this chapter. As usual, my approach is to proceed as quickly as possible to practical matters, not dwelling on the theoretical aspects of the computer science involved. I urge the interested reader to consult the references at the end of the chapter for more satisfying details on the techniques of dynamic programming and on the many different approaches that have been developed to solve the approximate string matching problem. The following is a Perl program for approximate string matching, followed by a somewhat detailed discussion of how it works. The program proceeds as follows : first, the pattern and text are defined (as peptides in this case). Then the distance matrix, a two-dimensional array, is declared. After initializing the first row and the first column to the appropriate values (to be discussed later), the algorithm proceeds to fill in the matrix. Each matrix location is calculated by examining three adjacent locations, plus the amino acids in the pattern and the text at that spot; the resulting matrix is printed out. Finally, the best match is found by looking for the smallest edit distance entered in the last row of the matrix. The final result is printed out. #!/usr/bin/perl # # Approximate string matching using dynamic programming # # Find the closest match to the pattern in the text # use strict; use warnings; my $pattern = 'EIQADEVRL'; print "PATTERN:\n$pattern\n"; my $text = 'SVLQDRSMPHQEILAADEVLQESEMRQQDMISHDE'; print "TEXT:\n$text\n"; my $TLEN = length $text; my $PLEN = length $pattern; # D is the Distance matrix, which shows the "edit distance" between # substrings of the pattern and the text. # It is implemented as a reference to an anonymous array. my $D = [ ]; # The rows correspond to the text # Initialize row 0 of D. for (my $t=0; $t <= $TLEN ; ++$t) { $D->[$t][0] = 0; } # The columns correspond to the pattern # Initialize column 0 of D. for (my $p=0; $p <= $PLEN ; ++$p) { $D->[0][$p] = $p; } # Compute the edit distances. for (my $t=1; $t <= $TLEN ; ++$t) { for (my $p=1; $p <= $PLEN ; ++$p) { $D->[$t][$p] = # Choose whichever of the three alternatives has the least cost min3( # First alternative # The text and pattern may or may not match at this character ... substr($text, $t-1, 1) eq substr($pattern, $p-1, 1) ? $D->[$t-1][$p-1] # If they match, no increase in edit distance! : $D->[$t-1][$p-1] + 1, # Second alternative # If the text is missing a character $D->[$t-1][$p] + 1, # Third alternative # If the pattern is missing a character $D->[$t][$p-1] + 1 ) } } # Print D, the resulting edit distance array for (my $p=0; $p <= $PLEN ; ++$p) { for (my $t=0; $t <= $TLEN ; ++$t) { print $D->[$t][$p], " "; } print "\n"; } my @matches = ( ); my $bestscore = 10000000; # Find the best match(es). # The edit distances appear in the the last row. for (my $t=1 ; $t <= $TLEN ; ++$t) { if( $D->[$t][$PLEN] < $bestscore) { $bestscore = $D->[$t][$PLEN]; @matches = ($t); }elsif( $D->[$t][$PLEN] = = $bestscore) { push(@matches, $t); } } # Report the best match(es). print "\nThe best match for the pattern $pattern\n"; print "has an edit distance of $bestscore\n"; print "and appears in the text ending at location"; print "s" if ( @matches > 1); print " @matches\n"; sub min3 { my($i, $j, $k) = @_; my($tmp); $tmp = ($i < $j ? $i : $j); $tmp < $k ? $tmp : $k; } Here is the output: PATTERN: EIQADEVRL TEXT: SVLQDRSMPHQEILAADEVLQESEMRQQDMISHDE 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 1 1 0 1 0 1 1 1 1 1 1 1 1 1 1 0 2 2 2 2 2 2 2 2 2 2 2 2 1 0 1 2 2 2 1 1 2 2 1 1 1 1 2 2 2 2 2 1 2 2 2 1 3 3 3 3 2 3 3 3 3 3 3 2 2 1 1 2 3 3 2 2 2 2 2 2 2 2 2 2 2 3 3 2 2 3 3 2 4 4 4 4 3 3 4 4 4 4 4 3 3 2 2 1 2 3 3 3 3 3 3 3 3 3 3 3 3 3 4 3 3 3 4 3 5 5 5 5 4 3 4 5 5 5 5 4 4 3 3 2 2 2 3 4 4 4 4 4 4 4 4 4 4 3 4 4 4 4 3 4 6 6 6 6 5 4 4 5 6 6 6 5 4 4 4 3 3 3 2 3 4 5 4 5 4 5 5 5 5 4 4 5 5 5 4 3 7 7 6 7 6 5 5 5 6 7 7 6 5 5 5 4 4 4 3 2 3 4 5 5 5 5 6 6 6 5 5 5 6 6 5 4 8 8 7 7 7 6 5 6 6 7 8 7 6 6 6 5 5 5 4 3 3 4 5 6 6 6 5 6 7 6 6 6 6 7 6 5 9 9 8 7 8 7 6 6 7 7 8 8 7 7 6 6 6 6 5 4 3 4 5 6 7 7 6 6 7 7 7 7 7 7 7 6 The best match for the pattern EIQADEVRL has an edit distance of 3 and appears in the text ending at location 20 2.8.1.2 AnalysisLet's examine this program in detail to see how the Perl references and matrices are used and to learn how dynamic programming can solve the approximate string matching problem. You can see that I specified a short pattern and a fairly short text. The shortness of the text is purely for didactic purposes: I want to show the entire matrix that is computed. To see how it performs , you should try running the program by reading in, say, human chromosome 