Section 6.4. Eliminating Collection Error
| |
6.4 Eliminating Collection Error
As you have seen in Chapter 3, it is of paramount importance to collect SQL trace data precisely for a desired time scope. Especially for short-duration user response time diagnosis projects, it is critical to activate and deactivate SQL trace at exactly the right times. When trace for a session is activated or deactivated by a third-party session, time scope violations can occur either at the head or the tail of the trace file. The remainder of this chapter shows you how to determine how and why data collection errors occur and how to get the maximum possible information from your trace data.
6.4.1 Time Scope Errors at Trace Activation
When a session activates its own SQL trace, the first thing you'll find in the session's trace file is information pertaining to the ALTER SESSION SET EVENTS command. However, when a session's trace attribute is set by another session (with, for example, DBMS_SYSTEM.SET_EV or DBMS_SUPPORT.START_TRACE_IN_SESSION) , it's more difficult to predict what the first event printed into the trace file will be.
6.4.1.1 Missing wait event data at trace activation
If tracing is activated in the midst of a wait event that occurs between database calls, then there can be missing data at the head of the trace file. For example, consider the sequence of actions depicted in Figure 6-6. In a test, I created two SQL*Plus sessions: one identified as 7.10583 (the SID and SERIAL# for the session), and another called the "second" session. In the second session, I executed the following PL/SQL block, supplying the values 7 and 10583 in response to the prompts:
set serveroutput on undef 1 undef 2 declare t varchar(20); begin dbms_system.set_ev(&1,&2,10046,8,''); select to_char(sysdate, 'hh24:mi:ss') into t from v$timer; dbms_output.put_line('time='t); end; / Executing this block activated tracing for session 7.10583 and displayed that my trace activation time was 12:31:11. Therefore, I know that this time marked the beginning of my requested data collection interval.
Figure 6-6. Although the SET_EV call was made in the second session at 12:31:11, the first entry into the session 7.10583 trace file didn't occur until 12:31:47.330, leaving an unaccounted-for duration of roughly 36 seconds
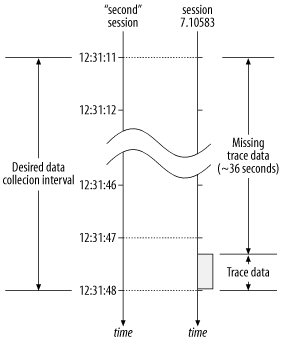
Within session 7.10583, I waited a few seconds and then executed a simple query for the current system time. The query result was 12:31:47. Then I exited session 7.10583. The trace file for the session is shown in Example 6-7. Notice that the trace file accounts for actions taking place between 12:31:47.330 and approximately 12:31:47.983 (I computed this second figure by walking the clock in the trace data), but it contains no data whatsoever for the approximately 36 seconds that elapsed between 12:31:11 and 12:31:47.330.
Example 6-7. This trace file was created by a query for the current system time. The query result was 12:31:47, which matches the first timestamp (highlighted) in the trace file
/u01/oradata/admin/V901/udump/ora_31262.trc Oracle9i Enterprise Edition release 9.0.1.0.0 - Production With the Partitioning option JServer release 9.0.1.0.0 - Production ORACLE_HOME = /u01/oradata/app/9.0.1 System name: Linux Node name: research Release: 2.4.4-4GB Version: #1 Fri May 18 14:11:12 GMT 2001 Machine: i686 Instance name: V901 Redo thread mounted by this instance: 1 Oracle process number: 8 Unix process pid: 31262, image: oracle@research (TNS V1-V3) *** 2003-01-28 12:31:47.330 *** SESSION ID:(7.10583) 2003-01-28 12:31:47.330 APPNAME mod='SQL*Plus' mh=3669949024 act='' ah=4029777240 = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #1 len=47 dep=0 uid=5 oct=3 lid=5 tim=1043778707330593 hv=2972477985 ad='51302734' select to_char(sysdate, 'hh24:mi:ss') from dual END OF STMT PARSE #1:c=10000,e=1510,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=4,tim=1043778707330128 EXEC #1:c=0,e=97,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=4,tim=1043778707330810 WAIT #1: nam='SQL*Net message to client' ela= 5 p1=1650815232 p2=1 p3=0 FETCH #1:c=0,e=156,p=0,cr=1,cu=2,mis=0,r=1,dep=0,og=4,tim=1043778707331088 WAIT #1: nam='SQL*Net message from client' ela= 452 p1=1650815232 p2=1 p3=0 FETCH #1:c=0,e=2,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=0,tim=1043778707331819 WAIT #1: nam='SQL*Net message to client' ela= 4 p1=1650815232 p2=1 p3=0 WAIT #1: nam='SQL*Net message from client' ela= 650421 p1=1650815232 p2=1 p3=0 STAT #1 id=1 cnt=1 pid=0 pos=0 obj=221 op='TABLE ACCESS FULL DUAL ' XCTEND rlbk=0, rd_only=1
