4.2 Design
| I l @ ve RuBoard |
| Design best practices tend to favor the creation of manageable database applications and rarely enhance performance. In fact, you might find that some of these best practices come with performance costs. Design, however, is never the place to second-guess performance issues. In any kind of programming, you should always put forth the best design first and optimize later. 4.2.1 Separate Application, Persistence, and JDBC LogicThe single most critical best practice in design is the proper separation of application and database logic through a generic persistence interface. Figure 4-1 shows an example of this separation. Figure 4-1. The division of labor in database programming Note that in this approach, database logic is never mixed with application logic. (Here, the person bean object is separate from the person data access object.) This division not only makes code easier to read and manage, but it makes it possible for your data model and application logic to vary without impacting one another. The ideal approach involves encapsulating application logic in components often referred to as business objects and developing a pattern through which these components persist, without knowing anything about the underlying persistence mechanism. Figure 4-2 is a class diagram showing how this approach works for bean-managed Enterprise JavaBean (EJB) entity beans. Figure 4-2. Entity bean persistence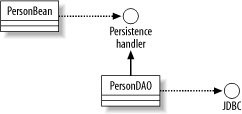 The PersonBean entity bean contains no JDBC code or other database logic. Instead, it delegates all persistence operations to a generic persistence API. Underneath the covers, an implementation of that API performs the actual mapping of bean values to the database through the data access object. In fact, the implementation could persist to any entirely different data storage technology, such as an object database or directory service, without the entity bean being any wiser. 4.2.2 Avoid Long-Lived TransactionsTransactions are intrinsically part of another Java API, but their abuse of databases deserves mention here. Nothing will slow down a system quite like long-lived transactions. Whenever you start a transaction, you put others on hold waiting to access some of the resources of your transaction. Consequently, you should always design your applications to begin transactions only when they are ready to talk to the database and end them once that communication is done. Nothing other than database communication should occur between the beginning and end of a transaction. 4.2.3 Do Not Rely on Built-in Key GenerationEvery database engine provides a feature that enables applications to automatically generate values for identity columns . MySQL, for example, has the concept of AUTO_INCREMENT columns: CREATE TABLE Person ( personID BIGINT UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT, lastName VARCHAR(30) NOT NULL, firstName VARCHAR(25) NOT NULL ); When you insert a new person into this table, you omit the primary key columns: INSERT INTO Person ( lastName, firstName) VALUES ( 'Wittgenstein', 'Ludwig' ); MySQL will automatically generate the value for the personID column based on the highest current value. For example, if one row exists in the database with a personID of 1 , Ludwig Wittgenstein's personID will be 2 . However, using the supported key generation tools of your database of choice presents several problems:
You can avoid the difficulties of proprietary key generation schemes by writing your own. Your first inclination might be to create a table in the database to hold the generated keys, and this inclination is correct. It comes with some caveats, however. Relying solely on a database table to hold the keys requires two trips to the database for each insert. To avoid too many trips to the database, it is best to generate the keys in memory based on a seed from the database. The heart of this database-independent scheme is the following table code: CREATE TABLE Sequencer ( name VARCHAR(20) NOT NULL, seed BIGINT UNSIGNED NOT NULL, lastUpdate BIGINT UNSIGNED NOT NULL, PRIMARY KEY ( name, lastUpdate ) ); Here's the strategy: the first time your application generates a key, it grabs the next seed from this database table based on the name you give it, increments the seed, and then uses that seed to generate keys until the seed is exhausted (at which point, it increments to get another one) or until the application terminates. Examples Example 4-2 through Example 4-4 show how to create a database-independent utility class called Sequencer that uses this strategy to uniquely generate key numbers . This enables your application to use the following two lines of code to create primary keys, an approach which guarantees that you will receive a value that is unique across all values in the specified sequence (i.e., personID ): Sequencer seq = Sequencer.getInstance("personID"); personID = seq.next( ); You probably noticed that you are not using the lastUpdate field yet. Don't worry, this field is being kept in reserve until the next section. Example 4-2 shows part of the Sequencer class, which uses static elements that employ a singleton design pattern to hand out shared sequencers. Example 4-2. Sequencer.java public class Sequencer { static private final long MAX_KEYS = 1000000L; static private final HashMap sequencers = new HashMap( ); static public final Sequencer getInstance(String name) { synchronized( sequencers ) { if( !sequencers.containsKey(name) ) { Sequencer seq = new Sequencer(name); sequencers.put(name, seq); return seq; } else { return (Sequencer)sequencers.get(name); } } } . . . } The code in Example 4-2 provides two critical guarantees for sequence generation:
