Hack 19 Generate Document Keywords
| < Day Day Up > |
| Complement your search strategy with document keywords . Lost information is no use to anybody, and the difference between lost and found is a good collection search strategy. Keywords can play a valuable role in your strategy by giving you insight into a document's topics. Of course, a document's headings, listed in its Table of Contents, provide an outline of its topics. Keywords are different. Derived from the document's full text, they fill in the gaps between the formal, outlined topics and their actual treatments . This hack explains how to find a PDF's keywords using our kw_catcher program. 2.6.1 How the kw_catcher Keyword Generator WorksFinding keywords automatically is a hard problem. To simplify the problem, we are going to make a couple of assumptions. First, the document in question is large50 pages or longer. Second, the document title is knowni.e., we aren't trying to discover the document's global topic, represented by its title. Rather, we are trying to discover subtopics that emerge throughout the document. 2.6.1.1 Stopwords, noise, and signalStopwords are the words that appear most frequently in almost any document, such as the , of , and , to , and so on. Stopwords do not help us identify topics because they are used in all topics. Words that are used with uniform frequency throughout a document are called noise . Stopwords are the best example of noise. For any given document, dozens of other words add to the noise. We are trying to find a document's signal , which is the set of words that communicate a topic. Automatically separating signal from noise is tricky. Recall our assumption that the document title, or global topic, is known. This is because a book's global topic tends to come up consistently throughout the document. For example, the word PDF occurs so regularly throughout this book, it looks like noise. 2.6.1.2 Identifying local topicsDocument word frequency is the number of times a word occurs in a document. By itself, it does not help us because noise words and signal words can occur with any frequency. Instead, we will look at the word frequency in a given window of pages and compare it to the document's global word frequency. For example, frequency occurs ten times in this book, and nine of those occurrences are clustered within these few pages. That certainly distinguishes it from the document's constant noise, so it must be a keyword. This is the central idea of kw_catcher. The program uses a few other tricks to ensure good keyword selection. kw_catcher is free software. 2.6.2 Installing and Using pdftotextWe must convert a PDF into a plain-text file before we can analyze its text for keywords. The Xpdf project (http://www.foolabs.com/xpdf/) includes the command-line utility pdftotext, which does a good job of converting a PDF document into a plain-text file. Xpdf is free software. Windows users can download xpdf-3.00-win32.zip from http://www.foolabs.com/xpdf/download.html. Unzip, and copy pdftotext.exe to a folder in your PATH , such as C:\Windows\system32\ . Macintosh OS X users can download a pdftotext installer from http://www.carsten-bluem.de/downloads/pdftotext_en/. Run pdftotext from the command line, like so: pdftotext input.pdf output.txt In general, kw_catcher can take any plain-text file that uses the formfeed character ( 0x0C ) to mark the end of each page. 2.6.3 Installing and Using kw_catcherVisit http://www.pdfhacks.com/kw_index/ and download kw_index-1.0.zip . This archive contains Windows executables and C++ source code. Unzip, and move kw_catcher.exe and page_refs.exe to a folder in your PATH , such as C:\Windows\system32\ . Or, compile the source to suit your platform. Run kw_catcher from the command line, like so: kw_catcher <window size> <report style> <text input filename> where the arguments are given as follows :
If all goes well, you'll get results such as those shown in Figure 2-4. Figure 2-4. The frequency report, which orders keywords by the number of times they appear in the document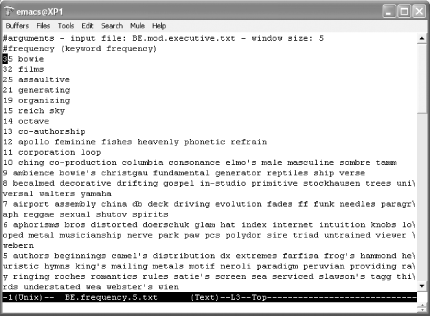 For example, creating a keyword list named mydoc.kw.txt from mydoc.pdf would look something like this: pdftotext mydoc.pdf mydoc.txt kw_catcher 12 keywords_only mydoc.txt > mydoc.kw.txt See [Hack #57] for an example of how you can put these keywords to use. |
| < Day Day Up > |
EAN: 2147483647
Pages: 158