Because I had complete control over session 7.10583 for the duration of its existence, I know that the 36 seconds that are missing from the trace data should have been attributed to the kernel event called SQL*Net message from client . However, if I had not known this, there would have been no accurate way to account for the missing time. This is why the Sparky data collector (http://www.hotsos.com) queries V$SESSION_WAIT at trace activation (and deactivation ). Had I executed the following query at the time of trace activation, I would have known which wait event was in-process at the time of trace activation (12:31:11):
select event from v$session_wait where sid=7 and state='WAITING'
6.4.1.2 Missing database call data at trace activation
A more difficult problem occurs when a session's tracing attribute is activated in the midst of a database call. For example, I activated the tracing attribute for session 8.1665 in the midst of a long-running fetch, resulting in the trace data shown in Example 6-8. The trace file is disturbing if you study it. In the over 87,700 lines of trace data that I've not shown here, there are thousands of centiseconds' worth of wait event time attributable to cursor #1 (the sum of the ela field values on WAIT #1 lines). However, the very first database call printed to the trace file is the UNMAP database call that is highlighted in Example 6-8. Notice that its total elapsed duration is only 3 centiseconds ( e=3 ). We have thousands of centiseconds' worth of wait event time motivated by some database call, but the database call that accounts for all that time doesn't appear in the trace data!
Example 6-8. The trace file produced by activating trace in the midst of a long-running fetch call. The fetch call in-process when tracing was activated is completely absent from the trace data
Dump file C:\oracle\admin\ora817\udump\ORA02124.TRC Tue Jan 28 02:13:21 2003 ORACLE V8.1.7.0.0 - Production vsnsta=0 vsnsql=e vsnxtr=3 Windows 2000 Version 5.0 Service Pack 3, CPU type 586 Oracle8i Enterprise Edition release 8.1.7.0.0 - Production With the Partitioning option JServer release 8.1.7.0.0 - Production Windows 2000 Version 5.0 Service Pack 3, CPU type 586 Instance name: ora817 Redo thread mounted by this instance: 1 Oracle process number: 10 Windows thread id: 2124, image: ORACLE.EXE *** 2003-01-28 02:13:21.520 *** SESSION ID:(8.1665) 2003-01-28 02:13:21.510 WAIT #1: nam='direct path write' ela= 0 p1=4 p2=1499 p3=1 WAIT #1: nam='direct path write' ela= 0 p1=4 p2=1501 p3=1 WAIT #1: nam='db file sequential read' ela= 0 p1=1 p2=3690 p3=1 WAIT #1: nam='db file sequential read' ela= 0 p1=1 p2=3638 p3=1 WAIT #1: nam='db file sequential read' ela= 12 p1=1 p2=3691 p3=1 WAIT #1: nam='db file sequential read' ela= 0 p1=1 p2=3692 p3=1 = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #2 len=36 dep=1 uid=0 oct=3 lid=0 tim=38025864 hv=1705880752 ad='39be068' select file# from file$ where ts#=:1 END OF STMT PARSE #2:c=0,e=0,p=0,cr=0,cu=0,mis=1,r=0,dep=1,og=0,tim=38025864 ... Approximately 87,700 lines are omitted here, none of which contains a dep=0 action. ... WAIT #1: nam='direct path read' ela= 0 p1=4 p2=3710 p3=1 WAIT #1: nam='direct path read' ela= 0 p1=4 p2=3711 p3=3 WAIT #1: nam='direct path read' ela= 1 p1=4 p2=3586 p3=1 WAIT #1: nam='direct path read' ela= 0 p1=4 p2=3587 p3=4 WAIT #1: nam='direct path read' ela= 0 p1=4 p2=3591 p3=1 WAIT #1: nam='direct path read' ela= 0 p1=4 p2=3592 p3=2 = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #1 len=32 dep=0 uid=5 oct=3 lid=5 tim=38037728 hv=3588977815 ad='39b3e88' select count(*) from dba_source END OF STMT UNMAP #1:c=0,e=3,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=4,tim=38037728 WAIT #1: nam='SQL*Net message from client' ela= 2 p1=1111838976 p2=1 p3=0 FETCH #1:c=0,e=0,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=0,tim=38037730 WAIT #1: nam='SQL*Net message to client' ela= 0 p1=1111838976 p2=1 p3=0
Worse yet, where's the fetch that returned my count from DBA_SOURCE ? The query consumed over ten seconds of elapsed time ”I sat there and watched it ”and it returned one row, yet the only FETCH line in the trace data says the query took practically no time and returned zero rows.
