Mission-Critical Considerations
|
Your ISA Server installation is likely to be a cornerstone of your Internet access scheme. Some businesses live or die by their ability to connect to and work via the Internet. Even a few minutes of downtime can lead to thousands or even tens of thousands of lost dollars. Therefore, before implementing your plan, if Internet access is a mission-critical service for any part of your organization, you need to consider fault tolerance.
Four key areas of fault tolerance and mission-critical availability are:
-
Hard disk fault tolerance
-
Network fault tolerance
-
Server fault tolerance
-
Bastion host configuration
Hard Disk Fault Tolerance
When considering disk fault-tolerance schemes, you need to pin down what it is that you want to accomplish. Right out of the box, Windows 2000 supports two forms of software-based disk fault tolerance:
-
Mirrored volumes (mirror sets)
-
RAID 5 volumes (stripe sets with parity)
Although Windows 2000 does include these methods of disk fault tolerance without requiring any added software or hardware, you might find that your situation requires a more high-performance solution. If you are implementing ISA Server in a large enterprise environment, you will find that the resource demands of software fault tolerance drain server resources to an unacceptable degree.
For high-load ISA Server environments, the better solution is hardware-based Redundant Array of Independent Disks (RAID). In hardware-based RAID, the fault-tolerance mechanisms are built right into the hard disk controller and require no appreciable processor or memory overhead. We cover both software and hardware RAID implementations in this chapter.
| Note | Before you can implement mirrored volumes or RAID 5 volumes on a Windows 2000 server, you must convert the disks on which the volumes will reside to dynamic disks. |
Mirrored Volumes (Mirror Sets)
Mirrored volumes provide a method to allow all data written to one volume to be automatically copied to a second volume. Mirrored-volume configurations allow for real-time fault tolerance for the data stored on a mirrored volume.
The best use of the mirrored-volume configuration is found when the boot and system files are on the primary member of the mirrored volume and then mirrored on a secondary member of the mirror set, with the secondary volume located on a different disk and controller. This configuration, in which the secondary member of the mirrored volume is located on a different disk and controller than the primary member, is known as disk duplexing. Figure 22.6 characterizes this type of configuration.
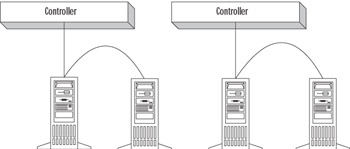
Figure 22.6: Mirrored Volumes Configured in a Duplex Arrangement
| Note | To the operating system, mirrored disks (both disks on the same controller) and duplexed disks (on different controllers) appear the same, and both are shown as mirrored volumes in the Windows 2000 disk management console. Duplexing is a hardware differentiation. Duplexing provides both fault-tolerance benefits and superior performance, since disk reads and writes can take place simultaneously across different controllers. |
The primary member of the mirror set is the "live" part of the mirror set—the one that is actually being used by the user and operating system. However, everything that is copied or changed on the primary member is also updated on the secondary member of the mirror set. If the primary member should fail, the system will automatically fail-over and the secondary member of the mirror set will take over the duties once held by the primary member. There is no negative effect on performance. In fact, write performance should improve slightly because changes will not have to be written twice.
When either member of the mirror set fails, there will be no discernable change in terms of server availability, and users will be totally unaware that any changes have taken place. However, you should configure some type of notification mechanism so that an administrator is informed when a member of the mirror set fails so that it can be repaired quickly.
| Warning | Once a single member of the mirror set fails, there is no longer any fault tolerance until a new disk is configured as a secondary disk. Note that regardless of which disk fails, the remaining disk becomes the primary member and the new disk becomes the secondary member. |
RAID 5 Volumes (Stripe Sets with Parity)
The other "out of the box" RAID solution that you can consider using in your ISA Server solution is the RAID 5 volume. RAID 5 volumes were known in the Windows NT world as stripe sets with parity. Because parity information is stored in the RAID 5 volume, you have fault tolerance in the event of a single disk failure, regardless of how many disks are included in the RAID 5 volume. The data on the failed disk can be regenerated from the parity information stored on the other disks in the set. You must have a minimum of three physical disks (and up to 32 disks) to create a RAID 5 volume.
| Warning | Unfortunately, a RAID 5 volume can tolerate the failure of only one disk. If two or more disks in a RAID 5 volume should fail either sequentially or simultaneously, the data cannot be regenerated and you must restore the information stored on the array from backup. |
The major advantage of a RAID 5 volume over a mirrored volume is speed. Striped volumes have faster read/write performance than mirrored volumes. However, one disadvantage of the RAID 5 volume is that you cannot place the system or boot files on such a volume. This is a limitation of the software implementation of RAID 5, because the operating system must be able to load and access the fault-tolerance disk driver (ftdisk.sys) before it can mount the volume. Since you must be able to access the system files to load the disk drivers, you cannot include the system files on a RAID 5 volume.
