3.5. Examples Let us now look at several miscellaneous examples to put some of the concepts we have learned into practice. We will discuss the following specific examples: Assembly code corresponding to a recursive factorial function Implementation of an atomic compare-and-store function Rerouting function calls Using a cycle-accurate 970FX simulator
3.5.1. A Recursive Factorial Function In this example, we will understand how the assembly code corresponding to a simple, high-level C function works. The function is shown in Figure 326. It recursively computes the factorial of its integer argument. Figure 326. A recursive function to compute factorials // factorial.c int factorial(int n) { if (n > 0) return n * factorial(n - 1); else return 1; } $ gcc -Wall -S factorial.c
|
The GCC command line shown in Figure 326 generates an assembly file named factorial.s. Figure 327 shows an annotated version of the contents of this file. Figure 327. Annotated assembly listing for the function shown in Figure 326 ; factorial.s .section __TEXT,__text .globl _factorial _factorial: ; LR contains the return address, copy LR to r0. mflr r0 ; Store multiple words (the registers r30 and r31) to the address starting ; at [-8 + r1]. An stmw instruction is of the form "stmw rS,d(rA)" -- it ; stores n consecutive words starting at the effective address (rA|0)+d. ; The words come from the low-order 32 bits of GPRs rS through r31. In ; this case, rS is r30, so two words are stored. stmw r30,-8(r1) ; Save LR in the "saved LR" word of the linkage area of our caller. stw r0,8(r1) ; Grow the stack by 96 bytes: ; ; * 24 bytes for our linkage area ; * 32 bytes for 8 words' worth of arguments to functions we will call ; (we actually use only one word) ; * 8 bytes of padding ; * 16 bytes for local variables (we actually use only one word) ; * 16 bytes for saving GPRs (such as r30 and r31) ; ; An stwu instruction is of the form "stwu rS, d(rA)" -- it stores the ; contents of the low-order 32 bits of rS into the memory word addressed ; by (rA)+d. The latter (the effective address) is also placed into rA. ; In this case, the contents of r1 are stored at (r1)-96, and the address ; (r1)-96 is placed into r1. In other words, the old stack pointer is ; stored and r1 gets the new stack pointer. stwu r1,-96(r1) ; Copy current stack pointer to r30, which will be our frame pointer -- ; that is, the base register for accessing local variables, etc. mr r30,r1 ; r3 contains our first parameter ; ; Our caller contains space for the corresponding argument just below its ; linkage area, 24 bytes away from the original stack pointer (before we ; grew the stack): 96 + 24 = 120 ; store the parameter word in the caller's space. stw r3,120(r30) ; Now access n, the first parameter, from the caller's parameter area. ; Copy n into r0. ; We could also use "mr" to copy from r3 to r0. lwz r0,120(r30) ; Compare n with 0, placing result in cr7 (corresponds to the C line). ; "if (n > 0)") cmpwi cr7,r0,0 ; n is less than or equal to 0: we are done. Branch to factorial0. ble cr7,factorial0 ; Copy n to r2 (this is Darwin, so r2 is available). lwz r2,120(r30) ; Decrement n by 1, and place the result in r0. addi r0,r2,-1 ; Copy r0 (that is, n - 1) to r3. ; r3 is the first argument to the function that we will call: ourselves. mr r3,r0 ; Recurse. bl _factorial ; r3 contains the return value. ; Copy r3 to r2 mr r2,r3 ; Retrieve n (the original value, before we decremented it by 1), placing ; it in r0. lwz r0,120(r30) ; Multiply n and the return value (factorial(n - 1)), placing the result ; in r0. mullw r0,r2,r0 ; Store the result in a temporary variable on the stack. stw r0,64(r30) ; We are all done: get out of here. b done factorial0: ; We need to return 1 for factorial(n), if n <= 0. li r0,1 ; Store the return value in a temporary variable on the stack. stw r0,64(r30) done: ; Load the return value from its temporary location into r3. lwz r3,64(r30) ; Restore the frame ("pop" the stack) by placing the first word in the ; linkage area into r1. ; ; The first word is the back chain to our caller. lwz r1,0(r1) ; Retrieve the LR value we placed in the caller's linkage area and place ; it in r0. lwz r0,8(r1) ; Load LR with the value in r0. mtlr r0 ; Load multiple words from the address starting at [-8 + r1] into r30 ; and r31. lmw r30,-8(r1) ; Go back to the caller. blr
|