Example 6-9 shows what we wanted to see but couldn't in Example 6-8. This file was created by activating trace before parsing the query. Notice that instead of just two database calls (an UNMAP and a FETCH shown in Example 6-8), we can see five database calls in Example 6-9:
-
The PARSE for the query of DBA_SOURCE , which occurred in the first example before tracing was activated; hence this line was not emitted into Example 6-8.
-
The EXEC for the query, which also occurred in the first example before tracing was activated; hence this line was not emitted into Example 6-8.
-
The FETCH that consumed most of the query's response time. In the first example, this call began before tracing was activated; hence, this line was not emitted into Example 6-8 either.
-
The UNMAP that releases a sort segment used by one of the recursive views.
-
The final FETCH to ensure that there's no more data available from the cursor. Notice that this fetch call returned zero rows.
Finally, notice that activating trace before the query also graced Example 6-9 with the session's STAT lines, which is a nice bonus in itself.
Example 6-9. This trace file tail was created by tracing the same count of DBA_SOURCE rows, but this time, the tracing attribute was set by the session itself. Because tracing was active when the FETCH call began, the FETCH line appears in the trace data
Dump file C:\oracle\admin\ora817\udump\ORA01588.TRC Tue Jan 28 10:23:25 2003 ORACLE V8.1.7.0.0 - Production vsnsta=0 vsnsql=e vsnxtr=3 Windows 2000 Version 5.0 Service Pack 3, CPU type 586 Oracle8i Enterprise Edition release 8.1.7.0.0 - Production With the Partitioning option JServer release 8.1.7.0.0 - Production Windows 2000 Version 5.0 Service Pack 3, CPU type 586 Instance name: ora817 Redo thread mounted by this instance: 1 Oracle process number: 9 Windows thread id: 1588, image: ORACLE.EXE *** 2003-01-28 10:23:25.791 *** SESSION ID:(8.1790) 2003-01-28 10:23:25.781 APPNAME mod='SQL*Plus' mh=3669949024 act='' ah=4029777240 = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #1 len=69 dep=0 uid=5 oct=42 lid=5 tim=40966100 hv=589283212 ad='394821c' alter session set events '10046 trace name context forever, level 8' END OF STMT EXEC #1:c=0,e=2,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=4,tim=40966101 WAIT #1: nam='SQL*Net message to client' ela= 0 p1=1111838976 p2=1 p3=0 *** 2003-01-28 10:23:36.267 WAIT #1: nam='SQL*Net message from client' ela= 1046 p1=1111838976 p2=1 p3=0 = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #2 len=37 dep=1 uid=0 oct=3 lid=0 tim=40967147 hv=1966425544 ad='3afe9c4' select text from view$ where rowid=:1 END OF STMT PARSE #2:c=0,e=0,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=40967147 EXEC #2:c=0,e=0,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=40967147 WAIT #2: nam='db file sequential read' ela= 5 p1=1 p2=1669 p3=1 FETCH #2:c=0,e=5,p=1,cr=2,cu=0,mis=0,r=1,dep=1,og=4,tim=40967152 STAT #2 id=1 cnt=1 pid=0 pos=0 obj=59 op='TABLE ACCESS BY USER ROWID VIEW$ ' = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #1 len=32 dep=0 uid=5 oct=3 lid=5 tim=40967154 hv=3588977815 ad='39b3e88' select count(*) from dba_source END OF STMT PARSE #1:c=1,e=8,p=1,cr=2,cu=0,mis=1,r=0,dep=0,og=4,tim=40967155 EXEC #1:c=0,e=0,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=4,tim=40967155 