Diverging from the Web: High Availability for Email, DNS, and So On
| High availability has many uses outside the Web. Any mission-critical system benefits by having fault-tolerant components. The most commonly ignored system components are networking equipment such as firewalls, switches, and routers. The reason for this is the term and the roles the various architects and engineers play in designing, building, and maintaining the overall architecture. Consider the design of a modern automobile. Several multidisciplinary teams contribute to the final product. If the safety team, the engineering team, and the aesthetic design team all work together on the first draft, and then all further revisions leading to the final design are performed by the safety team, you will end up with one ugly car. Think of the network engineering team as designing the suspension for the car. Often, systems engineers (the performance and engine mechanics) and developers (design and functionality specialists) are the two teams that work closely together to accomplish business goals, adding cup holders, adding automatic locks and windows, and upgrading the engine and exhaust systems. After several additions and subtractions to the car's functionality and upgrading or downgrading a few core components, the car is going to act differently. There are no guarantees that the old suspension is adequate for the car. In fact, the old suspension system may be unsafe! It is unfortunate that network engineers don't play a larger role in ongoing maintenance of production architectures. However, it is understandable. After you build a networking infrastructure, the people who conduct business over it rarely think about it so long as it is functioning correctly. Basically, it has to break to get attention. This stems from the underlying reliability of networking equipment. If you install a switch in your environment, it will likely require zero administration for at least a year after the initial setup. It will continue to function. This leads to the misconception that it would not benefit from maintenance. As soon as another device is plugged in to that switch, it may no longer be optimally configured. Artisans of different crafts have different focuses. A systems engineer looks at making sure that the system continues to work in light of a failure. However, many SAs are not cognizant that if the single switch they are plugged in to fails, all their work is for naught. It is immensely valuable for SAs to learn enough network engineering to know when they need review or assistance. Network administrators likely will have never heard of peer-based high availability. The network world is a hardware one, full of black box products and proprietary solutions. Only recently has it become acceptable to perform routing on general-purpose server hardwareand it certainly isn't commonplace. Given that, protocols such as HSRP and VRRP are understood and deployed throughout almost every production IP network environment in the world. The world is a different place now that you can deploy a $1,000 Intel-based commodity server running Linux or FreeBSD as a corporate or stub router attached to several 100Mbps and Gigabit networks with features such as multicast, IPSEC, IP tunneling, VoIP gateways, and more advanced IP network service in addition to a full set of standard routing protocols. Implementing smarter application level protocols is now possible because deploying those applications on these routers is easy: they run widely popular, free, open source operating systems. But in another respect, it is much easier to write an application for FreeBSD or Linux than it is for Cisco IOS. So, why not use commodity routers in production? The vendor argument is that they are not proven or enterprise ready. Because a slew of companies are on the market ready and willing to support these systems in production, the only remaining argument is high availability. Free implementations of the VRRP protocol are available, but there is no good reason not to apply peer-based high availability to this problem as well. Pouring ConcreteAt one of our installations, we have a production environment that sits in a class C network (256 IP addresses). This environment must monitor thousands of services around the world for availability and functional correctness. The services that it monitors are local and distributed across a handful of sites on networks far away. So, connectedness is a necessity. Monitoring service availability for publicly accessible services is easy: making web requests, performing DNS lookups, sending mail, checking mailboxes, and so on. Monitoring more private information requires more private channels. In this environment, our router is responsible for routing between three physically attached subnets and six different private IP networks over IPSEC VPNs, several of which require considerable bandwidth. Purchasing a router from a leading network vendor such as Cisco, Juniper, or Foundry that supports routing three 100Mbps networks and six IPSEC connections would be rather expensive. Consider that we manage the installations at the other end of those VPNs as well. All need to be fault-tolerant. So, although the math is simple, things just don't add up. I need two routers at the primary location and, at the minimum, two VPN devices at the five other locations. Let's take a look at a cost-effective solution. We buy two inexpensive 1U commodity servers with three Ethernet controllers. We install FreeBSD 4 on both boxes, configure IPSEC using Kame/Racoon, and set up our routing. Our three subnets are