1, and searching for a 20 basepair oligonucleotide. (You'll probably want to omit the printing of the matrix in this case!) Because our program needs to refer to the lengths of the pattern and text at several points, we precompute them to save time and to make the code easier to read. ( $PLEN is easier to read in those tightly packed loops than length $pattern .) Next, the array D is declared: my $D = [ ]; $D refers to the anonymous array denoted by [ ] . It is populated as the algorithm progresses, as a two-dimensional array of integers. The code for the calculation of the edit distance array $D is very short. The 0th row and the 0th column are initialized to start off the computation. The 0th row is initialized to all 0s, and the 0th column is initialized to , 1 , 2 , ... up to PLEN . Why? Let's talk about how this algorithm is going to work. Each entry of the TLEN+1 x PLEN+1 matrix contains the edit distance between a prefix of the pattern and a substring of the text. To be more precise: consider the entry of $D at row $t and column $p (we'll call it in actual Perl syntax $D->[$t][$p] ). The value of $D at this position represents the edit distance between the prefix of the pattern of length $p , and a substring of the text ending at text position $t . Let's look at an actual example. Figure 2-1 shows the output of the edit distance matrix again, with the input strings lined up with the rows and columns. Figure 2-1. Edit distance matrix The entry at row 4 and column 15, that is, $D->[4][15] , highlighted in the figure, has the value 1. This means that the first four characters of the pattern, EIQA , are one edit away from a substring that ends at position 15 in the text. Let's check this. The prefix of length 4 of the pattern is EIQA . A substring that ends at position 15 in the text is EILA . (Note that the beginning position of this substring isn't clear; more on that later and in the exercises.) You see that one substitution, of L in the text to Q in the pattern, transforms the one string to the other. By this definition, the edit distance between these two strings is 1. That's what the entry in the matrix says, so that entry is verified . Take a minute to verify another entry or two. Because you're looking for a match for the entire pattern, it follows that you merely need to look at the last row of the edit distance matrix $D . Each position in that row shows the edit distance between the entire pattern and a substring of the text that ends at that position. Take a look at two or three positions in the last row, and satisfy yourself that the value at each of those positions corresponds to the edit distance between the pattern and a substring of the text ending at that position. Finally, because you're looking for the best match for the pattern in the text, check the position or positions in the last row of the $D matrix that have the minimum value. If there is an exact match for the pattern in the text, there will be a 0 in some position in the last row of the $D matrix. Make sure you also understand the size of the $D matrix and how the positions correspond to positions in the pattern and text strings. The border conditions of the computation are given by the 0th row and 0th column. ( Border conditions are just the starting values of a computation that are initialized before the computation begins.) If you're unfamiliar with border conditions, the initialization may seem a little strange , but it is absolutely typical of many algorithms that they have seemingly trivial border conditions. Each position in any row, from 1 to TLEN , corresponds to a character of the text, starting from the first character to the last. The 0th row is initialized to all 0s because there is an edit distance of 0 from the prefix of the pattern of length 0 to any position in the text. In other words, the empty string (a pattern of length 0) can be matched at any position of the text, so the edit distance is zero all along the 0th row. Similarly, the 0th column is initialized to , 1 , ..., up to PLEN in the last position of the column. These values indicate that at each position in the 0th column, say, at position $p , corresponding to the prefix of the pattern of length $p , it takes $p edits (in particular, $p insertions) to match the substring of the text ending at position 0 (that is, a substring of length 0). The matrix is now set up, and the 0th column and 0th row are initialized; let's see how the algorithm proceeds. Figure 2-2 shows the key idea. The value of a position in the matrix, say: $D->[$t][$p] can be computed by checking the values of the three adjacent