WAIT #1: nam='SQL*Net message to client' ela= 0 p1=1111838976 p2=1 p3=0 WAIT #1: nam='db file sequential read' ela= 2 p1=1 p2=53 p3=1 WAIT #1: nam='db file sequential read' ela= 2 p1=1 p2=642 p3=1 WAIT #1: nam='db file sequential read' ela= 0 p1=1 p2=62 p3=1 ... Approximately 6,700 lines are omitted here, none of which contains a dep=0 action. ... WAIT #1: nam='direct path read' ela= 0 p1=4 p2=1944 p3=2 WAIT #1: nam='direct path read' ela= 0 p1=4 p2=1834 p3=1 WAIT #1: nam='direct path read' ela= 0 p1=4 p2=1835 p3=4 WAIT #1: nam='direct path read' ela= 0 p1=4 p2=1839 p3=1 WAIT #1: nam='direct path read' ela= 1 p1=4 p2=1840 p3=2 FETCH #1:c=1449,e=3669,p=6979,cr=879863,cu=10,mis=0,r=1,dep=0,og=4,tim=40970824 UNMAP #1:c=0,e=0,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=4,tim=40970824 WAIT #1: nam='SQL*Net message from client' ela= 0 p1=1111838976 p2=1 p3=0 FETCH #1:c=0,e=0,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=0,tim=40970824 WAIT #1: nam='SQL*Net message to client' ela= 0 p1=1111838976 p2=1 p3=0 WAIT #1: nam='SQL*Net message from client' ela= 951 p1=1111838976 p2=1 p3=0 XCTEND rlbk=0, rd_only=1 STAT #1 id=1 cnt=1 pid=0 pos=0 obj=0 op='SORT AGGREGATE ' STAT #1 id=2 cnt=436983 pid=1 pos=1 obj=0 op='VIEW DBA_SOURCE ' STAT #1 id=3 cnt=436983 pid=2 pos=1 obj=0 op='SORT UNIQUE ' STAT #1 id=4 cnt=436983 pid=3 pos=1 obj=0 op='UNION-ALL ' STAT #1 id=5 cnt=436983 pid=4 pos=1 obj=0 op='NESTED LOOPS ' STAT #1 id=6 cnt=405 pid=5 pos=1 obj=0 op='NESTED LOOPS ' STAT #1 id=7 cnt=22 pid=6 pos=1 obj=22 op='TABLE ACCESS FULL USER$ ' STAT #1 id=8 cnt=425 pid=6 pos=2 obj=18 op='TABLE ACCESS BY INDEX ROWID OBJ$ ' STAT #1 id=9 cnt=3200 pid=8 pos=1 obj=34 op='INDEX RANGE SCAN ' STAT #1 id=10 cnt=436983 pid=5 pos=2 obj=64 op='TABLE ACCESS BY INDEX ROWID SOURCE$ ' STAT #1 id=11 cnt=437387 pid=10 pos=1 obj=109 op='INDEX RANGE SCAN ' STAT #1 id=12 cnt=0 pid=4 pos=2 obj=0 op='NESTED LOOPS ' STAT #1 id=13 cnt=1 pid=12 pos=1 obj=0 op='NESTED LOOPS ' STAT #1 id=14 cnt=1 pid=13 pos=1 obj=0 op='FIXED TABLE FULL X$JOXFT ' STAT #1 id=15 cnt=0 pid=13 pos=2 obj=18 op='TABLE ACCESS BY INDEX ROWID OBJ$ ' STAT #1 id=16 cnt=0 pid=15 pos=1 obj=33 op='INDEX UNIQUE SCAN ' STAT #1 id=17 cnt=0 pid=12 pos=2 obj=22 op='TABLE ACCESS CLUSTER USER$ ' STAT #1 id=18 cnt=0 pid=17 pos=1 obj=11 op='INDEX UNIQUE SCAN '
Activating extended SQL trace in the midst of any long-running database call is prone to causing problems with missing data, like the one you've just seen. It is important that you be able to recognize when you have committed a data collection error like this. Otherwise , if you promote data with this error from data collection into your problem diagnosis phase, you're going to be sent down a rat hole of having to deal with potentially massive amounts of over accounted-for time.
You can detect such a collection error by noticing that the sum of the ela values for a sequence of wait events ( WAIT lines) drastically exceeds the confines of the total elapsed duration ( e value) of the database call that motivated those wait events. In Example 6-8, you can see the problem by noticing that the more than 87,700 WAIT #1 lines accounted for far more than the e=3 centiseconds of elapsed duration for the UNMAP #1 call that immediately followed those WAIT lines.