Noting Annotations Whereas the listing in Figure 327 is hand-annotated, GCC can produce certain types of annotated output that may be useful in some debugging scenarios. For example, the -dA option annotates the assembler output with some minimal debugging information; the -dp option annotates each assembly mnemonic with a comment indicating which pattern and alternative were used; the -dP option intersperses assembly-language lines with transcripts of the register transfer language (RTL); and so on. |
3.5.2. An Atomic Compare-and-Store Function We came across the load-and-reserve-conditional (lwarx, ldarx) and store-conditional (stwcx., stdcx.) instructions earlier in this chapter. These instructions can be used to enforce storage ordering of I/O accesses. For example, we can use lwarx and stcwx. to implement an atomic compare-and-store function. Executing lwarx loads a word from a word-aligned location but also performs the following two actions atomically with the load. It creates a reservation that can be used by a subsequent stwcx. instruction. Note that a processor cannot have more than one reservation at a time. It notifies the processor's storage coherence mechanism that there is now a reservation for the specified memory location.
stwcx. stores a word to the specified word-aligned location. Its behavior depends on whether the location is the same as the one specified to lwarx to create a reservation. If the two locations are the same, stwcx. will perform the store only if there has been no other store to that location since the reservation's creationone or more other stores, if any, could be by another processor, cache operations, or through any other mechanism. If the location specified to stwcx. is different from the one used with lwarx, the store may or may not succeed, but the reservation will be lost. A reservation may be lost in various other scenarios, and stwcx. will fail in all such cases. Figure 328 shows an implementation of a compare-and-store function. The Mac OS X kernel includes a similar function. We will use this function in our next example to implement function rerouting. Figure 328. A hardware-based compare-and-store function for the 970FX // hw_cs.s // // hw_compare_and_store(u_int32_t old, // u_int32_t new, // u_int32_t *address, // u_int32_t *dummyaddress) // // Performs the following atomically: // // Compares old value to the one at address, and if they are equal, stores new // value, returning true (1). On store failure, returns false (0). dummyaddress // points to a valid, trashable u_int32_t location, which is written to for // canceling the reservation in case of a failure. .align 5 .globl _hw_compare_and_store _hw_compare_and_store: // Arguments: // r3 old // r4 new // r5 address // r6 dummyaddress // Save the old value to a free register. mr r7,r3 looptry: // Retrieve current value at address. // A reservation will also be created. lwarx r9,0,r5 // Set return value to true, hoping we will succeed. li r3,1 // Do old value and current value at address match? cmplw cr0,r9,r7 // No! Somebody changed the value at address. bne-- fail // Try to store the new value at address. stwcx. r4,0,r5 // Failed! Reservation was lost for some reason. // Try again. bne-- looptry // If we use hw_compare_and_store to patch/instrument code dynamically, // without stopping already running code, the first instruction in the // newly created code must be isync. isync will prevent the execution // of instructions following itself until all preceding instructions // have completed, discarding prefetched instructions. Thus, execution // will be consistent with the newly created code. An instruction cache // miss will occur when fetching our instruction, resulting in fetching // of the modified instruction from storage. isync // return blr fail: // We want to execute a stwcx. that specifies a dummy writable aligned // location. This will "clean up" (kill) the outstanding reservation. mr r3,r6 stwcx. r3,0,r3 // set return value to false. li r3,0 // return blr
|
3.5.3. Function Rerouting Our goal in this example is to intercept a function in a C program by substituting a new function in its place, with the ability to call the original function from the new function. Let us assume that there is a function function(int, char *), which we wish to replace with function_new(int, char *). The replacement must meet the following requirements. After replacement, when function() is called from anywhere within the program, function_new() is called instead. function_new() can use function(), perhaps because function_new() is meant to be a wrapper for the original function. The rerouting can be programmatically installed or removed. function_new() is a normal C function, with the only requirement being that it has the exact same prototype as function().
