Symmetric Cryptography
Symmetric Cryptography
Symmetric cryptography is a cryptographic method employing a single key for both encryption and decryption. The use of a single key makes the decryption process a simple reversal of the encryption process. Symmetric cryptography is the cryptographic method most often thought of when people consider classic cryptographic techniques, such as one-time pads (which we cover in the section "Stream Ciphers").
Symmetric Primitives
In this section we will describe some of the most important primitives and protocols used in today's cryptographic applications. Recall that cryptographic primitives are the building blocks for cryptographic protocols and for secure applications. Although cryptographic primitives by themselves do not provide useful functionality and should not be used by application developers, an understanding of these primitives is helpful in understanding the protocols.
Block Ciphers
Block ciphers are among the most important, powerful, and useful cryptographic primitives. They serve as the backbone for many cryptographic protocols. Although most of you do not need to understand the inner workings of block ciphers, you should understand the external behavior of block ciphers.
A block cipher consists of a pair of algorithms: an encryption algorithm and the inverse, a decryption algorithm. These algorithms, respectively, accept a plaintext (or ciphertext) message and a key as input and produce a ciphertext (or plaintext) message as output. For any given block cipher, the size of the plaintexts and ciphertexts is the same fixed value (called the cipher's block length). That is, a block cipher would convert 64-bit (8-byte) plaintext blocks into 64-bit ciphertext blocks. To encrypt messages longer than the block length, you must wrap the block cipher in a higher-level protocol, which we will cover shortly.
For any given key and plaintext block, a block cipher encryption algorithm will always produce the same ciphertext block. Similarly, for any given key and ciphertext block, a block cipher decryption algorithm will always produce the same plaintext block. The block cipher's encryption and decryption algorithms are complementary. Different keys (with very high probability) produce different encryptions and decryptions. A plaintext encrypted under one key yields a different ciphertext than the same plaintext encrypted under a different key. For any given key, a block cipher should appear to be a random mapping between possible plaintexts and ciphertexts. That is, an attacker should not be able to tell the difference between a block cipher encryption and a purely random string.
Obviously, keys play an integral role in the security of a block cipher. If an attacker acquires a key, she can encrypt or decrypt blocks with that key. We are assuming that the encryption algorithm is known or determinable; in most cases, this is true. Therefore, not only must an application keep its keys secret, but it must also be prohibitively difficult for an attacker to randomly guess a particular key or try a brute force attack. One way to ensure that an attacker will have difficulty guessing a particular key is to increase the number of bits in a key, making the number of possible keys very large.
If a block cipher uses k-bit symmetric keys, there will be 2k possible keys for that block cipher. This means that an attacker will have to try 2k keys before she finds the correct one. In reality, the attacker may be lucky and the first key will be correct, or she may have to try all 2k keys. On an average, the attacker would have to make 2k 1 guesses. This is for strong block ciphers where brute force is the most efficient attack; weaker block ciphers may have more efficient attacks. Key length has less effect on these other attacks. These issues are not specific to block ciphers; key length affects the strength of all ciphers.
Although there are many block ciphers, we shall give further consideration to the three most popular: DES, 3DES, and AES. Published in the 1970s, DES is the U.S. Government's Data Encryption Standard. DES has a block size of 64 bits and a key size of 56 bits. Despite its relatively small block and key sizes, DES is an incredibly well-engineered cipher. Although there are a number of theoretical attacks against DES, the most practical attack is still a brute force attack of trying all 256 (or more than 72 quadrillion) keys.
Even with this large number of keys, brute force attacks against DES are now possible with today's networking and desktop computing power. Thus, the adoption of 3DES (or triple-DES). Triple-DES consists of three chained DES operations (see Figure 6.5):
Figure 6.5. The triple-DES process
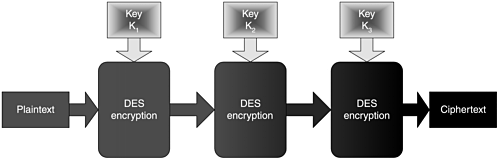
1. Encrypt the plaintext with key K1.
2. Decrypt with key K2.
3. Encrypt again with key K3.
This is known as three-key 3DES. There is also a two-key 3DES, in which K1 and K3 are the same. The key size for two-key 3DES is 112 bits, and the key size for three-key 3DES is 168 bits. Unfortunately, certain attacks against two-key 3DES are significantly faster than brute force. Proving that, even if you take a very strong primitive and implement it correctly, its implementation may be vulnerable.