The only cure for this type of collection error that I can recommend is prevention. Avoid activating SQL trace in the midst of a long-running database call. If an existing trace file contains such an error, then your best remedy is to begin your data collection procedure again.
|
6.4.1.3 Excess database call data at trace activation
Sometimes, the reported duration of a database call exceeds the duration for which the session's tracing attribute has been activated. This phenomenon has occurred whenever a database call's start time (value of tim - e ) precedes the data collection start time (that is, when tim - e < t ). We have observed this phenomenon in some cases when tracing has been activated by a third-party session in the midst of a long-running PL/SQL block. (The presence of a long-running PL/SQL block is what distinguishes this case from the one discussed previously, in which tracing is simply activated in the midst of a long-running database call.) The only actions in a trace file that can suffer from the excess time phenomenon are the first actions listed in the file for a given recursive depth ( dep field value).
This phenomenon can be particularly difficult to notice if several thousand WAIT lines (which contain no tim fields) precede your first database call line that contains a tim field. In Chapter 5 you learned how to walk the clock backward from the first tim field value in the file through all of the ela field values until you reach the first line. However, that technique is prone to significant accumulation of systematic error as demonstrated during my explanation of clock-walking in Chapter 5.
A much better way to determine the "virtual" tim value for the first WAIT line in a trace file is to establish conversion functions that allow you to convert between Oracle tim field values and the system wall clock and back. You can establish a correlation between the Oracle tim clock and your system's wall clock by executing the following steps:
-
Execute the following commands in SQL*Plus on the system for which you are trying to establish the clock correlation:
alter system set events '10046 trace name context forever, level 8'; execute sys.dbms_system.ksdddt; exit
-
Examine the resulting trace data. It will contain lines like the following:
*** 2003-01-28 14:30: 56.513 EXEC #1:c=0,e=483,p=0,cr=0,cu=0,mis=0,r=1,dep=0,og=4,tim=10437858 56513 829
-
From this information, you can establish the direct equivalence of the given tim field value to the given timestamp. In the example shown here, notice the match in the seconds and milliseconds portions of the two times (highlighted). On our research system, the mapping is simple: each tim field value is simply a number of microseconds elapsed since the Unix Epoch (00:00:00 UTC, 1 January 1970). The program shown in Example 6-10 is the tool I use to convert back and forth between tim and wall clock values.
Example 6-10. A program that converts Oracle tim values to wall clock values and back
#!/usr/bin/perl # $Header: /home/cvs/cvm-book1/sqltrace/tim.pl,v 1.3 2003/02/05 05:06:58 cvm Exp $ # Cary Millsap (cary.millsap@hotsos.com) # Show the wall time that corresponds to a given tim value use strict; use warnings; use Date::Format qw(time2str); use Date::Parse qw(str2time); my $usage = "Usage:#!/usr/bin/perl # $Header: /home/cvs/cvm-book1/sqltrace/tim.pl,v 1.3 2003/02/05 05:06:58 cvm Exp $ # Cary Millsap (cary.millsap@hotsos.com) # Show the wall time that corresponds to a given tim value use strict; use warnings; use Date::Format qw(time2str); use Date::Parse qw(str2time); my $usage = "Usage: $0 wall-time\n $0 tim-value\n\t"; my $arg = shift or die $usage; # tim or wall-time value # printf "arg =%s\n", $arg; if ($arg =~ /^[0-9]+$/) { # input argument is a tim value my $sec = substr($arg, 0, length($arg)-6); my $msec = substr($arg, -6); # printf "sec =%s\n", $sec; # printf "msec=%s\n", $msec; printf "%s\n", time2str("%T.$msec %A %d %B %Y", $sec); } else { # input argument is a wall time value my $frac = ($arg =~ /\d+:\d+\.(\d+)/) ? $1 : 0; if ((my $l = length $frac) >= 6) { # if length(frac) >=6, then round $frac = sprintf "%6.0f", $frac/(10**($l-6)); } else { # otherwise, right-pad with zeros $frac .= ('0' x (6-$l)); } printf "%s%s\n", str2time($arg), $frac; }wall-time\n#!