3.5.3.1. Instruction Patching Assume that function()'s implementation is the instruction sequence i0, i1, ..., iM, whereas function_new()'s implementation is the instruction sequence j0, j1, ..., jN, where M and N are some integers. A caller of function() executes i0 first because it is the first instruction of function(). If our goal is to arrange for all invocations of function() to actually call function_new(), we could overwrite i0 in memory with an unconditional branch instruction to j0, the first instruction of function_new(). Doing so would leave function() out of the picture entirely. Since we also wish to call function() from within function_new(), we cannot clobber function(). Moreover, we also wish to be able to turn off the rerouting and restore function() as it originally was. Rather than clobber i0, we save it somewhere in memory. Then, we allocate a memory region large enough to hold a few instructions and mark it executable. A convenient way to preallocate such a region is to declare a dummy function: one that takes the exact same number and type of arguments as function(). The dummy function will simply act as a stub; let us call it function_stub(). We copy i0 to the beginning of function_stub(). We craft an instructionan unconditional jump to i1that we write as the second instruction of function_stub(). We see that we need to craft two branch instructions: one from function() to function_new(), and another from function_stub() to function(). 3.5.3.2. Constructing Branch Instructions PowerPC unconditional branch instructions are self-contained in that they encode their target addresses within the instruction word itself. Recall from the previous example that it is possible to update a worda single instructionatomically on the 970FX using a compare-and-store (also called compare-and-update) function. It would be more complicated in general to overwrite multiple instructions. Therefore, we will use unconditional branches to implement rerouting. The overall concept is shown in Figure 329. Figure 329. Overview of function rerouting by instruction patching 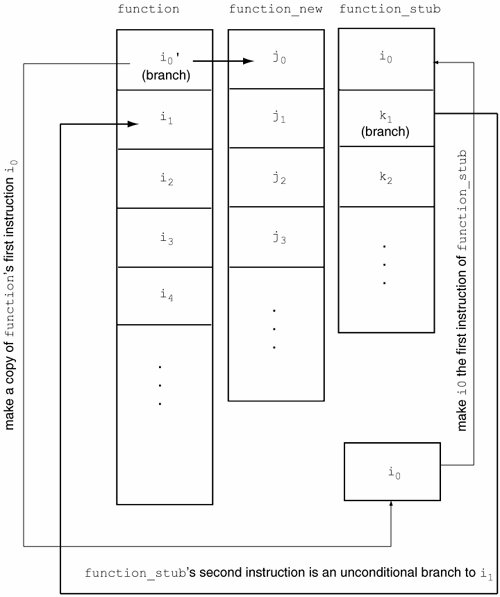
The encoding of an unconditional branch instruction on the PowerPC is shown in Figure 330. It has a 24-bit address field (LI). Since all instructions are 4 bytes long, the PowerPC refers to words instead of bytes when it comes to branch target addresses. Since a word is 4 bytes, the 24 bits of LI are as good as 26 bits for our purposes. Given a 26-bit-wide effective branch address, the branch's maximum reachability is 64MB total,[55] or 32MB in either direction. [55] 226 bytes.