Example 4-3 continues the Sequencer class with three fields and a constructor. The nonstatic fields have two private variables that mirror values in the Sequencer database table ( name and seed ) as well as a third attribute ( sequence ) to track the values handed out for the current seed. Example 4-3. Sequencer.java (constructors) public class Sequencer { . . . private String name = null; private long seed = -1L; private long sequence = 0L; private Sequencer(String nom) { super( ); name = nom; } . . . } Finally, the core element of the sequencer is its public next( ) method. This method contains the algorithm for generating unique numbers, and uses the following process:
Example 4-4 contains the algorithm. Example 4-4. Sequencer.java (next( ) method) public class Sequencer { static public final String DSN_PROP = "myapp.dsn"; static public final String DEFAULT_DSN = "jdbc/default"; . . . public synchronized long next( ) throws PersistenceException { Connection conn = null; // When seed is -1 or the keys for this seed are exhausted, // get a new seed from the database. if( (seed = = -1L) ((sequence + 1) >= MAX_KEYS) ) { try { String dsn = System.getProperty(DSN_PROP, DEFAULT_DSN); InitialContext ctx = new InitialContext( ); DataSource ds = (DataSource)ctx.lookup(dsn); conn = ds.getConnection( ); // Reseed the database. reseed(conn); } catch( SQLException e ) { throw new PersistenceException(e); } catch( NamingException e ) { throw new PersistenceException(e); } finally { if( conn != null ) { try { conn.close( ); } catch( SQLException e ) { } } } } // Up the sequence value for the next key. sequence++; // Return the next key for this sequencer. return ((seed * MAX_KEYS) + sequence); } . . . } The rest of the code is the database access that creates, retrieves, and updates seeds in the database. The next( ) method triggers a database call via the reseed( ) method when the current seed is no longer valid. The logic for reseeding the sequencer is not shown, but it is fairly straightforward:
Example 4-5 contains the implementation of everything but the creation of a new sequence. You can find the full code for the Sequencer class on O'Reilly's FTP site under the catalog index for this book. (See http://www.oreilly.com/catalog/javaebp.) 4.2.4 Don't Be Afraid to Use Optimistic ConcurrencyDepending on your database engine, you might have the ability to choose between optimistic or pessimistic concurrency models. If your database supports pessimistic concurrency, you can enforce it through either database configuration or JDBC configuration. The concurrency model you select determines whether you or the database engine is responsible for preventing dirty writes ”that is, preventing one person from overwriting changes made by another based on old data from the database. Under optimistic concurrency, changes can be made to a row between the time it is read and the time updates are sent to the database. Without special logic in your application, systems that rely on optimistic concurrency run the risk of the following chain of events:
The consequence of this chain of events is an invalid marital status in the database. The status is no longer valid because User B overwrote the change in marital status of User A with the dirty data from its original read. Pessimistic concurrency prevents dirty writes. How it prevents dirty writes depends on your database engine. Put succinctly, pessimistic concurrency causes User A to get a lock on the row or table with the user data and hold up User B until the marital status change is committed. User B reads the new marital status and will not overwrite the change of User A unless it is intended. Because maintaining data integrity is the single most important principle of database programming, it might appear that pessimistic concurrency is a must. Unfortunately, pessimistic concurrency comes with a huge performance penalty that few applications should ever accept. Furthermore, because many database engines do not even support pessimistic concurrency, reliance on it will make it difficult to port your application to different databases. The answer to the problem of using pessimistic concurrency without sacrificing data integrity is to use a smart optimistic concurrency scheme. Under optimistic concurrency, the burden of data integrity lies squarely on the shoulders of the application developer. The problem you face managing optimistic concurrency is how you allow people to make changes to the database between reading a row from a table and writing updates back to the database. To prevent dirty writes, you need some mechanism of row versioning, and then you must specify updates only to a particular version of that row. Programmers use many different schemes for versioning rows; some database engines even have built-in row versioning. Two of the more common approaches are to use either a timestamp or a combination of a timestamp and another identifying information such as a user ID. Earlier in this chapter, we discussed a scheme for generating unique primary keys. The Sequencer table responsible for storing the state of the primary key generation tool had a compound primary key of both the sequence name and the time it was last updated. Example 4-5 contains the JDBC calls that make updates to that table using optimistic concurrency, which is