Resource and Performance Monitoring Tools
| I l @ ve RuBoard |
| This section describes tools for monitoring your application's overall performance and system resource utilization. It does not cover other areas, such as system call optimization for the application or code profiling. Collecting application performance metrics is difficult, because defining the components making up the application is difficult. Some processes may be utility programs used by multiple applications. Even when the processes are known and are unique to an application, a performance tool may have difficulty mapping the use of shared resources, such as network buffers, to specific processes. Different products have different ways of defining applications. For example, MeasureWare and PRM (Process Resource Manager) each have a different way of configuring applications. These methods are described briefly later in the chapter. PLATINUM's ServerVision also can monitor a group of processes as one application based on a user configuration. You must realize that you may need to reconcile the differences between the products' unique definitions to analyze application performance data properly. Application Resource MeasurementBecause measuring the performance of an application is difficult, Hewlett-Packard and Tivoli Systems jointly developed an open set of APIs for measuring application response time. This standard set of APIs is called Application Resource Measurement (ARM). If applications are modified to use the new APIs at key points, end-users can then measure and control end-to-end performance of those applications. API calls are made in the application to mark the beginning and end of a transaction. A Software Developer's Kit (SDK) is freely available for ARM from either Tivoli or Hewlett-Packard to make this process easier. Only a few ARM APIs exist and they are listed in Table 7-1. Baan has announced that the next release of its ERP application will be instrumented using the ARM API, which will make collecting application performance data for Baan more straightforward. Table 7-1. ARM APIs
MeasureWareThe MeasureWare Agent is a Hewlett-Packard product that collects and logs resource and performance metrics. MeasureWare agents run and collect data on the individual server systems being monitored . Agents exist for many platforms and OSs, including HP-UX, Solaris, and AIX. The MeasureWare Agent collects data, summarize it, timestamp it, log it, and send alarms when appropriate. The agents collect and report on a wide variety of system resources, performance metrics, and user-defined data. The information can then be exported to spreadsheets or to performance analysis programs, such as PerfView. The data can be used by these programs to generate alarms warning of potential performance problems. By using historical data, trends can be discovered , which can help to address resource issues before they affect system performance. The MeasureWare agents collect data at three different levels: global system metrics, application, and process metrics. Global and application data is summarized at five-minute intervals, whereas process data is summarized at one-minute intervals. Process information is recorded only at interesting time periods, such as when the process starts, terminates, or exceeds a defined threshold for CPU or disk utilization. The basic categories of MeasureWare data are listed in Table 7-2. Optional modules for database and networking support also are available. The Data Source Integration (DSI) capability is used to integrate your own data with other data collected by the MeasureWare Agent. Transaction data is available for applications that are using the ARM API, described earlier. Separate log files are created for each of these categories, as well as a file for individual device data. However, only system and process data is logged by default. Many of the system metrics collected by MeasureWare are described in Chapter 4. This section describes the additional metrics that are available for applications and processes. Although MeasureWare provides extensive performance and resource information, it provides limited configuration information and no data about system faults. It may be beneficial to use MeasureWare with a fault monitoring tool, such as EMS. For MeasureWare to aggregate process-level data into an application, the application has to be defined first. The administrator associates an application name with a group of processes. Table 7-2. Categories of MeasureWare Agent Information
To define a new application, edit the file /var/opt/perf/parm. In this example, metrics are logged for an application called ORACLE, which will be an aggregation of process metrics collected for all processes whose names begin with ora: application = ORACLE file=ora* Note that wildcards can be used, which can be handy if all the individual processes are not known in advance, or many processes exist. Additional configuration options enable you to associate processes with an application, based on the process priority or the user or group name. Note that a process can belong to only one application, and MeasureWare finds the first match for the process, so be sure to list your most important applications first in the configuration file. If you want to receive messages when the MeasureWare data being logged hits certain thresholds, you can specify these alarm conditions in the /var/opt/perf/alarmdef configuration file. Additional alarm definition files can also be used. Alarm conditions are checked at the time the data is logged. The alarms can be sent to PerfView, IT/O, or any SNMP-capable management station. The target configuration information is specified in the alarm generator database (agdb). Actions can be performed on the local