12 Virtual Execution System
| The Virtual Execution System (VES) provides an environment for executing managed code. It provides direct support for a set of built-in data types, defines a hypothetical machine with an associated machine model and state, a set of control flow constructs, and an exception handling model. To a large extent, the purpose of the VES is to provide the support required to execute the Common Intermediate Language instruction set (see Partition III). 12.1 Supported Data TypesThe CLI directly supports the data types shown in Table 2-6, Data Types Directly Supported by the CLI Instruction Set. That is, these data types can be manipulated using the CIL instruction set (see Partition III).
The CLI model uses an evaluation stack. Instructions that copy values from memory to the evaluation stack are "loads"; instructions that copy values from the stack back to memory are "stores." The full set of data types in Table 2-6, Data Types Directly Supported by the CLI Instruction Set, can be represented in memory. However, the CLI supports only a subset of these types in its operations upon values stored on its evaluation stack int32, int64, native int. In addition, the CLI supports an internal data type to represent floating point values on the internal evaluation stack. The size of the internal data type is implementation-dependent. For further information on the treatment of floating point values on the evaluation stack, see Partition I, section 12.1.3 and Partition III. Short numeric values (int8, int16, unsigned int8, unsigned int16) are widened when loaded (memory-to-stack) and narrowed when stored (stack-to-memory). This reflects a computer model that assumes, for numeric and object references, [that] memory cells are 1, 2, 4, or 8 bytes wide but stack locations are either 4 or 8 bytes wide. User-defined value types may appear in memory locations or on the stack and have no size limitation; the only built-in operations on them are those that compute their address and copy them between the stack and memory. The only CIL instructions with special support for short numeric values (rather than support for simply the 4- or 8-byte integral values) are:
The signed integer (int8, int16, int32, int64, and native int) and the respective unsigned integer (unsigned int8, unsigned int16, unsigned int32, unsigned int64, and native unsigned int) types differ only in how the bits of the integer are interpreted. For those operations where an unsigned integer is treated differently from a signed integer (e.g., comparisons or arithmetic with overflow) there are separate instructions for treating an integer as unsigned (e.g., cgt.un and add.ovf.u). This instruction set design simplifies CIL-to-native-code (e.g., JIT) compilers and interpreters of CIL by allowing them to internally track a smaller number of data types. See Partition I, section 12.3.2.1. As described below, CIL instructions do not specify their operand types. Instead, the CLI keeps track of operand types based on data flow and aided by a stack consistency requirement described below. For example, the single add instruction will add two integers or two floats from the stack.
12.1.1 Native Size: native int, native unsigned int, O, and &The native-size, or generic, types (native int, native unsigned int, O, and &) are a mechanism in the CLI for deferring the choice of a value's size. These data types exist as CIL types. But the CLI maps each to the native size for a specific processor. (For example, data type I would map to int32 on a Pentium processor, but to int64 on an IA64 processor). So, the choice of size is deferred until JIT compilation or runtime, when the CLI has been initialized and the architecture is known. This implies that field and stack frame offsets are also not known at compile time. For languages like Visual Basic, where field offsets are not computed early anyway, this is not a hardship. In languages like C or C++, where sizes must be known when source code is compiled, a conservative assumption that they occupy 8 bytes is sometimes acceptable (for example, when laying out compile-time storage). 12.1.1.1 Unmanaged Pointers as Type Native Unsigned IntRATIONALE For languages like C, when compiling all the way to native code, where the size of a pointer is known at compile time and there are no managed objects, the fixed-size unsigned integer types (unsigned int32 or unsigned int64) may serve as pointers. However, choosing pointer size at compile time has its disadvantages. If pointers were chosen to be 32-bit quantities at compile time, the code would be restricted to 4 gigabytes of address space, even if it were run on a 64-bit machine. Moreover, a 64-bit CLI would need to take special care so those pointers passed back to 32-bit code would always fit in 32 bits. If pointers were chosen at compile time to be 64 bits, the code would run on a 32-bit machine, but pointers in every data structure would be twice as large as necessary on that CLI. For other languages, where the size of a data type need not be known at compile time, it is desirable to defer the choice of pointer size from compile time to CLI initialization time. In that way, the same CIL code can handle large address spaces for those applications that need them, while also being able to reap the size benefit of 32-bit pointers for those applications that do not need a large address space. The native unsigned int type is used to represent unmanaged pointers with the VES. The metadata allows unmanaged pointers to be represented in a strongly typed manner, but these types are translated into type native unsigned int for use by the VES. 12.1.1.2 Managed Pointer Types: O and &The O data type represents an object reference that is managed by the CLI. As such, the number of specified operations is severely limited. In particular, references shall only be used on operations that indicate that they operate on reference types (e.g., ceq and ldind.ref), or on operations whose metadata indicates that references are allowed (e.g., call, ldsfld, and stfld). The & data type (managed pointer) is similar to the O type but points to the interior of an object. That is, a managed pointer is allowed to point to a field within an object or an element within an array, rather than to point to the "start" of object or array.
Object references (O) and managed pointers (&) may be changed during garbage collection, since the data to which they refer may be moved. NOTE In summary, object references, or O types, refer to the "outside" of an object, or to an object as a whole. But managed pointers, or & types, refer to the interior of an object. The & types are sometimes called "by-ref types" in source languages, since passing a field of an object by reference is represented in the VES by using an & type to represent the type of the parameter. In order to allow managed pointers to be used more flexibly, they are also permitted to point to areas that aren't under the control of the CLI garbage collector, such as the evaluation stack, static variables, and unmanaged memory. This allows them to be used in many of the same ways that unmanaged pointers (U) are used. Verification restrictions guarantee that, if all code is verifiable, a managed pointer to a value on the evaluation stack doesn't outlast the life of the location to which it points. 12.1.1.3 Portability: Storing Pointers in MemorySeveral instructions, including calli, cpblk, initblk, ldind.*, and stind.*, expect an address on the top of the stack. If this address is derived from a pointer stored in memory, there is an important portability consideration.
