The Problem with Open Networking
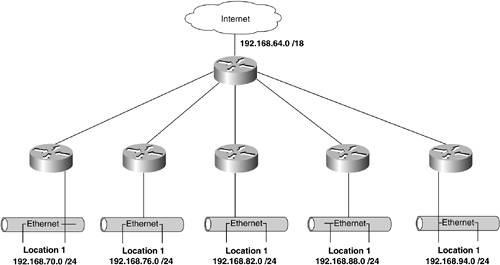
The Problem with "Open" NetworkingAs you saw in Chapter 11, "Internetworking with IP," the problem with open networking begins with the fact that routers are both intelligent and autonomous. You might be able to influence their decision-making processes, but they ultimately choose the best path to each destination networkunless, of course, you abandon dynamic routing protocols in favor of static routes! That leads us to perhaps the biggest problem with open networking: Routers communicate with their neighbors. Although you could effectively argue that is a feature of networking instead of a flaw (and you'd be correct), the point is that this autonomous communication can sometimes result in the propagation of misinformation. Within the confines of a single network, the effects of misinformationor obsolete informationbeing propagated can be quite painful. But the Internet environment has thousands of hierarchically interconnected IP-based networks. The effects of misinformation leaking out onto the Internet can be absolutely devastating! This is an innate feature/flaw of internetworking. Although the impacts are potentially huge, the nature of the Internet is such that misinformation is seldom leaked deliberately. Such events are almost always caused by human error as opposed to human design. Human design typically drives attacks on internetworked systems. Although you wouldn't normally attack an address space, you would use IP addresses to propagate attacks. Attacks made directly on an address space can be considered precursors to "real" attacks. For example, a would-be hacker might test an entire block of addresses using a utility such as ping to determine which specific addresses are in use. In this way, information may be gleaned about the inhabitants of any particular IP network. This information would be used to fuel an actual attack on hosts within that network. The next two sections look at specific problems caused by both human error and human design. This will help prepare you for a deeper look at some of the other challenges that await, as we explore the role of IP addresses in the context of network stability. Address-Based VulnerabilitiesThis section's heading might be a bit misleading; nobody really attacks an IP address space. But, just as IP addresses are the input to the route calculation process, IP addresses are the vector for many network-based attacks. In that sense, IP addresses allow other vulnerabilities to materialize. Some of these vulnerabilities are just the nature of the beast: Having redundant interconnections between multiple networks means that there is more than one path between any given source and destination machine pair. Although that's a key strength of IP internetworking, it also gives rise to some potential weaknesses. Two of the more prominent of these weaknesses are the potential for loops and black holes to occur. LoopsThere is a maxim in routing that is as old as routing itself: It is seldom useful to send a packet out the same interface it came from. But an even older maxim is to build as much redundancy as you can afford. These two truisms appear to conflict, because topological redundancy creates the potential for loops. Figure 12-1 demonstrates this point. It shows a topologically nondiverse network. If any single link or router were to fail, connectivity within this network could be greatly affected. Of course, the impact would vary, depending on what fails. Figure 12-1. A Topologically Nondiverse Network Features All Single Points of Failure
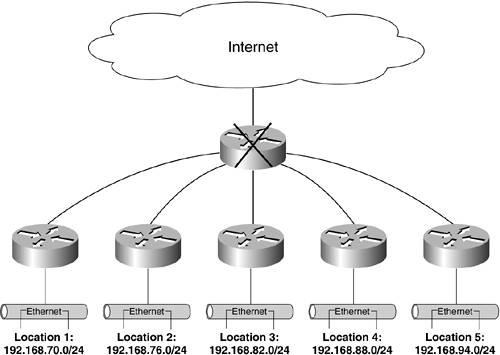
Figure 12-2 shows how the network can be split by the failure of just one router. Of course, that router would happen to be the one that serves as the backbone for this enterprise network! The net effect is five disparate networks that are incapable of communicating with each other. Figure 12-2. A Failure in a Nondiverse Network Can Split the Network
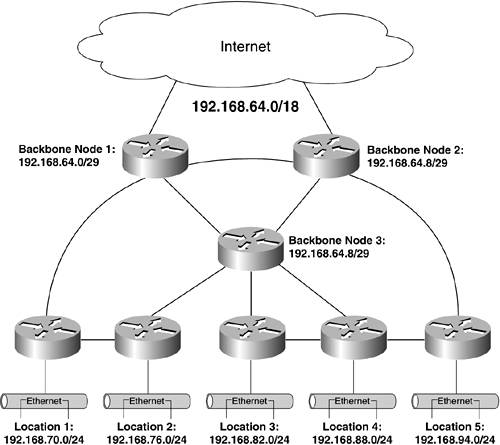
Now, compare the topology shown in Figures 12-1 and 12-2 with the topologically diverse network shown in Figure 12-3. In this scenario, the backbone is a fully meshed ring of routers. If any link fails, the network continues operating unhindered. The only downside is that this creates, topologically, the potential for a routing loop. Look carefully at this network's backbone, and you will see two possible loops. The first exists between the three backbone nodes, and the second is borne of the redundant connections to the Internet. Figure 12-3. Topological Diversity Guards Against Failure But Creates the Potential for Loops
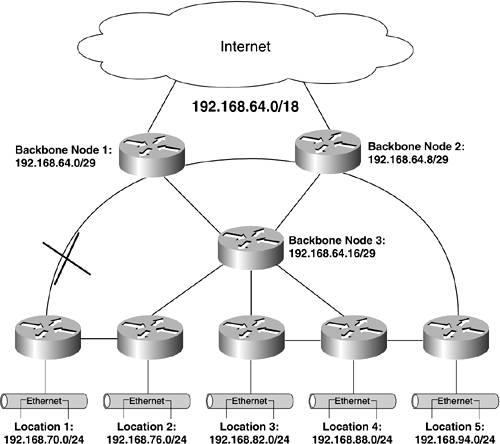