system in response to an alarm. The local action is one way to provide your own notification method in response to an alarm. For example, you can execute a Unix command to send the administrator a message. Note that if alarms are being sent to an IT/O agent, MeasureWare, by default, won't take any local actions, under the assumption that IT/O will be configured to take the local actions instead of MeasureWare. You can have alarms sent based on conditions that involve a combination of metrics. For example, a CPU bottleneck alarm can be based on the CPU use and CPU run queue length. Durations can be specified along with an alarm condition. The condition must be true for the specified time before an alarm is sent. An alarm severity can also be specified. If you want MeasureWare alarms to be sent to PerfView, you need to configure this through the PerfView interface. The MeasureWare tool agsysdb is used to add a new trap destination system for SNMP alerts. The example in Listing 7-5 shows an alarm definition to send alerts when the finance_app application exceeds a limit on its CPU utilization. First, a warning alert is sent. If the problem persists, a critical alert is sent. Depending on how the alarm generator has been configured, the alarm goes to the PerfView Alarms window, the IT/O Message Browser, or an SNMP-based management station. Note that the application must also be defined in the parm file. MeasureWare includes a program called utility that can do a variety of tasks . The analyze command in the utility program is used to analyze the data in a log file against alarm definitions in an alarm definitions configuration file. You can then decide whether the alarm definitions will generate too many or too few alarms. You can see what messages would have been printed and what programs would have been executed. An alarm summary report shows a count of the number of alarms and the amount of time each alarm would have been active. Listing 7-5 MeasureWare alarm definition for an application's CPU utilization. ALARM finance_app:app_cpu_total_util > 30 FOR 5 MINUTES START { WARNING ALERT "Your app is busy." EXEC "echo 'finance app is very busy'mailx root" } REPEAT EVERY 15 MINUTES CRITICAL ALERT "finance app continues to be busy." END RESET ALERT "finance app no longer busy." MeasureWare's extract command in the utility program can be used to export data to other tools, such as spreadsheet programs. The extract command makes raw log files usable by Perf View as well. The following application-level metrics are available on HP-UX and Sun Solaris:
These additional application-level metrics are available on HP-UX:
MeasureWare Agents also collect data for individual processes. These process-level metrics are available on HP-UX and Sun Solaris:
These additional process-level metrics are available on HP-UX:
The data collected through ARM can be integrated with other MeasureWare data. The MeasureWare Transaction Tracker technology is used to provide metrics for an application using ARM. The following metrics are available on both HP-UX and Sun Solaris:
The utility program includes the ability to generate reports on log files. System-wide changes can be found in this way, such as the addition of a new disk device. Reports can also be generated that provide summaries of each application's CPU and disk utilization. To verify that MeasureWare is working correctly, you can use the perfstat “t command, which shows you recent status and error information. GlancePlusGlancePlus is a real-time, graphical, performance monitoring tool from Hewlett-Packard. It is used to monitor the performance and system resource utilization of a single system. Both Motif-based and character-based interfaces are available. The product can be used on HP-UX, Sun Solaris, and many other operating systems. GlancePlus collects information similar to MeasureWare, but samples data more frequently. GlancePlus can be used to graphically view current CPU, memory, swap, and disk activity and utilization at the system level. It can also show application and process information. Transaction information can be shown if the MeasureWare Agent is installed and active. For monitoring applications, the application must be defined. To define an important application, use the configuration file located at /var/opt/perf/parm, which is also used by the Measure Ware and PerfView products. GlancePlus is also capable of setting and receiving performance- related alarms. Customizable rules determine when a system performance problem should be sent as an alarm. The rules are managed by the GlancePlus Adviser. When you select the Edit Adviser Syntax option from the Adviser menu, all the alarm conditions are shown, which you can then modify. The GlancePlus Adviser syntax file (/var/opt/perf/adviser.syntax) contains the symptom and alarm configuration. Additional syntax files can also be used. A condition for an alarm to be sent can be based on rules involving different symptoms. Alarms result in onscreen notification, with color representing the criticality of the alarm. An alarm can also trigger a command or script to be executed automatically. Instead of sending an alarm, GlancePlus can print messages or notify you by executing a Unix command, such as mailx, by using its EXEC feature. Listing 7-6 shows an alarm for the ora_app application. If you know how many processes should be active, GlancePlus can be used to monitor their health. The APP_ALIVE_PROC metric measures the number of processes in this group that were alive during the time interval. The metric could include fractions for processes that terminated during the interval. An alarm could then be sent if APP_ALIVE_PROC is below the expected value for that application, as shown in Listing 7-6. You can also execute