In the mid 1990s the U.S. Government's National Institute of Standards and Technology (NIST) began the process of selecting a new U.S. Advanced Encryption Standard (AES). Because of DES's vulnerabilities (due to its small key and block sizes and slow performance), AES is to replace DES and be computationally efficient and secure. After several years and numerous technical meetings, NIST has picked a cipher called Rijndael (pronounced "rhine-dahl") to be the AES. Rijndael is configurable; versions of Rijndael exist for any combinations of appropriate key sizes (128, 192, or 256 bits) and block sizes (128, 192, or 256 bits).
Stream Ciphers
Stream ciphers are another very popular encryption primitive. They are typically much faster and simpler than their block cipher cousins (especially when implemented in hardware) and are therefore commonly used in systems that cannot handle the overhead associated with block ciphers (such as high-speed telecommunications systems). Unlike block ciphers, there is no clear, generally accepted, popular stream cipher. In fact, many of today's commonly used stream ciphers are proprietary.
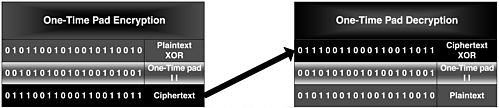
Modern stream ciphers are modeled after the Vernam one-time pad (see Figure 6.6). The sender and receiver share a long sequence of random binary digits (the one-time pad). When the sender wants to send a secret message to the receiver, the sender XORs the first bit of the plaintext message with the first bit of the one-time pad. Then she XORs the second bit of the plaintext message with the second bit of the one-time pad, and so on. This process is continued until the end of the message is reached.
Figure 6.6. A one-time pad
XOR or Exclusive OR is represented by the symbol ![]() and has the following properties:
and has the following properties:
0 ![]() 0 = 0;
0 = 0;
1 ![]() 1 = 0;
1 = 0;
0 ![]() 1 = 1;
1 = 1;
1 ![]() 0 = 1
0 = 1
As you can see, XOR is a change indicator, meaning that the result is 1 only when the two bits are different.
To maintain the security of the system, a one-time pad (as the name implies) requires that its bits never be reused. After a bit is used from the one-time pad, it must be discarded. Provided a one-time pad is never repeated and is truly random, its encryption algorithm is perfectly secure. This means that even if an attacker has an unlimited amount of computing power at her disposal, she will be unable to learn anything about the plaintext message.
Although theoretically optimal from an encryption standpoint, in practice the one-time pad is not very useful. Because it must never be reused, it must be as long as the secret message to be encrypted. In fact, it must be as long as all the messages that may ever be sent. Even with great forethought, this is virtually impossible to do in practice.
Modern stream ciphers are an attempt to provide a practical version of the Vernam one-time pad. The heart of the modern stream cipher is a keystream generator. The keystream generator takes a small key (or seed) and generates a longer keystream. The resulting keystream is then used like the one-time pad. The premise behind stream ciphers is that it is much easier for two parties to agree on a small secret key (to produce the keystream) than to agree on an entire one-time pad. Unfortunately, these modern stream ciphers are not perfectly secure, and an attacker with enough resources can break the encryption. Most of the vulnerabilities lie in the fact that producing truly random bit streams using a computational method is very difficult. Developers and consumers should be very leery of stream ciphers or algorithms that claim to produce random numbers or random streams. The truth of the matter is that the best that can be accomplished computationally are pseudo-random numbers or pseudo-random streams.
Hash Functions
Cryptographic hash functions are another extremely important cryptographic primitive. Hash functions take as input a long string of bits (such as a message or file) and produce as output a smaller, compressed string of a fixed size. For example, the SHA-1 hash function produces 160-bit hash values, and the MD5 hash function produces 128-bit hash values. Unlike block ciphers and stream ciphers, hash functions do not utilize keys. This means that, given a specific input, anyone can compute the hash of the input.
Most cryptographic hash functions share the following properties:
Pre-image resistance. It should be difficult for an attacker, when given a hash value, to be able to identify a stream that will produce that hash value. That is, if Z is an output of a hash function, it should be hard for an attacker to find a value X so that X hashes to Z.
Second pre-image resistance. It should be difficult for an attacker to find a second stream for a given hash value that produces that hash value. That is, given a value X that hashes to Z, it should be hard for an attacker to find another value Y that also hashes to Z.
Collision resistance. It should be difficult to find two different inputs that hash to the same value. That is, it should be hard for an attacker to find two values, X and Y, that hash to the same value Z. Here the attacker has complete control over the choice of both X and Y.