Having a topological loop is a good thing; having a routing loop occur over a topological loop is bad! A routing loop can occur only if the network destabilizes. In other words, something changed the network's topologya component or link failure, a new circuit's being added, and so on. The network has left its previously steady state, and the routers within that network are actively exchanging information in an attempt to determine the network's new shape. Figure 12-4 shows the sample network with a failure. The failure causes network 192.168.70.0/24 to become temporarily unavailable to the rest of the network. It is connected to the backbone via Node 1, and that is the preferred path. All the routers in the network know about 192.168.70.0/24, and they forward IP packets destined for hosts within that network address to Node 1. Thus, one of the backbone routers knows almost immediately that this network has become unreachable, and the other two temporarily persist in the belief that it is still available. This creates the possibility that two of the network routers accept that the other two (which aren't directly connected to 192.168.70.0/24, but they don't know that) still have a valid route to that network. Figure 12-4. A Failure Causes Different Routers to Temporarily Have Different Opinions About a Network's Reachability
The end result is that packets can be sent in circles because of the imperfect knowledge about the network's topology caused by the router's failure. The routers will eventually figure out that network 192.168.70.0/24 is still accessible via the router at Location 2, but they will have to communicate with each other for a while to figure that out. This process, known as convergence, is necessary for networks to dynamically route around problems. However, it also creates a very vulnerable state in which the routers might not be able to deliver packets to known destinations. Worse, until the process ends, the routers can't really know if any particular destination is valid or invalid. And, because it takes time for new information to be fully propagated throughout the network, it is most likely that different routers will have different information about the network. The trick becomes figuring out which information is good, and which is old and obsolete. Fortunately, looping caused by routers sharing slightly out-of-date information with each other is a well-understood phenomenon. Virtually every routing protocol comes equipped with stability-enhancing mechanisms designed to protect your network from loops. The best approach to preventing routing loops is to trust your routing protocols to do their job properly. That requires you to understand them and configure them carefully. More importantly, you must configure them consistently on each interface within your network. The bottom line is that you want loops to exist physically; you just don't want your packets traveling in circles until they die! Black HolesAnother interesting by-product of building internetworks using intelligent, autonomous devices (routers) is that they can communicate misinformation. Sometimes, misinformation can cause a legitimate route to a legitimate network address to be invalidated. Worse, because routers communicate with each other, the invalidated network address could quickly find itself null and void throughout the Internet. Thus, a perfectly functioning network would be isolated from external communications. This is known as a black hole because, from the Internet's perspective, the network has disappeared without a trace! Network addresses can become blackholed either unintentionally or intentionally for a variety of reasons:
The imagination runs wild with various scenarios in which an IP network address is configured as a null routeeither intentionally or unintentionallywith far-reaching consequences. Null routes or black holes are a legitimate tool, but their use requires a mastery of internetworking and consistent router configuration. Otherwise, the results can be unintentional and catastrophic. For example, every router in the Internet could refuse to recognize a specific network address block. Routers can be configured to advertise even statically configured routes to upstream routers. This is particularly useful in an ISP environment, because customer routers are configured to statically route everything that isn't local out of the ISP connection's interface. To the ISP network, the network block assigned to that statically routed customer is known as a static route. Yet the ISP is obligated to let the rest of the Internet know about that customer address. Thus, the ISP might be inclined to advertise even static routes into the Internet. A problem would occur if that ISP's customer decided to use a null route for a specific network address to prevent its end users from accessing a particular destination. The potential exists for that null route to be communicated to the ISP and for the ISP to recommunicate it to the rest of the Internet. That would be bad. Of course, this isn't how null routes should be used. Additionally, the routers would have to be configured to advertise static routes to external networks in order for this scenario to be a problem. Although this might sound far-fetched, it can happen (and it has). If a network administrator wanted to prevent a Web site from being accessed, routers let you create permissions lists (known more accurately as access control lists [ACLs]) that locally constrain accessibility. ACLs are programmed per interface and are not shared with other routers. The point is that