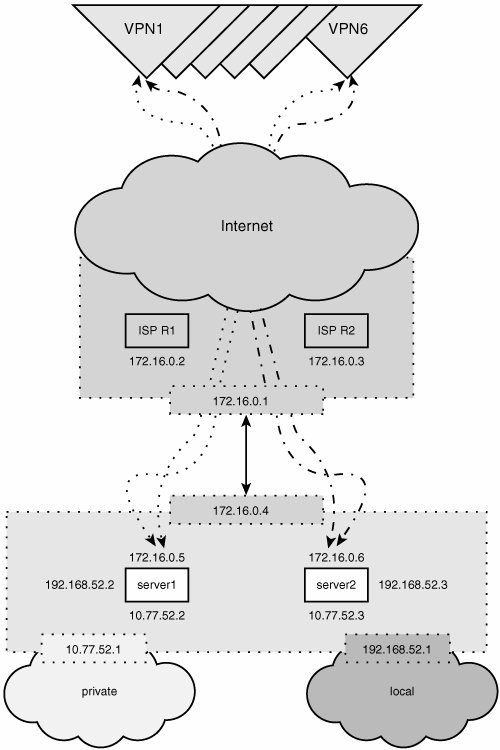
Our hosting provider has the router at 172.16.0.1, and we route all Internet-bound traffic through that IP. The hosting provider routes all traffic to 192.168.52.0/24 through 172.16.0.4 (our router's IP). Because our router must provide routing to all the machines on the private and local networks, it must have an IP address (for those machines to use as a default route). We keep it simple and standard by using 10.77.52.1 and 192.168.52.1, respectively. Each box has three network interfaces to attach it to the three physical networks we plan to route. We have two FreeBSD boxes to apply to this problem, so we will give them each their own IP address on each network. This first box receives 10.77.52.2, 192.168.52.2, and 172.16.0.5, and the second box is assigned 10.77.52.3, 192.168.52.3, and 172.16.0.6, as shown in Figure 4.8. Figure 4.8. A real-world, fault-tolerant network ingress. Using Wackamole, we can tell these two machines that they share the responsibility for being the routera residing at 10.77.52.1, 192.168.52.1, and 172.16.0.4. wackamole.conf snippet: # We don't care who is the master Prefer None # We are responsible for a single virtual interface composed of set # of three IP addresses. It is important that if a machine takes # responsibility then it must acquire ALL three IPs. VirtualInterfaces { { fxp2:10.77.52.1/32 fxp1:192.168.52.1/32 fxp0:172.16.0.4/32 } } With Wackamole started on both machines, we see the following: root@server1 # uptime 11:06PM up 157 days, 18:07, 1 user, load averages: 0.00, 0.00, 0.00 root@server1 # ifconfig a fxp0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1500 inet 172.16.0.5 netmask 0xfffffff0 broadcast 63.236.106.111 inet6 fe80::2d0:a8ff:fe00:518b%fxp0 prefixlen 64 scopeid 0x1 ether 00:d0:a8:00:51:8b media: Ethernet autoselect (100baseTX <full-duplex>) status: active fxp1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 inet 192.168.52.2 netmask 0xffffff00 broadcast 66.77.52.255 inet6 fe80::2d0:a8ff:fe00:518c%fxp1 prefixlen 64 scopeid 0x2 ether 00:d0:a8:00:51:8c media: Ethernet autoselect (100baseTX <full-duplex>) status: active fxp2: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 inet 10.77.52.2 netmask 0xfffffe00 broadcast 10.77.53.255 inet6 fe80::202:b3ff:fe5f:c68f%fxp2 prefixlen 64 scopeid 0x3 ether 00:02:b3:5f:c6:8f media: Ethernet autoselect (100baseTX <full-duplex>) status: active root@server2 # uptime 11:07PM up 338 days, 13:59, 2 users, load averages: 0.46, 0.39, 0.34 root@server2 # ifconfig a fxp0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 inet 172.16.0.6 netmask 0xfffffff0 broadcast 63.236.106.111 inet6 fe80::2d0:a8ff:fe00:61e8%fxp0 prefixlen 64 scopeid 0x1 inet 172.16.0.4 netmask 0xffffffff broadcast 63.236.106.102 ether 00:d0:a8:00:61:e8 media: Ethernet autoselect (100baseTX <full-duplex>) status: active fxp1: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 inet 192.168.52.3 netmask 0xffffff00 broadcast 66.77.52.255 inet6 fe80::2d0:a8ff:fe00:61e9%fxp1 prefixlen 64 scopeid 0x2 inet 192.168.52.1 netmask 0xffffffff broadcast 66.77.52.1 ether 00:d0:a8:00:61:e9 media: Ethernet autoselect (100baseTX <full-duplex>) status: active fxp2: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 1500 inet 10.77.52.3 netmask 0xfffffe00 broadcast 10.255.255.255 inet6 fe80::202:b3ff:fe5f:bf0c%fxp2 prefixlen 64 scopeid 0x3 inet 10.77.52.1 netmask 0xffffffff broadcast 10.77.52.1 ether 00:02:b3:5f:bf:0c media: Ethernet autoselect (100baseTX <full-duplex>) status: active The preceding ifconfig outputs show that server2 currently has all three IP addresses that are acting as the default route. If server2 were to crash now, server1 would acquire the three IP addresses specified in the wackamole.conf file within a second or two, and routing would continue as if nothing had happened at all. The uptime was run to illustrate the stability of the systems despite running on commodity hardware. The IPSEC VPNs are orchestrated with FreeBSD gif IP-IP tunneling and KAME and Racoon. After the IP tunnels are configured, they are utilized by routing traffic over them via FreeBSD's routing table. Because no additional physical IP addresses are added, the wackamole.conf file remains untouched. The specifics of the IPSEC implementation are outside the scope of this book. This example demonstrates how peer-based high availability can provide what current networking failover protocols provide. However, two things are important to note:
|
EAN: 2147483647
Pages: 114
- Chapter III Two Models of Online Patronage: Why Do Consumers Shop on the Internet?
- Chapter V Consumer Complaint Behavior in the Online Environment
- Chapter IX Extrinsic Plus Intrinsic Human Factors Influencing the Web Usage
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability
- Chapter XVIII Web Systems Design, Litigation, and Online Consumer Behavior