positions: $D->[$t-1][$p] $D->[$t][$p-1] $D->[$t-1][$p-1] and considering whether or not the character at position t of the text is the same as the character at position $p of the pattern. Figure 2-2. Computing value for row p and column t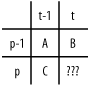 Let's see how this works. The desired, uncomputed matrix entry at $D->[$t][$p] , is represented as ???. The previously computed values at the three adjacent matrix positions are represented by the letters A, B, and C. The distance of the match of the pattern prefix of length $p-1 ends at the text at position $t-1 , represented in the figure as the integer A. If the next character in the pattern, at position $p , is the same as the next character in the text, at position $t , the edit distance of this longer pattern, which ends at this next position in the text, is still A (because no additional substitution, deletion, or insertion was required). On the other hand, if the characters are different, you'd get a new value of A+1 for this match of a longer pattern with a later position in the text. In the code, this first value, which may be one of two different alternatives depending on the characters in the text and the pattern, is programmed using the Perl conditional operator TEST ? Expression1 : Expression2 . This operator returns the value of the first expression if the test is true or the value of the second expression if the test is false. Here, the TEST is: substr($text, $t-1, 1) eq substr($pattern, $p-1, 1) the first expression is $D->[$t-1][$p-1] , and the second expression is $D->[$t-1][$p-1] + 1 . # First alternative # The text and pattern may or may not match at this character ... substr($text, $t-1, 1) eq substr($pattern, $p-1, 1) ? $D->[$t-1][$p-1] # If they match, no increase in edit distance! : $D->[$t-1][$p-1] + 1, Now, consider the case of the match at the position $D->[$t][$p-1] with value B . This represents the match of the pattern prefix of length $p-1 ending at the text at position $t . If you insert another character of the pattern to match at the same position in the text, that incurs an additional edit distance for the insertion, so the new value is B+1. The code for this value is: # Second alternative # If the text is missing a character $D->[$t-1][$p] + 1, Similarly, consider the case of the match at the position $D->[$t-1][$p] with value C . This represents the match of the pattern prefix of length $p ending at the text at position $t-1 . If you extend the match to another character of the text to match at the same position in the pattern, that incurs an additional edit distance for the insertion, so the new value is C+1. The following is the code for this value. # Third alternative # If the pattern is missing a character $D->[$t][$p-1] + 1 These three alternatives are the three arguments to the min3 subroutine, which returns the minimum from among three values. When considering edit distances, you can start from either string. Inserting a character in one string is the same as deleting a character from the other string, depending on which string you start with. I assert that this procedure covers all possible ways of extending a match. This assertion can be proved, but in the interests of practicality, we'll skip that essential step of demonstrating program correctness. The interested reader may want to think about how to prove such an assertion or may simply refer to the literature in Section 2.9. So, what value do you put in place of the ??? placeholder? Since we're looking for the smallest edit distance, let's choose the minimum of the values that have been examined. If character $t and character $p are the same, you'd choose the minimum of the values A, B+1, and C+1. On the other hand, if character $t and character $p are different, you'd choose the minimum of the values A+1, B+1, and C+1. That's our algorithm. Take a moment to examine the Perl code, reproduced here, that calculates the matrix, and see how the code reflects our discussion of the algorithm: # Compute the edit distances. for (my $t=1; $t <= $TLEN ; ++$t) { for (my $p=1; $p <= $PLEN ; ++$p) { $D->[$t][$p] = # Choose whichever of the three alternatives has the least cost min3( # First alternative # The text and pattern may or may not match at this character ... substr($text, $t-1, 1) eq substr($pattern, $p-1, 1) ? $D->[$t-1][$p-1] # If they match, no increase in edit distance! : $D->[$t-1][$p-1] + 1, # Second alternative # If the text is missing a character $D->[$t-1][$p] + 1, # Third alternative # If the pattern is missing a character $D->[$t][$p-1] + 1 ) } } |
EAN: 2147483647
Pages: 156