High Availability Rethought (Peer-Based)
| Why a new approach? It is clear that traditional pairwise failover approaches are sound because they are well understood and widely deployed. Just because it will work does not mean that it is the right tool for the job. Trains are a fabulous method of mass transportation; however, bus lines still exist. Why? There is a market for them. The analogy is fitting when we consider the dynamic business needs of websites. Trains are great if you know your waypoints, and you know they will not be changing. You can invest in laying the tracks and building the infrastructure. On the other hand, if you foresee the traffic patterns changing, and waypoints and routes coming and going, then buses are a more flexible and a more fitting solution. Traditional high availability systems take the classic failover approach. System A is responsible for a task, but should it fail, System B can seamlessly take over its responsibilities. This leads to a lot of system pairs out in the world where one machine is completely idle. Let's look at the high availability between the two web switches in the previous example. The roles and responsibilities of those switches are clear. The switches work together to ensure that a service is provided. The devices must work together to accomplish a task of load balancing requests across two back-end web servers. Should the active one fail, the backup assumes the responsibilities and obligations of the active role. If we glance back at the two-machine www.example.com example, we notice that the goal was simply to achieve high availability. The two machines were not needed to increase capacity, rather just to provide failover. Why can't we employ the same logic used by the ServerIron pairs on the web servers themselves and have one web server assume the responsibilities of the other should it fail? This is simple to accomplish with two machines where one is active. In fact, it is fairly easy, algorithmically, to solve with N machines when one is active. We can use a protocol such as VRRP or CARP to detect failures and promote a passive server into the role of the active server. However, this approach is not commonly used. As soon as the website exceeds the capacity limits of a single server, multiple servers must be active to concurrently service clients for demand to be met. This leads to the obvious question: Why can't more than one of them be active? The issues with multiple active machines in a high availability setup are responsibility and agreement. How can you be sure that all the responsibilities are being satisfied, while at the same time ensuring that no single responsibility is being handled by two machines concurrently? Some systems accomplish this by chaining master-slave so that every machine is a master of one service and a slave of another. This is overly complicated, prone to failure, and I submit to you that this answer is simply wrong. The answer is peer-based high availability. Now that we are speaking of more than a pair of machines, we introduce the concept of a cluster. Although the concept may be obvious, let's put a clear definition on it anyway.
Cluster: A bunch; a number of things of the same kind gathered together. In computers, a set of like machines providing a particular service united to increase robustness and/or performance. Additionally, we will refer to a cluster as a set of machines working in unison to accomplish a specific goal or set of goals. These goals are services that are the responsibility of that cluster to keep running continuously and efficiently. In a peer-based approach, the cluster is responsible for providing a set of services, but each available machine will negotiate and agree to assume responsibility over a subset of those services. Let's take the two-node web cluster as an example. We have two machines with the IP addresses 10.10.10.1 and 10.10.10.2, respectively. Now, if machine one fails, one of those IP addresses will become inaccessible, and the cluster will have defaulted on its responsibility to serve traffic over that IP address. In the peer-based approach, the cluster of two machines is responsible for providing service over those two IP addresses. To which machine those IP addresses are assigned is irrelevant. More so, we don't care whether each has one or whether one has two and the other noneit matters not to the task at hand. Rather, you simply want a guarantee that if at least one machine is still standing the cluster will not default