Layer 4 Load Balancing Metrics
| One of the most important concepts in content switching, and server load balancing in particular, is that of the metrics used to distribute load. As we saw earlier, an important role in content switching is to move away from the single server model to one where load can be evenly distributed among a number of different object servers. Understanding the techniques for load distribution and their relative pros and cons is key to successfully deploying server load balancing and other content switching applications. All distribution metrics will typically be session based. That is to say that they will make a new load balancing decision per TCP session or UDP flow, not on a per-frame basis. While this may seem obvious, it is important to understand that all frames in a TCP session or UDP flow must be forwarded to the same real server; otherwise , sessions will be broken. Within most content switching hardware, this is achieved by creating entries in the session table as decisions are made. Consequently, the logic for setting up and maintaining a TCP session would look like:
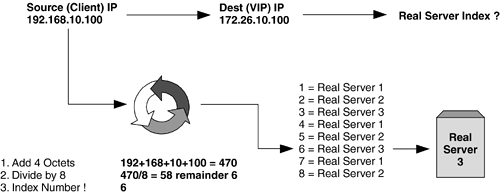
We discuss the individual load balancing metrics next . Least ConnectionsLeast connections is the simplest distribution metric and is often the default for content switching configurations. It guarantees the best distribution of load among the object servers based on the number of TCP sessions or UDP flows established over time. As the name suggests, when using least connections the content switch will send a new TCP session or UDP flow to the server that has the least number of concurrent sessions at the time. The primary advantage of least connections as a metric is even load distribution. Over time, the number of sessions handled by each server should be even based on the relevant processing capability of each. Consider an example where two servers are being load balanced, one comprising a faster CPU, more memory, and a gigabit interface card, and the other with slower CPU, less memory, and only a 10Mbps Ethernet card. The faster machine will be able to cope with a higher number of sessions per second, and this would be best reflected using least connections as a load distribution metric. The disadvantage , as with many other simple Layer 4 metrics, is that least connections provides no persistence between client and server. That is to say that a client retrieving a simple Web page using a HTTP/1.0 browser might have its first GET request serviced by server 1, it's second by server 2, and so on. Round RobinRound robin is also a very simple load distribution metric and is very effective for sharing load evenly among object servers. Again as the name suggests, incoming sessions will be load balanced on a round robin basis, with the first session going to server 1, the second to server 2, and so on. The advantage of round robin as a distribution metric is even numbers of sessions per server. Whereas with least connections, the processing power and performance of each object server plays a part in the distribution, this is not the case with implementations using round robin. Each server will receive the same number of connections over time irrelevant of how fast it is able to process and deal with them. For this reason, round robin is less effective in environments where the relative processing power of the object servers differs , unless used with a per-server weighting as described later in this chapter. Round robin also suffers the same flaw as least connections in that it does not achieve even a simple level of persistence, and different servers may service subsequent requests from the same client. IP Address HashingIP address hashing is the first metric that is able to provide some form of limited persistence. The term hashing is used to refer to a deterministic algorithmic calculation based on the IP address information contained within the TCP session or UDP flow, and it is this uniformity that gives this metric IP address-based persistence. There are many address and port combinations that the content switch might want to include in this calculation, typically depending on the application being deployed. Let's take a simple example of using the entire 32 bits of the source IP address as shown in Figure 5-15. Figure 5-15. Simplistic example of IP address hashing. While many content switching vendors will employ far more complex hashing algorithms to calculate the result, the concept remains the same. All available real servers are referenced using an index table with, in this instance, eight entries. This index table would usually hold far more entries, typically the same as the total number of real servers supported. Using some form of numeric folding, the IP address will yield an index into this Real Server Index table and from this, the content switch can successfully assign the appropriate real server for the client connection. It follows that all subsequent connections from the same client IP address will yield the same entry point into the index table and thus the same real server. We'll see other examples of content switching applications where this consistency of the deterministic algorithms provides an elegant means to solve some implementation issues. So, why would you use different IP and port information when performing such calculations? Well, for different applications of content switching, different results might be desired. Take an example of simple