null routes can be used inappropriately, and that can have far-reaching and unforeseen consequences. That is why I have listed black holes as a potential vulnerability of the IP address space that can be exploited. Address-Based AttacksAlthough it would be misleading to say that someone can attack your IP address space, there are ways to exploit an address space to launch attacks. In fact, because the address space is the way to reach an IP-capable host, the only way to reach that host is to use its address. For this reason, a hacker's first task is to scan an IP address space. Automated tools exist that let someone test an address space to see which addresses are "live" and which are unassigned. Live addresses warrant further scrutiny. So begins the arduous process of testing for known holes and vulnerabilities to see what has been left unattended and can be exploited. This process is frequently called port scanning or, more metaphorically, knob turning. Not unlike a thief who wanders up and down a row of homes doing nothing more than turning doorknobs, the hacker is looking for an easy way in. A hacker who succeeds in this attempt to gain illicit entry to a host has a wealth of options at his or her disposal. First, if there's anything of value on that box, it's gone. The hacker can steal it, delete it, modify it, and so on. Second, it might be possible to learn enough from this compromised host to gain access to other systems. Such secondary damage may be direct (for example, the hacker then logs directly into that new host) or indirect (the hacker uses the compromised machine to gain access to that new host). Exploiting a host in this manner is particularly nefarious, because the attacker appears to be a legitimate user based on the source IP address of the affected IP packets. And it all started with finding an IP address to a host that wasn't secured properly! NOTE There are no panaceas with respect to securing a networked computing environment. Instead, security is a function of many different layers that range from a coherent set of methods and procedures to physical security to a dizzying array of both network- and host-based security capabilities. How much damage an attack causes depends on how carefully the overall security of the networked computing environment was crafted. An attack begins with the address space but ends with defenses installed virtually everywhere else. Other specific attacks that exploit an address space include
These attacks directly use IP addresses and are sometimes used in combination to achieve greater impact. We'll look at each one briefly to round out your appreciation of the vulnerability of the IP address space in an open network. Man in the MiddleThe man-in-the-middle attack is a fairly well-known and mature threat. Essentially, someone inserts a device into a network that grabs packets that are streaming past. Those packets are then modified and placed back on the network for forwarding to their original destination. A quick Net search should lead you to some programs and/or source code that you can use to launch this type of attackit's really that easy! This form of attack affords the perpetrator the opportunity to steal the data contained in the IP packets lifted off the network. The worst part of a man-in-the-middle attack is that it can completely defeat even sophisticated authentication mechanisms. The attacker can simply wait until after a communication session is established, which means that authentication has been completed, before starting to intercept packets. The existence of such an attack doesn't directly threaten your network's stability. But it is an exploit that can target a specific destination IP address. A mild form of man in the middle is called eavesdropping. Eavesdropping differs only in that the perpetrator just copies IP packets off the network without modifying them in any way. This is tantamount to petty theft, whereas man in the middle more closely resembles vandalism. Session HijackingAn interesting twist on the man-in-the-middle attack is session hijacking. The name should be self-apparent. Someone gains physical access to the network, initiates a man-in-the-middle attack (ostensibly after authentication with a destination host has occurred), and then hijacks that session. In this manner, a hacker can illicitly gain full access to a destination computer by assuming the identity of a legitimate user. The legitimate user sees the login as successful but then is cut off. Subsequent attempts to log back in might be met with an error message that indicates the user ID is already in use. What a hacker does after hijacking a session depends greatly on that individual. The potential for damage is limited only by the access permissions of the user whose session was hijacked and the hacker's imagination. The hacker can access files for copying to his or her desktop, delete or modify files, or use the session to launch an attack on another host on the same network. Address SpoofingAddress spoofing is an old game. It entails mimicking someone else's IP address for the sake of perpetrating an attack. The IP address doesn't