/usr/bin/perl # $Header: /home/cvs/cvm-book1/sqltrace/tim.pl,v 1.3 2003/02/05 05:06:58 cvm Exp $ # Cary Millsap (cary.millsap@hotsos.com) # Show the wall time that corresponds to a given tim value use strict; use warnings; use Date::Format qw(time2str); use Date::Parse qw(str2time); my $usage = "Usage: $0 wall-time\n $0 tim-value\n\t"; my $arg = shift or die $usage; # tim or wall-time value # printf "arg =%s\n", $arg; if ($arg =~ /^[0-9]+$/) { # input argument is a tim value my $sec = substr($arg, 0, length($arg)-6); my $msec = substr($arg, -6); # printf "sec =%s\n", $sec; # printf "msec=%s\n", $msec; printf "%s\n", time2str("%T.$msec %A %d %B %Y", $sec); } else { # input argument is a wall time value my $frac = ($arg =~ /\d+:\d+\.(\d+)/) ? $1 : 0; if ((my $l = length $frac) >= 6) { # if length(frac) >=6, then round $frac = sprintf "%6.0f", $frac/(10**($l-6)); } else { # otherwise, right-pad with zeros $frac .= ('0' x (6-$l)); } printf "%s%s\n", str2time($arg), $frac; }tim-value\n\t"; my $arg = shift or die $usage; # tim or wall-time value # printf "arg =%s\n", $arg; if ($arg =~ /^[0-9]+$/) { # input argument is a tim value my $sec = substr($arg, 0, length($arg)-6); my $msec = substr($arg, -6); # printf "sec =%s\n", $sec; # printf "msec=%s\n", $msec; printf "%s\n", time2str("%T.$msec %A %d %B %Y", $sec); } else { # input argument is a wall time value my $frac = ($arg =~ /\d+:\d+\.(\d+)/) ? : 0; if ((my $l = length $frac) >= 6) { # if length(frac) >=6, then round $frac = sprintf "%6.0f", $frac/(10**($l-6)); } else { # otherwise, right-pad with zeros $frac .= ('0' x (6-$l)); } printf "%s%s\n", str2time($arg), $frac; }
Here is a simple example of a trace file whose initial lines contain data for events that occur before the moment of collection activation:
*** 2003-02-24 04:28:19.557 WAIT #1: ... ela= 20000000 ... EXEC #1:c=10000000,e=30000000,...,tim= 1046082501582881
The problem is difficult to recognize until you convert the time values shown here into like units. Using the tool shown in Example 6-10 to convert the tim value on my Linux system to a more readable wall clock time, you can see that the execute call concluded only 2.025881 seconds after the moment tracing was activated:
$ perl tim.pl 1046082501582881 04:28:21.582881 Monday 24 February 2003
The twist is that the execute call consumed 30 seconds of elapsed time ( e=30000000 ). Thus, part of the elapsed duration for this database call occurred prior to the timestamp printed at the beginning of the trace file. I've already shown that this timestamp doesn't always match the time at which the session's tracing attribute was actually set. You need to keep track of the tracing activation time (call it t ) separately. The easiest way to do it is to mark the time in tim field units when you execute the command to activate SQL trace.
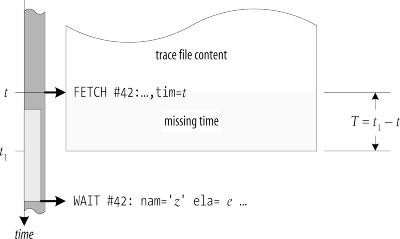
Once you have identified that there is excess time accounted for within a trace file, the next task is to eliminate it. Figure 6-7 shows how. In this figure, SQL trace is activated at time t , in the midst of some parse call that occurs within a long-running PL/SQL block. In this case, some of the parse call's duration e occurs within the desired observation interval, and some occurs before t . The excess time in this case is easy to compute, as long as you know the value of t in tim units. You can compute the excess time T as:
- T = t - ( t - e )
When the first several lines emitted into the trace file contain no tim field value, then you can compute the file's beginning t value by translating the initial timestamp value (on the *** line) into an equivalent tim value as I described previously. Remember, a timestamp is the ending time of action following that line in the trace file. The problem then reduces to the same situation as the one described in Figure 6-7, in which you know t , e , t (and in fact all of the intervening ela values as well in case one of the wait event durations includes time t as well).
Figure 6-7. When SQL trace is activated by a third-party session at time t , tracing can begin in the midst of a database call. When this occurs, the trace file contains excess time that the database call consumed before SQL trace was activated

6.4.2 Missing Time at Trace Deactivation
When a session terminates with extended SQL trace turned on, all of the time near the end of the session will be accounted for in the trace file. Likewise, when a session deactivates its own tracing with an ALTER SESSION SET EVENTS command, all of the session's time up to that execution will be accounted for. However, if tracing is deactivated by a third-party session, then it is likely that the deactivation will occur in the midst of either a wait event or a database call being performed by the session. When this occurs, some desirable data about the session will be missing from the trace file.