Figure 330. Unconditional branch instruction on the PowerPC 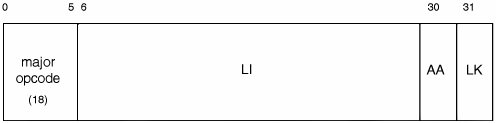
The Reach of a Branch The "reachability" of a branch is processor-specific. A jump on MIPS uses 6 bits for the operand field and 26 bits for the address field. The effective addressable jump distance is actually 28 bitsfour times morebecause MIPS, like PowerPC, refers to the number of words instead of the number of bytes. All instructions in MIPS are 4 bytes long; 28 bits give you 256MB (±128MB) of total leeway. SPARC uses a 22-bit signed integer for branch addresses, but again, it has two zero bits appended, effectively providing a 24-bit program counter relative jump reachability. This amounts to reachability of 16MB (±8MB). |
The AA field specifies whether the specified branch target address is absolute or relative to the current instruction (AA = 0 for relative, AA = 1 for absolute). If LK is 1, the effective address of the instruction following the branch instruction is placed in the LR. We do not wish to clobber the LR, so we are left with relative and absolute branches. We know now that to use a relative branch, the branch target must be within 32MB of the current instruction, but more importantly, we need to retrieve the address of the current instruction. Since the PowerPC does not have a program counter[56] register, we choose to use an unconditional branch with AA = 1 and LK = 0. However, this means the absolute address must be ±32MB relative to zero. In other words, function_new and function_stub must reside in virtual memory within the first 32MB or the last 32MB of the process's virtual address space! In a simple program such as ours, this condition is actually likely to be satisfied due to the way Mac OS X sets up process address spaces. Thus, in our example, we simply "hope" for function_new() (our own declared function) and function_stub() (a buffer allocated through the malloc() function) to have virtual addresses that are less than 32MB. This makes our "technique" eminently unsuitable for production use. However, there is almost certainly free memory available in the first or last 32MB of any process's address space. As we will see in Chapter 8, Mach allows you to allocate memory at specified virtual addresses, so the technique can also be improved. [56] The conceptual Instruction Address Register (IAR) is not directly accessible without involving the LR.
Figure 331 shows the code for the function-rerouting demo program. Note that the program is 32-bit onlyit will behave incorrectly when compiled for the 64-bit architecture. Figure 331. Implementation of function rerouting by instruction patching // frr.c #include <stdio.h> #include <fcntl.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/types.h> #include <sys/mman.h> // Constant on the PowerPC #define BYTES_PER_INSTRUCTION 4 // Branch instruction's major opcode #define BRANCH_MOPCODE 0x12 // Large enough size for a function stub #define DEFAULT_STUBSZ 128 // Atomic update function // int hw_compare_and_store(u_int32_t old, u_int32_t new, u_int32_t *address, u_int32_t *dummy_address); // Structure corresponding to a branch instruction // typedef struct branch_s { u_int32_t OP: 6; // bits 0 - 5, primary opcode u_int32_t LI: 24; // bits 6 - 29, LI u_int32_t AA: 1; // bit 30, absolute address u_int32_t LK: 1; // bit 31, link or not } branch_t; // Each instance of rerouting has the following data structure associated with // it. A pointer to a frr_data_t is returned by the "install" function. The // "remove" function takes the same pointer as argument. // typedef struct frr_data_s { void *f_orig; // "original" function void *f_new; // user-provided "new" function void *f_stub; // stub to call "original" inside "new" char f_bytes[BYTES_PER_INSTRUCTION]; // bytes from f_orig } frr_data_t; // Given an "original" function and a "new" function, frr_install() reroutes // so that anybody calling "original" will actually be calling "new". Inside // "new", it is possible to call "original" through a stub. // frr_data_t * frr_install(void *original, void *new) { int ret = -1; branch_t branch; frr_data_t *FRR = (frr_data_t *)0; u_int32_t target_address, dummy_address; // Check new's address if ((u_int32_t)new >> 25) { fprintf(stderr, "This demo is out of luck. \"new\" too far.\n"); goto ERROR; } else printf(" FRR: \"new\" is at address %#x.