the scripts in command mode by typing: glance adviser_only syntax <script file name> In this example, a yellow alert will be sent to the GlancePlus alarm screen if the number of processes for ora_app drops below five. The symptoms are re-evaluated every time interval. GlancePlus allows filters to be used to reduce the amount of information shown. For example, you can set up a filter in the process view to show only the more active system processes. GlancePlus can also show short- term historical information. When selected, the alarm buttons , visible on the main GlancePlus screen, show a history of alarms that have occurred. If Process Resource Manager (PRM) is being used, GlancePlus shows how well PRM application groups are staying within their resource entitlements. From GlancePlus, you can also change PRM process group entitlements . Here are some specific application metrics available from GlancePlus:
If the MeasureWare Agent is also being used, transaction-level information is available. Transactions must be defined by the application using the ARM API. The following are some of the available metrics:
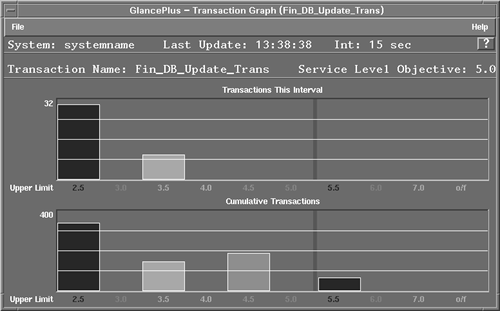
Listing 7-6 Defining alarms in GlancePlus.alarm ora_app:app_alive_proc < 5 start yellow alert "Oracle app died" end reset alert "end of Oracle alert" Figure 7-3 shows how transaction information can be shown together with a service-level objective. The administrator wants to achieve transaction response times under five seconds. The graph shows the number and distribution of transactions that are meeting or exceeding the objective. Figure 7-3. GlancePlus shows transaction data. More than 600 metrics are accessible from GlancePlus. Some of these metrics are discussed in other chapters. The complete list of metrics can be found by using the online help facility. This information can also be found in the directory /opt/perf/paperdocs/gp/C. For further information, visit the HP Application and System Management Web site at http://www.openview.hp.com/solutions/application/. PerfViewPerfView is a graphical performance analysis tool from Hewlett-Packard. It is used to graphically display performance and system resource utilization for one system or for multiple systems simultaneously , so that comparisons can be made. A variety of performance graphs can be displayed. The graphs are based on data collected over a period of time, unlike the real-time graphs of GlancePlus. This tool runs on HP-UX or NT systems and works with data collected by MeasureWare agents. PerfView has three main components:
In addition to graphing and analyzing system resources, process and application resources can be graphed and analyzed using PerfView. PerfView can use the application definitions created by MeasureWare. PerfView can then be used to show a history of a specified application's utilization. PerfView's ability to show history and trend information can be helpful in diagnosing system problems. Graphing performance information can help you to understand whether a persistent problem exists or an anomaly is simply a momentary spike of activity. To diagnose a problem further, PerfView Monitor can allow the user to change time intervals, to try to find the specific time a problem occurred. The graph is redrawn showing the new time period. Process Resource ManagerThe Process Resource Manager is a resource management tool from Hewlett-Packard that is used to balance system resources among PRM groups. PRM groups are configured by the administrator and consist of a set of HP-UX users or applications. PRM is then used to give each PRM group a certain percentage of the CPU, real memory, or disk I/O bandwidth available on the system. PRM ensures that each PRM group gets a minimum percentage of the system's resources, even during heavy loads. PRM can also ensure that a group does not get more than a configured percentage of the CPU. PRM can be used in conjunction with HP GlancePlus to adjust the system configuration. For example, if an administrator detects unwanted system load for a PRM group, GlancePlus can be used to lower that group's entitlement dynamically. The PRM configuration file is /etc/prmconf. In this file, you specify the PRM groups and their desired resource entitlements. Both HP-UX users and applications can belong to PRM groups. An application is referenced by its executable path name. In cases in which alternate process names are specified when a process is started, these alternate process names can also be configured. Wildcards can be used if the exact alternate process name is not known in advance. In this way, PRM provides more granular control over Oracle applications, because the Oracle database server has one executable, but spawns processes for each database instance, with the instance name embedded in the process name. Normally, if one PRM group does not need its system resources, PRM allocates those resources to other groups that may need them. However, PRM can also help with capacity planning by allowing resource maximums to be specified. Thus, if an administrator knows that 25 percent more users will soon be on the system, the administrator can allocate a maximum of 80 percent of system resources to simulate the upcoming load. PRM can also be used to dynamically adjust the workload in a high availability environment. For example, if three MC/ServiceGuard packages are each running with similar PRM entitlements, and one package fails to another system, this can be automatically detected and a new PRM configuration can be applied that gives the two remaining packages higher entitlements. To check the actual resource usage of each PRM group, use the prmmonitor command. GlancePlus can also show this information graphically. |
| I l @ ve RuBoard |
EAN: 2147483647
Pages: 90