For example, I deactivated tracing for a given session at time tim=10437887 33690992 . However, the tail of trace file contains only the following data:
*** 2003-01-28 15:18:43.688 WAIT #1: nam='SQL*Net message from client' ela= 24762690 p1=1650815232 p2=1 p3=0 STAT #1 id=1 cnt=1 pid=0 pos=0 obj=0 op='MERGE JOIN ' STAT #1 id=2 cnt=1 pid=1 pos=1 obj=0 op='SORT JOIN ' STAT #1 id=3 cnt=1 pid=2 pos=1 obj=0 op='FIXED TABLE FULL X$KSUSE ' STAT #1 id=4 cnt=1 pid=1 pos=2 obj=0 op='SORT JOIN ' STAT #1 id=5 cnt=9 pid=4 pos=1 obj=0 op='FIXED TABLE FULL X$KSUPR ' = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #1 len=39 dep=0 uid=5 oct=3 lid=5 tim=1043788723689828 hv=364789794 ad='512c8b5c' select 'missing time at tail' from dual END OF STMT PARSE #1:c=0,e=871,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=4,tim=1043788723689794 EXEC #1:c=0,e=72,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=4,tim=1043788723690030 WAIT #1: nam='SQL*Net message to client' ela= 5 p1=1650815232 p2=1 p3=0 FETCH #1:c=0,e=118,p=0,cr=1,cu=2,mis=0,r=1,dep=0,og=4,tim=1043788723690276 WAIT #1: nam='SQL*Net message from client' ela= 445 p1=1650815232 p2=1 p3=0 FETCH #1:c=0,e=2,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=0,tim=10437887 23690992 WAIT #1: nam='SQL*Net message to client' ela= 4 p1=1650815232 p2=1 p3=0
Notice the highlighted portion of the final tim field value: the trace file contains information about what happened up to time ...23.690992 ( expressed in seconds), and in fact 4 ms afterward, but there's no record of what happened between times ...23.690992 and ...33.690992. There is unaccounted-for time of exactly 10 seconds.
Figure 6-8 shows how this happens. In this figure, SQL trace is deactivated at time t 1 , in the midst of a wait event named z . But the Oracle kernel cannot emit a wait event's trace line until that wait event has completed. Since trace deactivation has occurred before the wait event's conclusion, nothing about the wait event is emitted to the trace file. Part of the wait event's duration occurs after t 1 , but the portion of its duration that occurred before t 1 remains unaccounted for.
Figure 6-8. When SQL trace is deactivated by a third-party session at time t 1 , tracing can end in the midst of an event. When this occurs, the time consumed by the event is never printed into the trace file, resulting in missing time
The missing time in this case is easy to compute as long as you know the value of t 1 in tim units. You can compute the missing time as:
- T = t 1 - t
Again, the easiest way to keep track of t 1 is to mark the time when you execute the command to deactivate SQL trace. When you deactivate SQL trace, you also need to determine the name of the event that is in progress at time t 1 . This is easy to accomplish from the third-party session with the following SQL:
select event from v$session_wait where sid=:sid and state='WAITING'
In the Hotsos Sparky data collector, we execute a query that is similar to this one immediately prior to executing the command to activate tracing. If this query returns no event name, then you should attribute the missing time T to total CPU consumption. If this query does return an event name, then at least some of the missing time T is attributable to the event whose name is returned by the query. As you can see in Figure 6-8, some of the missing time may still be attributable to CPU consumption.
|
It may be possible to determine approximately how much of T you should attribute to CPU consumption and how much to event . However, our field work has shown that when the V$SESSION_WAIT query returns an event name, attributing all of T to that event is a good approximation .
The presence of WAIT lines at the tail of the trace file complicates the computation of missing time slightly by introducing another walk-the-clock exercise. In this case, you must construct t by walking the clock forward through ela field values from the final tim field value in the file.
6.4.3 Incomplete Recursive SQL Data
Activating and deactivating SQL trace from a third-party session can also cause truncation of the trace data required to determine the nature of recursive SQL relationships. Activating SQL trace after the execution of recursive actions but before the completion of their parent action causes trace data that is absent the child data. For example, if you execute the following PL/SQL code, the resulting trace file will reveal several recursive relationships between the various elements of the block and the block itself:
alter session set events '10046 trace name context forever, level 8'; declare cursor lc is select count(*) from sys.source$; cnt number; begin open lc; fetch lc into cnt; close lc; open lc; fetch lc into cnt; close lc; end; /
However, you change the trace data considerably if you omit the ALTER SESSION command and activate tracing from a third-party session (with, for example, DBMS_SUPPORT.START_TRACE_IN_SESSION ) in the midst of the block's execution. What you'll find if you do this is that the kernel will omit a significant amount of detail for any of the recursive child actions whose executions began before tracing was activated. Activating SQL trace from a third-party session creates the possibility that the trace file will not contain child database calls for all the recursive parent actions listed in the trace file.