\n", (u_int32_t)new); // Allocate space for FRR metadata FRR = (frr_data_t *)malloc(sizeof(frr_data_t)); if (!FRR) return FRR; FRR->f_orig = original; FRR->f_new = new; // Allocate space for the stub to call the original function FRR->f_stub = (char *)malloc(DEFAULT_STUBSZ); if (!FRR->f_stub) { free(FRR); FRR = (frr_data_t *)0; return FRR; } // Prepare to write to the first 4 bytes of "original" ret = mprotect(FRR->f_orig, 4, PROT_READ|PROT_WRITE|PROT_EXEC); if (ret != 0) goto ERROR; // Prepare to populate the stub and make it executable ret = mprotect(FRR->f_stub, DEFAULT_STUBSZ, PROT_READ|PROT_WRITE|PROT_EXEC); if (ret != 0) goto ERROR; memcpy(FRR->f_bytes, (char *)FRR->f_orig, BYTES_PER_INSTRUCTION); // Unconditional branch (relative) branch.OP = BRANCH_MOPCODE; branch.AA = 1; branch.LK = 0; // Create unconditional branch from "stub" to "original" target_address = (u_int32_t)(FRR->f_orig + 4) >> 2; if (target_address >> 25) { fprintf(stderr, "This demo is out of luck. Target address too far.\n"); goto ERROR; } else printf(" FRR: target_address for stub -> original is %#x.\n", target_address); branch.LI = target_address; memcpy((char *)FRR->f_stub, (char *)FRR->f_bytes, BYTES_PER_INSTRUCTION); memcpy((char *)FRR->f_stub + BYTES_PER_INSTRUCTION, (char *)&branch, 4); // Create unconditional branch from "original" to "new" target_address = (u_int32_t)FRR->f_new >> 2; if (target_address >> 25) { fprintf(stderr, "This demo is out of luck. Target address too far.\n"); goto ERROR; } else printf(" FRR: target_address for original -> new is %#x.\n", target_address); branch.LI = target_address; ret = hw_compare_and_store(*((u_int32_t *)FRR->f_orig), *((u_int32_t *)&branch), (u_int32_t *)FRR->f_orig, &dummy_address); if (ret != 1) { fprintf(stderr, "Atomic store failed.\n"); goto ERROR; } else printf(" FRR: Atomically updated instruction.\n"); return FRR; ERROR: if (FRR && FRR->f_stub) free(FRR->f_stub); if (FRR) free(FRR); return FRR; } int frr_remove(frr_data_t *FRR) { int ret; u_int32_t dummy_address; if (!FRR) return 0; ret = mprotect(FRR->f_orig, 4, PROT_READ|PROT_WRITE|PROT_EXEC); if (ret != 0) return -1; ret = hw_compare_and_store(*((u_int32_t *)FRR->f_orig), *((u_int32_t *)FRR->f_bytes), (u_int32_t *)FRR->f_orig, &dummy_address); if (FRR && FRR->f_stub) free(FRR->f_stub); if (FRR) free(FRR); FRR = (frr_data_t *)0; return 0; } int function(int i, char *s) { int ret; char *m = s; if (!s) m = "(null)"; printf(" CALLED: function(%d, %s).\n", i, m); ret = i + 1; printf(" RETURN: %d = function(%d, %s).\n", ret, i, m); return ret; } int (* function_stub)(int, char *); int function_new(int i, char *s) { int ret = -1; char *m = s; if (!s) m = "(null)"; printf(" CALLED: function_new(%d, %s).\n", i, m); if (function_stub) { printf("CALLING: function_new() --> function_stub().\n"); ret = function_stub(i, s); } else { printf("function_new(): function_stub missing.\n"); } printf(" RETURN: %d = function_new(%d, %s).\n", ret, i, m); return ret; } int main(int argc, char **argv) { int ret; int arg_i = 2; char *arg_s = "Hello, World!"; frr_data_t *FRR; function_stub = (int(*)(int, char *))0; printf("[Clean State]\n"); printf("CALLING: main() --> function().\n"); ret = function(arg_i, arg_s); printf("\n[Installing Rerouting]\n"); printf("Maximum branch target address is %#x (32MB).\n", (1 << 25)); FRR = frr_install(function, function_new); if (FRR) function_stub = FRR->f_stub; else { fprintf(stderr, "main(): frr_install failed.\n"); return 1; } printf("\n[Rerouting installed]\n"); printf("CALLING: main() --> function().\n"); ret = function(arg_i, arg_s); ret = frr_remove(FRR); if (ret != 0) { fprintf(stderr, "main(): frr_remove failed.\n"); return 1; } printf("\n[Rerouting removed]\n"); printf("CALLING: main() --> function().\n"); ret = function(arg_i, arg_s); return 0; }
|
Figure 332 shows a sample run of the function-rerouting demonstration program. Figure 332. Function rerouting in action $ gcc -Wall -o frr frr.c $ ./frr [Clean State] CALLING: main() --> function(). CALLED: function(2, Hello, World!). RETURN: 3 = function(2, Hello, World!). [Installing Rerouting] Maximum branch target address is 0x2000000 (32MB). FRR: "new" is at address 0x272c. FRR: target_address for stub -> original is 0x9a6. FRR: target_address for original -> new is 0x9cb. FRR: Atomically updated instruction. [Rerouting installed] CALLING: main() --> function(). CALLED: function_new(2, Hello, World!). CALLING: function_new() --> function_stub(). CALLED: function(2, Hello, World!). RETURN: 3 = function(2, Hello, World!). RETURN: 3 = function_new(2, Hello, World!). [Rerouting removed] CALLING: main() --> function(). CALLED: function(2, Hello, World!). RETURN: 3 = function(2, Hello, World!).