Layer 4 server load balancing where the repeated connections from the same client should be bound to the same real server. Using source IP address hashing would give us just such a result. If we take this one step further and assume that all connections from multiple client machines are being proxied behind just a single address, our load-balancing model would break, as all connections from these clients will only ever be forwarded to the same real server. In such instances, including the source TCP or UDP port information would again include a randomizing element resulting in connections being distributed among all real servers. For applications such as Web cache redirection, discussed in Chapter 8, Application Redirection , using the destination rather than source IP address will give greater optimization of the caching resources as all connections to the same destination Web site will be serviced by the same cache. Table 5-1 lists some simple examples of hashing combinations and where they would be deployed. Table 5-1. When and Where to Use Different Hashing Techniques
Response Time and Server AgentWhile least connections, round robin, and hashing can, at best, provide only limited visibility of the resource availability of the real servers, the use of either a server-based agent or measurements on the server responses can help to provide a clearer picture of the actual ability of a real server to cope with incoming requests. Response time metrics typically use the health-checking mechanisms to influence the traffic distribution by taking measurements over a period of time of how long the health checks take to complete. This process may range from a simple ICMP ping, the opening and resetting of a TCP connection, or even the running of a fully scripted health check. One example of where this might provide greater visibility is in the use of an intelligent server-based script that produces a measured result, often requiring the pulling of information from an application server or database. At busier times for each real server, the time taken to complete such a request will increase and thus the weighting on the real server can be gradually decreased to relieve it of processing incoming requests. Some content switches take this approach further with the inclusion of software-based agents that reside on each real server, feeding back information about the ongoing performance. These agents are typically capable of tracking information on the CPU, disk, and memory performance that the content switch can then use to influence traffic flow and session distribution. BandwidthOne other performance-influenced metric is that of bandwidth monitoring . In certain instances, typically other than standard server load balancing, it is useful to identify trends in the amounts of LAN bandwidth being used by each real server and use this information to influence server distribution. Monitoring the bandwidth transmitted out toward a particular server MAC address over time and adjusting the weighting of the real server accordingly is one mechanism used to achieve this. Bandwidth-based load balancing is most useful in environments where data transfer rates are key to the application's success, or in instances where firewalls or routers are being balanced. Weighting and Maximum ConnectionsWhile not a metric in its own right, server weighting is a technique that can be used to influence traffic distribution in conjunction with the metrics described previously. Assigning a "weight" to a server will bias traffic flow toward larger or more powerful real servers based on a defined value, usually an integer in a specific range. Consider an example where two real servers are weighted "'2"and "1," respectively. Using a metric such as round robin with these server weightings, the first server would, over time, expect to see twice the number of connections as the second. As one would expect, server weightings are typically only applicable in conjunction with metrics that are performance based (such as round robin, least connections, response time, and bandwidth) and not deterministic metrics such as IP address hashing. Another further enhancement to standard Layer 4 metrics is the use of a maximum number of connections, definable per real server to indicate the total number of concurrent TCP sessions or UDP flows that the server can handle. This is a useful mechanism to ensure that the resources of a particular server or group of servers are never overloaded, especially when servers of different sizes are used in combination. If the maximum number of connections is reached, new incoming sessions are assigned to alternate servers in the group. It's worth considering that if a persistent distribution mechanism is being used and the maximum connections for a given server is reached, the persistence will likely be broken. The answer to this conundrum is simplemore servers need to be added because while the content switch can make best use of the available resources, it cannot, certainly at the time of writing, produce these resources from nothing. One common approach for dealing with the maximum connections being reached is to define an overflow server or group of servers to deal with requests by displaying a tailored error message indicating that the site is busy. While this approach does not solve the problem of insufficient resources, it can help in preventing the user from experiencing a "black holed" connection. |
EAN: 2147483647
Pages: 85