As with block ciphers and stream ciphers, hash functions are susceptible to brute force attacks. To brute-force a pre-image or second pre-image of a hash value Z, an attacker would repeatedly pick input strings and hash those strings until one of those strings hashes to Z. If the target hash function produced an n-bit hash value, an attacker would need to try nearly 2n strings before finding one that hashes to Z.
To brute-force a collision, an attacker would have to pick random input strings repeatedly until two of those strings hash to the same value. Because of a mathematical property dubbed the birthday paradox, an attacker would have to hash approximately 2n/2 strings before finding two strings that hash to the same value. Meaning, to prohibit these brute force attacks, secure applications should use hash functions with 160-bit or more hash sizes. (Again, this number will increase as processing power and available memory increases in readily available computing platforms.)
The Birthday ParadoxThe birthday paradox is a problem of probability. Given a room with more than 23 randomly selected people, the probability that 2 people in the group have the same birthday is 50 percent. In other words, there is a 50/50 chance that 2 of those people have the same birthday. The paradox comes in because we normally consider only matching our birthday to someone else's, which is a 1/365 chance of matching, or .27 percent. Put another way, the probability of failure is (1 .27%) = 99.73%. Each additional person we ask increases the chance by only 1/365 (an addition function), so asking 23 people increases the chance of matching to only 1/365+1/365 (repeated 21 more times), which equals 23/365, or nearly 6.3 percent a very low percentage. However, when you start comparing pairs in the group (that is, looking for any matching birth date), it becomes a different story because each person is comparing her birth date against the other 22 people (a multiplication function), or (23*22)/2 pairs, or 253 pairs. Although the probability of failure in the first case is 99.73 percent, in the latter case it is the probability of failure raised to the number of pairs, or .9973253 = .5046. The probability of success is 1 .5046 = .4954, or approximately 49.5 percent. In a large set of possible strings, finding a second string that hashes to the same value as a given string has a very low-percentage probability of success. Finding a pair of strings that hash to the same value within a large set of possible strings is not as difficult a task. However, if the set of possible strings is large, you still have to try many strings before the probability of success becomes reasonable. |
Recently, the U.S. Government published three additional hash algorithms: SHA-256, SHA-384, and SHA-512. As their names imply, these new hash algorithms respectively produce 256-bit, 384-bit, and 512-bit hash values. Because the strength of an n-bit hash function against a brute force collision attack is about 2n/2 and the strength of a block cipher with a k-bit key against a brute force key search is about 2k, applications requiring block ciphers with k-bit keys should use hash functions with 2k-bit hash results. For example, an application using 128-bit key AES should use SHA-256, and an application using 256-bit key AES should use SHA-512.
Symmetric Protocols
Earlier, we said that a block cipher's encryption algorithm takes a key and an n-bit plaintext and produces an n-bit ciphertext. How do you use a block cipher to encrypt more than n bits? The answer is to wrap the block cipher primitive within a higher-level protocol. This higher-level protocol is called an encryption mode.
The Electronic Code Book (ECB) mode is perhaps the most intuitive way to use a block cipher to encrypt more than n bits of plaintext. Figure 6.7 depicts this process:
Figure 6.7. The ECB encryption mode
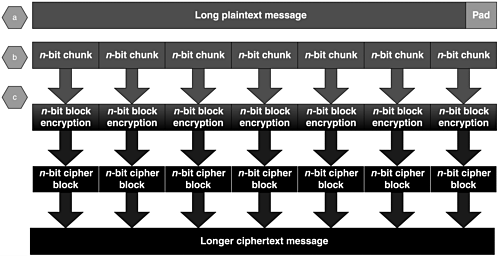
a. Pad the plaintext so that it is a multiple of n bits.
b. Split the resulting padded plaintext into n-bit chunks.
c. Encrypt each chunk independently.
Because the ECB mode is so intuitive, many applications use it to encrypt their data. Unfortunately, the ECB mode is also insecure; it leaks information about the encrypted plaintext. For example, recall that a single plaintext block always encrypts to the same ciphertext block (using a fixed key). This means that the message ABAB with a block cipher in ECB mode (where A and B represent n-bit plaintext blocks) encrypts to XYXY (where X and Y represent n-bit ciphertext blocks). An attacker looking at the ciphertext will learn that the first plaintext block is the same as the third and that the second is the same as the fourth. This gives the attacker information about the plaintext.