The primary disadvantage of a RAID 5 volume compared with a RAID 1 volume is a higher cost of entry. You can create a RAID 1 volume with a single pair of disks, whereas the RAID 5 volume requires at least three physical disks. This could be a factor for very small shops that are highly cost constrained.
However, RAID 5 has a couple of advantages over RAID 1 in that the total cost of a RAID 5 solution per megabyte is lower when more disks are added to the array. The amount of "unusable" disk space on a mirror set equals 50 percent of the total disk space dedicated to the set, whereas the space required for storing parity information on a RAID 5 array equals 1 number_of_disks. So, if you have a 10-disk array, you are only "wasting" one-tenth of your disk space for fault-tolerance information.
The second advantage of the RAID 5 array is the much larger volume size that can be created. The largest usable volume size on a RAID 1 array is equal to the size of one of the disks in the array. However, the size of a RAID 5 array is the sum of all the disks (up to 32) minus the fraction used for parity information.
| Note | Initial hardware cost for implementing a mirrored volume is less to implement than implementing a RAID 5 volume. This is because you must buy only two disks for a mirrored volume, but you must have a minimum of three disks for RAID 5. However, the cost per megabyte of data is less for a RAID 5 configuration, and that cost decreases as the number of disks in the RAID array increases. For example, if you have three physical disks in the RAID 5 set, the equivalent of one physical disk (or one-third of the total disk space) is used for parity information, whereas the rest (two-thirds of the disk space) is available for data. If you increase that to 10 physical disks, only one-tenth of the total disk space must be used for storing the parity information, and nine-tenths is available for storing your data. Thus, over the long term, a RAID 5 volume is usually better in terms of pure cost effectiveness. You will want to weigh other factors, such as ease of recovery and need to provide fault tolerance for system and boot partitions, when selecting the best fault-tolerance method for your situation. Figure 22.7 characterizes a RAID 5 configuration. |
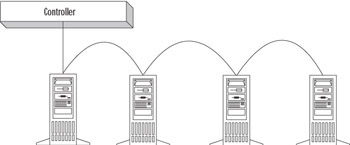
Figure 22.7: A RAID 5 Volume
Optimizing a Software RAID Configuration
In your ISA Server configuration, you should include log files, cache files, and reports on the RAID 5 array. Doing so will significantly speed ISA server performance and allow for fault tolerance for these important files. Keep in mind that your array is fault tolerant only when all disks are in working order.
If a single disk in a RAID 5 fails, your array is no longer fault tolerant, and you need to replace the disk as soon as possible—not only for fault tolerance reasons, but also because the process of reconstructing the data from the parity information will slow performance significantly.
If you are running the Web proxy service's Web-caching feature, you want to be able to ensure the fastest read performance possible. This is because the Web cache is typically implemented to improve client-perceived performance. Write time to the cache isn't quite as important, since the Web-caching feature will store URLs in RAM for a certain period of time before writing them to cache. However, you do want to be able to retrieve cached Web objects as quickly as possible.
RAID 5, because it is striped, has better read performance than RAID 0; therefore, you should consider placing the cache files on a RAID 5 array if you require fault tolerance for your cache. In a production environment that is strapped for Internet bandwidth, you might consider this option. However, the Web cache itself is not generally a mission-critical component, and you might want to sacrifice fault tolerance for superior read performance. In this case, you should use the software-based RAID 0, or striped volumes. Although they do not provide fault tolerance, they do provide the best read performance of any RAID type.
The log files present a different set of requirements. If you plan to do extensive logging (which you would consider in a very secure environment), you need to place the log files on a volume that supports optimal write performance. Log files are read only occasionally, but they are written to constantly. Both RAID 1 and RAID 5 suffer from write latency because, in a RAID 1 configuration, the data must be written twice, and in a RAID 5 configuration, the parity information must be calculated and then written in addition to the data.
Unlike the situation with the Web cache, the log files are mission critical and do require placement on a fault-tolerant disk set. Given the choice between RAID 1 and 5, your best option is the mirror set.