As in the missing database call data at trace activation case described previously, the best remedy to this type of data collection error is avoidance. And avoidance should come naturally if you are basing your data collection upon user actions, as you should be. However, even if you hit the "start collecting" button a little late, this type of data collection error is not nearly as severe as the database call-interruption type I described previously. Although there will be missing detail that would perhaps help explain why a session consumed the time it did, at least you'll typically have the parent database call data to help guide your analysis.
Similarly, de activating SQL trace from a third-party session creates the possibility that the trace file will not contain parent database calls for all the recursive ( dep > 0) actions in the trace file. For example, imagine in Example 6-11 that tracing had been active for the beginning of the excerpt but then deactivated by a third-party session at the point labeled [1] . The result is shown in Example 6-12.
Example 6-11. This listing (a copy of Example 6-5) shows what really happened during the parse of the DBA_OBJECTS query: the parse motivated three recursive database calls upon a query of VIEW$
... = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #2 len=37 dep=1 uid=0 oct=3 lid=0 tim=1033174180230513 hv=1966425544 ad='514bb478' select text from view$ where rowid=:1 END OF STMT PARSE #2:c=0,e=107,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1033174180230481 BINDS #2: bind 0: dty=11 mxl=16(16) mal=00 scl=00 pre=00 oacflg=18 oacfl2=1 size=16 offset=0 bfp=0a22c34c bln=16 avl=16 flg=05 value=00000AB8.0000.0001 EXEC #2:c=0,e=176,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1033174180230878 FETCH #2:c=0,e=89,p=0,cr=2,cu=0,mis=0,r=1,dep=1,og=4,tim=1033174180231021 [1] STAT #2 id=1 cnt=1 pid=0 pos=0 obj=62 op='TABLE ACCESS BY USER ROWID VIEW$ ' = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #1 len=85 dep=0 uid=5 oct=3 lid=5 tim=1033174180244680 hv=1205236555 ad='50cafbec' select object_id, object_type, owner, object_name from dba_objects where object_id=:v END OF STMT PARSE #1:c=10000,e=15073,p=0,cr=2,cu=0,mis=1,r=0, dep=0 ,og=0,tim=1033174180244662 ...
In Example 6-11, you have positive evidence of a recursive relationship among database calls, because there are three actions listed with the string dep=1 (highlighted in both Example 6-11 and Example 6-12). The problem in Example 6-12 is that tracing was deactivated before the Oracle kernel emitted any information for the dep=0 recursive parent of these actions. Note that in Example 6-11, you can see the dep=0 action (highlighted) that serves as the parent, but in Example 6-12, the trace was deactivated before the dep=0 parent was emitted to the trace file.
Example 6-12. In this trace file tail, there is no database call following the dep=1 actions to act as these actions' parent
... = = = = = = = = = = = = = = = = = = = = = PARSING IN CURSOR #2 len=37 dep=1 uid=0 oct=3 lid=0 tim=1033174180230513 hv=1966425544 ad='514bb478' select text from view$ where rowid=:1 END OF STMT PARSE #2:c=0,e=107,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1033174180230481 BINDS #2: bind 0: dty=11 mxl=16(16) mal=00 scl=00 pre=00 oacflg=18 oacfl2=1 size=16 offset=0 bfp=0a22c34c bln=16 avl=16 flg=05 value=00000AB8.0000.0001 EXEC #2:c=0,e=176,p=0,cr=0,cu=0,mis=0,r=0,dep=1,og=4,tim=1033174180230878 FETCH #2:c=0,e=89,p=0,cr=2,cu=0,mis=0,r=1,dep=1,og=4,tim=1033174180231021 STAT #2 id=1 cnt=1 pid=0 pos=0 obj=62 op='TABLE ACCESS BY USER ROWID VIEW$ ' End of file
From the truncated data of Example 6-12, you can know that there are three recursive SQL actions that have a parent somewhere, but you cannot know the identity of that parent. These database calls are thus "orphans." Deactivating SQL trace from a third-party session creates the possibility that the trace file will not contain parent database calls for all the recursive ( dep > 0) actions listed in the trace file.
Once again, the best remedy for this type of collection error is avoidance. Avoidance of this type of error should come naturally if you are basing your data collection stop time upon the observation of a user action, as you should be.
| |
| Top |
EAN: 2147483647
Pages: 102