|
3.5.4. Cycle-Accurate Simulation of the 970FX Apple's CHUD Tools package includes the amber and simg5 command-line programs that were briefly mentioned in Chapter 2. amber is a tool for tracing all threads in a process, recording every instruction and data access to a trace file. simg5[57] is a cycle-accurate core simulator for the 970/970FX. With these tools, it is possible to analyze the execution of a program at the processor-cycle level. You can see how instructions are broken down into iops, how the iops are grouped, how the groups are dispatched, and so on. In this example, we will use amber and simg5 to analyze a simple program. [57] simg5 was developed by IBM.
The first step is to use amber to generate a trace of a program's execution. amber supports a few trace file formats. We will use the TT6E format with simg5. Tracing the execution of an entire applicationeven a trivial programwill result in the execution of an extremely large number of instructions. Execution of the "empty" C program in Figure 333 causes over 90,000 instructions to be traced. This is so because although the program does not have any programmer-provided code (besides the empty function body), it still contains the runtime environment's startup and teardown routines. Figure 333. Tracing an "empty" C program using amber $ cat null.c main() { } $ gcc -o null null.c $ amber ./null ... Session Instructions Traced: 91353 Session Trace Time: 0.46 sec [0.20 million inst/sec] ...
|
Typically, you would not be interested in analyzing the execution of the language runtime environment. In fact, even within your own code, you may want to analyze only small portions at a time. It becomes impractical to deal with a large numbersay, more than a few thousandof instructions using these tools. When used with the i or I arguments, amber can toggle tracing for an application upon encountering a privileged instruction. A readily usable example of such an instruction is one that accesses an OEA register from user space. Thus, you can instrument your code by surrounding the portion of interest with two such illegal instructions. The first occurrence will cause amber to turn tracing on, and the second will cause tracing to stop. Figure 334 shows the program we will trace with amber. Figure 334. A C program with instructions that are illegal in user space // traceme.c #include <stdlib.h> #if defined(__GNUC__) #include <ppc_intrinsics.h> #endif int main(void) { int i, a = 0; // supervisor-level instruction as a trigger // start tracing (void)__mfspr(1023); for (i = 0; i < 16; i++) { a += 3 * i; } // supervisor-level instruction as a trigger // stop tracing (void)__mfspr(1023); exit(0); }
|
We trace the program in Figure 334 using amber with the I option, which directs amber to trace only the instrumented thread. The i option would cause all threads in the target process to be traced. As shown in Figure 335, the executable will not run stand-alone because of the presence of illegal instructions in the machine code. Figure 335. Tracing program execution with amber $ gcc -S traceme.c # GCC 4.x $ gcc -o traceme traceme.c $ ./traceme zsh: illegal hardware instruction ./traceme $ amber -I ./traceme ... * Targeting process 'traceme' [1570] * Recording TT6E trace * Instrumented executable - tracing will start/stop for thread automatically * Ctrl-Esc to quit * Tracing session #1 started * Session Instructions Traced: 214 Session Traced Time: 0.00 sec [0.09 million inst/sec] * Tracing session #1 stopped * * Exiting... *
|