Reports are rarely written and only occasionally accessed. Therefore, read/write performance is not a primary issue. However, like the log files, you do not want to lose these or you will have to recreate them. You can place these reports on either a RAID 1 or 5 volume.
Hardware-Based RAID
Although we have discussed fault-tolerant disk arrays in the context of the software-based schemes provided with Windows 2000 out of the box, you can also implement fault tolerance via hardware RAID controllers. Almost all organizations that require the highest level of fault tolerance and performance use hardware-based RAID.
There are many advantages to using hardware RAID controllers. These controllers allow you to mirror the boot and system partitions, because they are not dependent on the operating system initializing before fault-tolerance sets can be established. Furthermore, the hardware solutions are significantly faster on software-based RAID. A hardware implementation of RAID appears to the operating system as though the array were a single physical disk.
One type of hardware-based RAID that has gained widespread popularity is known either as RAID 10 or RAID 0+1. This RAID implementation creates a striped volume and then mirrors the striped volume to provide fault tolerance. This process gives you the best of both worlds: the performance of a striped volume and the fault tolerance of a mirror set.
For example, you could configure a three-disk set as part of a RAID 0 array. This set would be mirrored onto another three disks, so such an array would require a total of six disks. If any member of the RAID 0 array should fail, a corresponding disk from the mirror set would be brought into service. However, at this point you no longer have fault tolerance and you need to replace the disk as soon as possible.
More sophisticated (and expensive) RAID implementations allow you to keep "hot spares" online so that, in the event of a disk failure, a hot spare is introduced to the array automatically. Again, you have fault tolerance as long as you have one hot spare available. When there are no more spares, you need to add new disks.
Network Fault Tolerance
When implementing ISA Server, you must consider the level of availability you require for both your internal and external network interfaces. Your server configurations can be designed to be fully fault tolerant, but if your single interface to the Internet becomes unavailable, all your machine fault tolerance is moot.
The type of fault-tolerant configuration you design for your external interfaces depends on the type of interface and the arrangements you have with your ISP. For example, if you have a single ISDN connection via a single account with your ISP, there's not much you can do with such a configuration, as is, to allow for any level of fail-over.
The ideal network fault-tolerance solution for your external interface is to have multiple ISA Servers participating in an enterprise array on the edge of your network. You would then configure routing rules so that, in the event of an interface failure, the request can first be resolved within the array and then forwarded to another server within the array if it needs to be sent to the Internet for retrieval.
| Note | The ability to configure ISA Server with routing rules in the event of an external interface failure is a powerful fault-tolerance mechanism built into ISA Server. However, this mechanism requires you to have made provisions for multiple connections to the Internet, which require purchasing and maintaining multiple access accounts. |
Large organizations can more easily absorb the costs of multiple high-speed dedicated connections. If you are working in a smaller networking environment that is more sensitive to cost, you might consider an analog backup line in the event of failure of another low-cost solution such as cable, dial-up ISDN, or DSL.
Network load balancing, another important issue related to fault tolerance (as well as performance), is a way of dividing up the network load. This prevents one system from getting overused and another from getting underused.
Server Fault Tolerance
There are several ways to ensure fault tolerance for ISA servers in the event of a server crash or the necessity of taking a server offline for maintenance or upgrade. The best way to provide for server fault tolerance is to take advantage of arrays of ISA servers when you deploy the Enterprise Edition. An ISA Server array is a collection of ISA servers that share the same configuration information and Web cache content. An array provides a high degree of fault tolerance; if a single server becomes unavailable, the other servers can take over to service requests for the downed ISA server.
| Note | All members of an array share the same Web cache policies and can access each other's cached Web content. However, the contents of the cache do not mirror in any way the contents of other servers in the array. In addition, the cache location settings must be set on the individual servers. The cache location is not part of the cache configuration shared by the array. However, this setting doesn't happen automatically. If your clients are configured to access a certain ISA server and that server becomes unavailable, the client will not necessarily be able to access the next server in the array. In order to provide a measure of fault tolerance for client access, you must devise some scheme that will allow the clients to fail-over to another ISA server. |
DNS Round Robin
One way you can accomplish server fault tolerance is to configure a DNS round robin on your network. In your DNS, you assign the same host name to the IP addresses of your respective ISA servers. That is, your ISA servers will each have the same fully qualified domain name (FQDN).