shown in the fully implemented reseed( ) method. Example 4-5. Sequencer.java (reseed( ) method using optimistic concurrency) public class Sequencer { . . . static private final String FIND_SEQ = "SELECT seed, lastUpdate " + "FROM Sequencer " + "WHERE name = ?"; static private final int SEL_NAME = 1; static private final int SEL_SEED = 1; static private final int SEL_UPDATE = 2; static private String UPDATE_SEQ = "UPDATE Sequencer " + "SET seed = ?, " + "lastUpdate = ? " + " WHERE name = ? AND lastUpdate = ?"; static private final int UPD_SEED = 1; static private final int UPD_SET_UPDATE = 2; static private final int UPD_NAME = 3; static private final int UPD_WHERE_UPDATE = 4; private void reseed(Connection conn) throws SQLException { PreparedStatement stmt = null; ResultSet rs = null; try { // Keep in this loop as long as you encounter concurrency errors. do { stmt = conn.prepareStatement(FIND_SEQ); stmt.setString(SEL_NAME, name); rs = stmt.executeQuery( ); if( !rs.next( ) ) { // If there is no such sequence, create it. { // Close resources. try { rs.close( ); } catch( SQLException e ) { // Handle } rs = null; try { stmt.close( ); } catch( SQLException e ) { // Handle } stmt = null; } // Create the sequence in the database. create(conn); } else { long ts; seed = rs.getLong(SEL_SEED) + 1L; ts = rs.getLong(SEL_UPDATE); { // Close resources. try { rs.close( ); } catch( SQLException e ) { // Handle } rs = null; try { stmt.close( ); } catch( SQLException e ) { // Handle } stmt = null; } // Increment the seed in the database. stmt = conn.prepareStatement(UPDATE_SEQ); stmt.setLong(UPD_SEED, seed); stmt.setLong(UPD_SET_UPDATE, System.currentTimeMillis( )); stmt.setString(UPD_NAME, name); stmt.setLong(UPD_WHERE_UPDATE, ts); if( stmt.executeUpdate( ) != 1 ) { // Someone changed the database! Try again! seed = -1L; } } } while( seed = = -1L ); sequence = -1L; } finally { if( rs != null ) { try { rs.close( ); } catch( SQLException e ) { // Handle } } if( stmt != null ) { try { stmt.close( ); } catch( SQLException e ) { // Handle } } } } . . . } Without optimistic concurrency in place, you would either have to rely on pessimistic concurrency or risk the generation of a series of duplicate identifiers. This code prevents duplicate keys without resorting to pessimistic concurrency by using the last update time ”accurate to the millisecond ”as a versioning mechanism. The last update time is part of the primary key, and it is updated with every change. Now, an attempted dirty write will take the following course:
This approach works because the SQL statement specified by the static string UPDATE_SEQ will update a table only in the event that both the name and the lastUpdate timestamp are identical to the values it read earlier from the database. Otherwise, the call to executeUpdate( ) will return -1 . Figure 4-3 illustrates how optimistic concurrency works. Figure 4-3. An activity diagram illustrating optimistic concurrency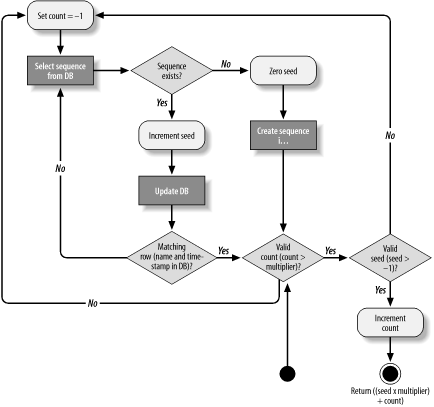 This approach works only if versioning using milliseconds sufficiently guarantees distinct row versions. In other words, it will fail if three requests to read and update the row can occur in the same millisecond, or if the updates are occurring from a set of hosts with serious time synchronization issues. However, in the scenario of ID generation, these issues do not materialize into a serious concern. Alternative forms of optimistic concurrency management can address clock synchronization. In older systems, it was impossible even to get the current time down to the millisecond. Though the read-three-and-update scenario was unlikely in a single millisecond for unique identifier generation, doing it in a second is not so inconceivable. Similarly, in client/server applications where the client clocks can be severely out of whack, System.currentTimeMillis( ) is not reliable. The solution is to add more information to the update clause. In client/server applications, for example, it is common to use a timestamp combined with the user ID of the last person to update the table. Because different clients tend to represent different users in a client/server environment ”and they rarely do work that would risk multiple updates in the same second ”the combination of user ID and timestamp addresses both the rapid operation and clock synchronization issues. That said, the use of user IDs in multitier applications is unreliable because an application server in such an environment tends to use the same user ID for all database access, no matter who the client is. The moral here is that there is no definitive answer; you always need to tailor your optimistic concurrency management to the needs of the environment in which you are working. Finally, it is important to note that while operating a database using optimistic concurrency has major performance advantages over operating with pessimistic concurrency, the data integrity management schemes I have introduced come with performance hits on updates. Specifically, you are updating unique keys in your database on every insert and update. Updating keys can be an expensive operation. Normally, this performance hit is well worth the cost, as read operations significantly outnumber write operations most of the time. If you are in a heavy write situation, however, you might want to consider other options. If you are performing some limited timeframe write operation, such as a batch update, you might even want to turn off indexing completely. |
| I l @ ve RuBoard |
EAN: N/A
Pages: 96