Another aspect of the ECB mode that the developer should be aware of is that n-bit blocks can be moved around within the message and still decrypt properly, although the message's meaning is changed. This is not a problem with ECB, though; it is a problem with the implementation. The encryption modes are tools to accomplish privacy, not integrity. Unfortunately, many applications mistakenly assume that encryption protocols will automatically prevent an attacker from tampering with encrypted messages. (More on this in the section "Common Problems.")
CBC
The Cipher Block Chaining (CBC) mode is a more secure way to encrypt long plaintexts. Figure 6.8 depicts this process:
Figure 6.8. The CBC encryption mode
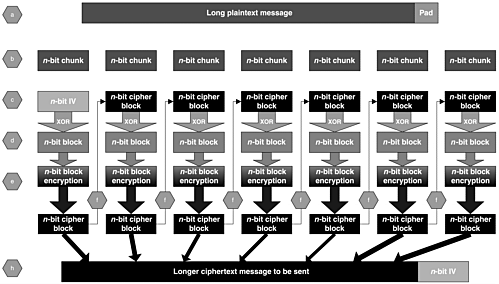
a. Pad the plaintext so that it is a multiple of n bits.
b. Split the resulting padded plaintext into n-bit chunks.
c. Pick a random n-bit value called an initialization vector (IV).
d. XOR the first plaintext block with the IV.
e. Encrypt the resulting value using the block cipher.
f. The resultant ciphertext block is output and XORed with the next plaintext block.
g. Steps e and f are repeated until the end of the plaintext message is reached.
h. The message sent is both the random IV and the ciphertext message.
The important aspect of the CBC mode is that the same plaintext block or message always encrypts to different ciphertext blocks or messages (provided that a different IV is chosen for each encryption).
CTR
Counter (CTR) mode is another secure use of a block cipher to encrypt a long plaintext message. There are two general CTR mode constructions: randomized and stateful. The idea behind CTR mode is to use a block cipher as a stream cipher to generate a keystream. This keystream is XORed with the plaintext to produce the ciphertext. Both versions of CTR mode begin with an n-bit counter or seed i. Figure 6.9 depicts the process of a stateful CTR mode:
Figure 6.9. The stateful CTR mode
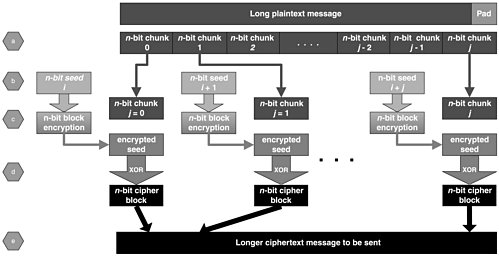
a. The plaintext message is broken into jn-bit blocks. The last block is padded so that it is a multiple of n bits.
b. Initialize i to some value (usually 0).
c. Encrypt i with a block cipher using key k.
d. XOR the output with the jth plaintext block.
e. Append the result to ciphertext results, and increment i and j.
f. Repeat steps c e for all j blocks.
The initial counter i must be included with the ciphertext message or must be agreed on ahead of time by the sending and receiving parties. Of course, the sending and receiving parties should be the only ones who know the shared secret k.
The two versions of CTR mode differ only in how the value i is chosen. In the randomized version, a different random i is chosen for each message. In the stateful version, i is set to 0. With both versions every time a new block is encrypted, i is incremented. The value or state of i is maintained between plaintext messages. As with any stream cipher, care must be taken so that the keystream is not reused. In the stateful version, this is accomplished by ensuring that the counter i never wraps or by changing the key k before i wraps. In the randomized version, this is accomplished by changing the encryption key with enough frequency to ensure that the probability that the keystream will repeat is very low.
MAC
Privacy and integrity are two goals of applied cryptography. Encryption protocols are tools to accomplish privacy. We have noted that encryption does not accomplish integrity. This deficiency requires another class of protocols: message authentication codes (MACs). MACs are algorithms designed to protect the integrity of messages. If the transmissions are MACed, the receiver can detect whether a malicious attacker has modified a message. Most applications that require secure communications should use both an encryption protocol and a MAC.
A MAC consists of two parts: a tagging algorithm and a verification algorithm. The tagging algorithm attaches a MAC tag to a message, and the verification algorithm verifies a message's MAC tag. As with symmetric encryption modes, there are numerous MACs, some based on block ciphers and others on hash functions. The important point is that the chosen MAC needs to be resistant to tampering and sensitive to any modification to the message cryptographically secure.
EAN: 2147483647
Pages: 73