on its responsibilities. So far, all the examples have been N services (web service from a particular IP address) and M machines (web servers) where N and M are equal. So, it makes sense that in a zero failure environment, each machine assumes the responsibility for providing service over a single IP address. If one machine were to fail, another machine would assume its responsibility, and it really does not matter which machine steps up to that challenge. However, 1:1 is not the only way peer-based high availability can work. N:M is possible as well N < M and N > M, though it certainly makes sense that M is greater than one or you fail to accomplish the whole high availability goal! This new paradigm for high availability is interesting, but what does it really buy us? The following lists a few advantages:
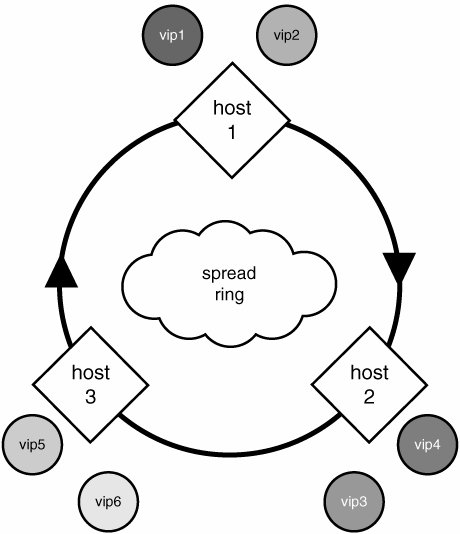
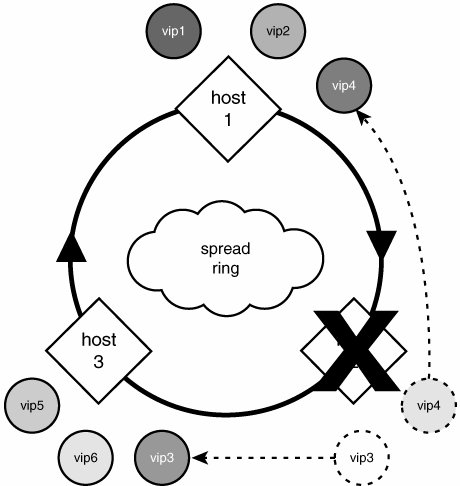
Unfortunately, there is a negative aspect of pure peer-based high availability for services such as the web. Peer-based highly available systems really require multiple IP addresses for more than a single machine in the cluster to be used simultaneously. This type of IP address consumption does not meld well with IP unfriendly services such as SSL. Although it works fine with a few SSL sites, more than a handful becomes unwieldy. Services such as HTTP over secure socket layer (SSL) (also known as https://) do not allow distinct services to be provided from the same IP address. The reason is because when a client connects, it immediately negotiates with the server a secure, authenticated connection by reviewing the server'certificate presented by the server and possibly handing over a client certificate of its own. The catch is that the client doesn't have the capability to ask for a specific certificate; it is simply handed the certificate. This SSL certificate has the common name of the site www.example.com encoded in it, and the client will check, among other things, that the name inside the certificate matches exactly the name of the service it was attempting to contact. This prevents spoofing of identities. Directly, this means that a single IP address can serve at most one common name over SSL. So, unlike plain HTTP, which can serve virtually unlimited distinctly named websites from a single IP address, 1,000 SSL-capable unique websites would require at least 1,000 unique IP addresses. This clashes strongly with idea of publishing several IP addresses for each public service. This is not a shortcoming of peer-based high availability, but rather a shortcoming of this use of peer-based high availability. Peer-Based High Availability in the Real WorldWackamole is a software product from the Johns Hopkins University's Center for Networking and Distributed Systems. It is a simple, yet powerful, open source implementation of peer-based high availability. We won't dig in too deeply (that is, the configuration snippets here are incomplete) because this is intended only to illustrate the concept of peer-based configurations. Chapter 6, "Static Content Serving for Speed and Glory," delves into the gory details of installing and configuring Wackamole for a highly available, high-throughput image-serving cluster. Wackamole sits atop Spreada group communication toolkit that is rapidly gaining popularity. Through Spread, it coordinates with other peer machines in the cluster to determine safely (deterministically) who will take responsibility for the virtual IP addresses advertised by that cluster. To better demonstrate peer-based advantages, let's turn once again to the www.example.com example. We can easily adapt the previous example to use the peer-based paradigm. Instead of exposing the web service over a single publicly accessible IP address, we now advertise six IP addresses: 192.168.0.11 through 192.168.0.16. The relevant portion of the example.com Bind zone file follows: www.example.com. 5M IN A 192.168.0.11 5M IN A 192.168.0.12 5M IN A 192.168.0.13 5M IN A 192.168.0.14 5M IN A 192.168.0.15 5M IN A 192.168.0.16 To better illustrate the setup, we deploy three physical web servers responsible for making the www.example.com service available. wackamole.conf VirtualInterfaces { { eth0:192.168.0.11/32 } { eth0:192.168.0.12/32 } { eth0:192.168.0.13/32 } { eth0:192.168.0.14/32 } { eth0:192.168.0.15/32 } { eth0:192.168.0.16/32 } } A configuration file is provided to the Wackamole daemon that describes the full set of six virtual IP addresses for which the cluster is