If you are using Windows 2000 DNS servers, DNS round robin is enabled by default. However, you should never take it for granted that the settings on a particular server are at their defaults. To assess whether DNS round robin is available on your Windows 2000 DNS server:
-
Right-click the server name in the left pane of the DNS console.
-
Click Properties.
-
Click the Advanced tab.
You will see the screen that appears in Figure 22.8. Make sure that Enable round robin is checked if you want to take advantage of the DNS round-robin feature.
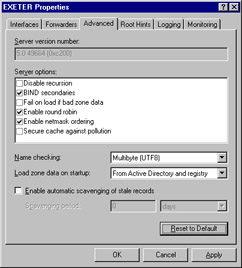
Figure 22.8: Configuring DNS Round Robin on a Windows 2000 DNS Server
With DNS round robin enabled, when a network client queries DNS, it receives the IP address of one of the ISA servers. If that server is not available, the network client receives an error message. When a subsequent request is made, the ISA client receives another IP address after the expiration of the time-out period of the DNS response it received earlier. Since these addresses are assigned randomly, there's a good chance that it will receive the IP address of a different ISA server (one that is still up and running).
For example, suppose we create three DNS round-robin entries for the host name isaserver in the tacteam.net domain. The entries would look something like this:
isaserver.tacteam.net A 222.222.222.222 isaserver.tacteam.net A 222.222.222.223 isaserver.tacteam.net A 222.222.222.224
We also set the time-out for these records so that the DNS clients wash the entries from their DNS caches after one minute. If a client makes a request for isaserver.tacteam.net and receives the IP address 222.222.222.222 and that machine is down, and then the client makes another request five seconds later, the IP address will be retrieved from the DNS cache and the DNS server will not be queried again. However, if the request is made 90 seconds later, the entry will have timed out of the cache, and the DNS server will be queried again to resolve the name isaserver.tacteam.net.
However, DNS round robin has some notable disadvantages when it comes to fault tolerance. Because the rotation of the IP addresses sent to DNS clients is random, there's the chance that the DNS client will receive the same IP address it got before and therefore will have to wait for the Time To Live (TTL) on that entry to expire before attempting to get another IP address.
| Warning | If you check Figure 22.8 again, you'll notice another option, Enable netmask ordering. When this option is enabled, local subnet priority has precedence over random round-robin assignments. Local subnet prioritization allows the DNS server to compare address records with the source IP address of the DNS query. If a host record in the DNS is located on the same or similar network ID as the DNS client, that record will always be delivered to the client and the client will not receive a random record. This could be an issue if you have array members on different network IDs and clients on the same networks as the array members. If all array members have the same network ID, DNS round robin will be applied to hosts on the same network as the array members. |
You can help minimize this problem by configuring very short TTLs on your round-robin entries in the DNS. However, doing so reduces the efficacy of the client-side DNS cache and could have a negative impact on network performance on a loaded network.
Another thing that complicates this scheme is that the Windows 2000 DNS clients are configured with the ability to "negatively cache" failed DNS requests. By default, the negative cache entry stays in effect for five minutes. This means that if an ISA client receives the IP address of the downed ISA server, it will remain a negative cache entry for five minutes, and the client will not attempt to query the DNS server again until the negative cache entry has timed out.
You can change the time-out period for the negative cache entries by configuring the Registry. The key can be located at HKLM\System\CurrentControlSet\Services\Dnscache\Parameters. The value to configure is the NegativeCacheTime, which, by default, is configured for 300 seconds.
Bastion Host Configuration
A bastion host is a computer that has an interface with an untrusted network. In the context of ISA Server, that untrusted network is typically the Internet. The bastion host can lie with an interface directly connected to the Internet, or it can be placed on a perimeter network behind a router but in front of the internal network.
Because of the central role the bastion host computer plays in your Internet access scheme, it is important that the operating system is hardened and made as stable as possible. System hardening can be performed via the ISA Server Security Configuration Wizard. This wizard applies security settings derived from a set of security templates that are installed with Windows 2000 Server family products.
In addition to applying strict security settings to the file system, Registry, and applications, you need to review the services running on the bastion host computer. Each service running on your bastion host provides a possible target for an attacker to exploit. Common operating system and network services that are installed by default can provide avenues of opportunity for attackers. Some of these services include:
-
The Browser Service
-
The IIS Admin Service
-
The Indexing Service
-
The Remote Registry Service
-
The SMTP Service
Many more potentially hazardous services are started by default on Windows 2000 Server family products.
|
EAN: 2147483647
Pages: 240