amber creates a subdirectory called TRace_xxx in the current directory, where xxx is a three-digit numerical string: 001 if this is the first trace in the directory. The TRace_xxx directory contains further subdirectories, one per thread in your program, containing TT6E traces of the program's threads. A trace provides information such as what instructions were issued, what order they were issued in, what were the load and store addresses, and so on. Our program has only one thread, so the subdirectory is called thread_001.tt6e. As shown in Figure 335, amber reports that 214 instructions were traced. Let us account for these instructions by examining the generated assembly traceme.s, whose partial contents (annotated) are shown in Figure 336. Note that we are interested only in the portion between the pair of mfspr instructions. However, it is noteworthy that the instruction immediately following the first mfspr instruction is not included in amber's trace. Figure 336. Accounting for instructions traced by amber ; traceme.s (compiled with GCC 4.x) mfspr r0, 1023  stw r0,60(r30) ; not traced ; instructions of interest begin here li r0,0 stw r0,68(r30) b L2 L3: lwz r2,68(r30) ; i[n] mr r0,r2 ; i[n + 1] slwi r0,r0,1 ; i[n + 2] add r2,r0,r2 ; i[n + 3] lwz r0,64(r30) ; i[n + 4] add r0,r0,r2 ; i[n + 5] stw r0,64(r30) ; i[n + 6] lwz r2,68(r30) ; i[n + 7] addi r0,r2,1 ; i[n + 8] stw r0,68(r30) ; i[n + 9] L2: lwz r0,68(r30) ; i[n + 10] cmpwi cr7,r0,15 ; i[n + 11] ble cr7,L3 ; i[n + 12] mfspr r0, 1023 stw r0,60(r30) ; not traced ; instructions of interest begin here li r0,0 stw r0,68(r30) b L2 L3: lwz r2,68(r30) ; i[n] mr r0,r2 ; i[n + 1] slwi r0,r0,1 ; i[n + 2] add r2,r0,r2 ; i[n + 3] lwz r0,64(r30) ; i[n + 4] add r0,r0,r2 ; i[n + 5] stw r0,64(r30) ; i[n + 6] lwz r2,68(r30) ; i[n + 7] addi r0,r2,1 ; i[n + 8] stw r0,68(r30) ; i[n + 9] L2: lwz r0,68(r30) ; i[n + 10] cmpwi cr7,r0,15 ; i[n + 11] ble cr7,L3 ; i[n + 12] mfspr r0, 1023
|
Each of the 3 instructions before the L3 loop label are executed only once, whereas the rest of the instructions that lie between the L3 loop label and the second mfspr instruction are executed during one or all iterations of the loop. Instructions i[n] tHRough i[n + 9] (10 instructions) are executed exactly 16 times, as the C variable i is incremented. The assembly implementation of the loop begins by jumping to the L2 label and checks whether i has attained the value 16, in which case the loop terminates. Since i is initially zero, instructions i[n + 10] through i[n + 12] (3 instructions) will be executed exactly 17 times. Thus, the total number of instructions executed can be calculated as follows: 3 + (10 x 16) + (3 x 17) = 214 Let us now run simg5 on this trace. simg5 allows you to change certain characteristics of the simulated processor, for example, by making the L1 I-cache, the L1 D-cache, the TLBs, or the L2 cache infinite. There also exists a Java viewer for viewing simg5's output. simg5 can automatically run the viewer upon finishing if the auto_load option is specified. $ simg5 trace_001/thread_001.tt6e 214 1 1 test_run1 -p 1 -b 1 -e 214 -auto_load ...
Figure 337 shows simg5's output as displayed by the Java viewer. The left side of the screen contains a cycle-by-cycle sequence of processor events. These are denoted by labels, examples of which are shown in Table 313. Figure 337. simg5 output 
Table 313. Processor Event LabelsLabel | Event | Notes |
|---|
FVB | Fetch | Instruction fetched into the instruction buffer | D | Decode | Decode group formed | M | Dispatch | Dispatch group dispatched | su | Issue | Instruction issued | E | Execute | Instruction executing | f | Finish | Instruction finished execution | C | Completion | Instruction group completed |
In the simg5 output, we can see the breaking down of architected instructions into iops. For example, the second instruction of interest in Figure 336 has two corresponding iops. |