responsible. The daemon connects to Spread and joins a group unique to that cluster. By joining this group, each Wackamole instance has visibility to the other instances running Wackamole in the cluster. Those that are visible are considered up and running, and those that are not are considered down and out. Using the strong group membership semantics of Spread, the set of running Wackamole daemons can quickly and deterministically decide which machines will assume which IP addresses. During normal operation, when all machines are functioning properly, each machine has two IP addresses as shown in Figure 4.6. When a Wackamole instance stops participating in the group (for any reason, be it a node failure or an administrative decision), a new membership is established, and steps are automatically taken to juggle IP addresses, as necessary, to ensure all configured IP addresses are spoken for. Figure 4.7 illustrates this "juggling" effect. Figure 4.6. A Wackamole cluster in perfect health. Figure 4.7. A Wackamole cluster following a node failure. If a single IP address is being managed by a cluster of two machines, at most one machine will be responsible for that IP, and you will have a similar configuration to the hot-standby setup discussed earlier. What's new and different is the ability to add a handful more machines to the cluster and have seamless failover and N-1 fault tolerance. And yes, 1 fault tolerant and N-1 fault tolerant are the same with two machines, but trying to make that argument is a good way to look stupid. The new concept introduced by peer-based high availability is that more than one machine may be actively working at any given time. Although it is possible to architect a solution using traditional hot-standby failover that will exercise multiple machines, it is atypical and not the intention of the technology. In the peer-based approach, it is intrinsicoccurring any time the number of managed IP addresses exceeds one. To operate in this type of environment, the services must be provided by each machine authoritatively, and their concurrent use must not cause malfunctions. A perfect example of a service that always does well in this paradigm is DNS. Web services are usually conducive to concurrent operations (the same is required when load balancing across a cluster), whereas database services often pose challenges so tremendous that fundamental sacrifices must be made in their use or their performance. It is important to keep in mind that although some services are not easily benefited by peer-based high availability with more than one IP address offered, they are still benefited by simple N-way hot-standby. Many databases, for example, work well out-of-the-box so long as only one is active. When a failure occurs, a new master is chosen or elected, and it assumes the responsibility of providing the database service over the single advertised IP address, and life continues on normally. Wackamole can be programmed to elect a new master and perform whatever database administration is necessary to place the newly appointed database server in master mode. We will delve deeper into distributed multimaster databases in Chapter 8 and gain a better understanding of the tremendous challenges previously mentioned. Growing SeamlesslyAs mentioned earlier, peer-based systems provide N services from M machines, where N and M could be both larger and smaller than each other. We have not touched on providing more services than machines. If we expose 10 virtual IP addresses from a cluster of 10 machines, what must be done to increase the cluster size by 1 machine? If we simply add another machine, it acts as a global spare. There are no virtual IP addresses to juggle around because they are all spoken for. If we were to expose 50 virtual IP addresses from a cluster of 10 machines, each machine would be responsible for 5 of them. If we were to add an 11th machine, each machine would relinquish responsibility over some of their 5 IPs to help even out the responsibility. Wackamole, in its default configuration, would cause 5 of the machines to relinquish control of 1 of their 5 IP addresses to result in 6 machines with 5 virtual IPs and 5 machines with 4 virtual IPs. |
EAN: 2147483647
Pages: 114
- Structures, Processes and Relational Mechanisms for IT Governance
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Governance in IT Outsourcing Partnerships
- The Evolution of IT Governance at NB Power
- Governance Structures for IT in the Health Care Industry