necessarily have to be a particular person's address. Spoofed addresses are typically selected either at random or to appear to be from a specific entity's network. Using a fictitious source IP address nicely covers the attacker's tracks and makes getting caught less likely. Of course, spoofing an IP address limits the types of attacks you can perpetrate. In simple terms, you have made up an IP address. This IP address gets imprinted in each IP packet you generate as the source IP address. The source IP address is used by the network and the destination machine to route responses back to the correct machine. If that source address is fictitious, there's no way to route responses properly. Response packets are sent to a different host on a different network (the host that is the legitimate possessor of the spoofed address), or they can't be delivered at all! More importantly, it has become quite common for hosts to rely on source address authentication to ensure that the machine they are communicating with really is the one it purports to be. You might be thinking that address spoofing is obsolete. It isn't. Many a successful hack has been launched using a spoofed address. Remember, the goal of an attack isn't always to establish two-way communication. Some attacks are quite successful using just inbound communications without requiring a response. One such attack is the Denial of Service attack. Denial of ServiceA Denial of Service (DoS) attack is a bit more insidious than some other forms of attacks because conventional defenses are powerless to stop it. A particular computer might be targeted, but that computer can remain up and functional yet utterly unreachable to its legitimate user base. In essence, the perpetrator of this attack isn't trying to steal or damage data or do any physical harm. Instead, the perpetrator simply tries to hurt his or her victim by denying that victim's user community the use of one of its assets. Service can be denied to legitimate users in a variety of ways. For example, a sufficiently large quantity of spurious traffic can be generated in the hopes of overloading either a computer or some portion of the network upstream from that targeted computer. Such attacks would likely require multiple source machines working in concert to attack the target. All those machines could spoof their source address in the hopes of avoiding detection. Another form of DoS attack is to pass illegal communication parameters to a target in the hopes of causing it to crash. NOTE A DoS attack that features a simultaneous, coordinated attack from multiple source machines is called a Distributed Denial of Service (DDoS) attack. The best-known example of a DDoS attack is the smurf attack (discussed in the next section). Either way, the "damage" is transitory, and service can be restored as soon as the spurious traffic ceases or the targeted machine is rebooted. I'm not trying to minimize the potential impact of a DoS attack. Many companies make their living via online services. Thus, you could literally put a company out of business by doing nothing more than preventing its customers from accessing its Web site. Far from being merely an intellectually stimulating what-if scenario, DoS attacks are propagated daily. In recent years, such attacks have put some of the Internet's most prominent Web sites out of service. smurf AttackDespite the cute name and the imagery it conjures up, there's nothing funny about a smurf attack. smurf (lowercase letters used intentionally) is a relatively simple, yet highly effective, form of DDoS attack. This attack uses the Internet Control Message Protocol (ICMP, a native component of TCP/IP protocol suites). One of the utilities embedded in ICMP is ping (an acronym for packet Internet groperdon't ask me why, though). ping is very commonly used to test the availability of certain destinations. Unto itself, it is benign, and even quite useful. However, smurf can misuse it in a nefarious way. The way a smurf attack works is quite simple. The hacker installs smurf on a computer. This requires the hacker to somehow gain entry to a computer by guessing passwords, hijacking someone's session, or any one of a seemingly infinite array of possibilities. The hacked machine starts continuously pinging one or more networkswith all their attached hostsusing IP broadcast addresses. Every host that receives the broadcast ping message is obliged to respond with its availability. The result is that the hacked machine gets overwhelmed with inbound ping responses. The good news is that there are many ways to combat potential smurf attacks. The bad news is that smurf is just one of an ever-expanding collection of DDoS attack mechanisms. The stability of your network requires constant vigilance! |
EAN: 2147483647
Pages: 118
- ERP Systems Impact on Organizations
- Distributed Data Warehouse for Geo-spatial Services
- Intrinsic and Contextual Data Quality: The Effect of Media and Personal Involvement
- Healthcare Information: From Administrative to Practice Databases
- Relevance and Micro-Relevance for the Professional as Determinants of IT-Diffusion and IT-Use in Healthcare