12.1.2 Handling of Short Integer Data TypesThe CLI defines an evaluation stack that contains either 4-byte or 8-byte integers, but a memory model that encompasses in addition 1-byte and 2-byte integers. To be more precise, the following rules are part of the CLI model:
It is the responsibility of any translator from CIL to native machine instructions to make sure that these rules are faithfully modeled through the native conventions of the target machine. The CLI does not specify, for example, whether truncation of short integer arguments occurs at the call site or in the target method.
12.1.3 Handling of Floating Point Data TypesFloating point calculations shall be handled as described in IEC 60559:1989. This standard describes encoding of floating point numbers, definitions of the basic operations and conversion, rounding control, and exception handling. The standard defines special values, NaN (not a number), +infinity, and infinity. These values are returned on overflow conditions. A general principle is that operations that have a value in the limit return an appropriate infinity while those that have no limiting value return NaN, but see the standard for details. NOTE The following examples show the most commonly encountered cases. X rem 0 = NaN 0 * +infinity = 0 * -infinity = NaN (X / 0) = +infinity, if X>0 NaN, if X=0 -infinity, if X < 0 NaN op X = X op NaN = NaN for all operations (+infinity) + (+infinity) = (+infinity) X / (+infinity) = 0 X mod (-infinity) = -X (+infinity) (+infinity) = NaN NOTE This standard does not specify the behavior of arithmetic operations on denormalized floating point numbers, nor does it specify when or whether such representations should be created. This is in keeping with IEC 60559:1989. In addition, this standard does not specify how to access the exact bit pattern of NaNs that are created, nor the behavior when converting a NaN between 32-bit and 64-bit representation. All of this behavior is deliberately left implementation-specific. For purposes of comparison, infinite values act like a number of the correct sign but with a very large magnitude when compared with finite values. NaN is "unordered" for comparisons (see clt, clt.un). While the IEC 60559:1989 standard also allows for exceptions to be thrown under unusual conditions (such as overflow and invalid operand), the CLI does not generate these exceptions. Instead, the CLI uses the NaN, +infinity, and infinity return values and provides the instruction ckfinite to allow users to generate an exception if a result is NaN, +infinity, or infinity. The rounding mode defined in IEC 60559:1989 shall be set by the CLI to "round to the nearest number," and neither the CIL nor the class library provide a mechanism for modifying this setting. Conforming implementations of the CLI need not be resilient to external interference with this setting. That is, they need not restore the mode prior to performing floating point operations, but rather may rely on it having been set as part of their initialization.
For conversion to integers, the default operation supplied by the CIL is "truncate toward zero." There are class libraries supplied to allow floating point numbers to be converted to integers using any of the other three traditional operations (round to nearest integer, floor (truncate towards infinity), ceiling (truncate toward +infinity)). Storage locations for floating point numbers (statics, array elements, and fields of classes) are of fixed size. The supported storage sizes are float32 and float64. Everywhere else (on the evaluation stack, as arguments, as return types, and as local variables) floating point numbers are represented using an internal floating point type. In each such instance, the nominal type of the variable or expression is either R4 or R8, but its value may be represented internally with additional range and/or precision. The size of the internal floating point representation is implementation-dependent, may vary, and shall have precision at least as great as that of the variable or expression being represented. An implicit widening conversion to the internal representation from float32 or float64 is performed when those types are loaded from storage. The internal representation is typically the native size for the hardware, or as required for efficient implementation of an operation. The internal representation shall have the following characteristics:
NOTE This implies that an implicit widening conversion from float32 (or float64) to the internal representation, followed by an explicit conversion from the internal representation to float32 (or float64), will result in a value that is identical to the original float32 (or float64) value. RATIONALE This design allows the CLI to choose a platform-specific high performance representation for floating point numbers until they are placed in storage locations. For example, it may be able to leave floating point variables in hardware registers that provide more precision than a user has requested. At the same time, CIL generators can force operations to respect language-specific rules for representations through the use of conversion instructions. When a floating point value whose internal representation has greater range and/or precision than its nominal type is put in a storage location, it is automatically coerced to the type of the storage location. This may involve a loss of precision or the creation of an out-of-range value (NaN, +infinity, or infinity). However, the value may be retained in the internal representation for future use, if it is reloaded from the storage location without having been modified. It is the responsibility of the compiler to ensure that the retained value is still valid at the time of a subsequent load, taking into account the effects of aliasing and other execution threads (see Partition I, section 12.6). This freedom to carry extra precision is not permitted, however, following the execution of an explicit conversion (conv.r4 or conv.r8), at which time the internal representation must be exactly representable in the associated type. NOTE To detect values that cannot be converted to a particular storage type, a conversion instruction (conv.r4, or conv.r8) may be used, followed by a check for a non-finite value using ckfinite. To detect underflow when converting to a particular storage type, a comparison to zero is required before and after the conversion. NOTE The use of an internal representation that is wider than float32 or float64 may cause differences in computational results when a developer makes seemingly unrelated modifications to their code, the result of which may be that a value is spilled from the internal representation (e.g., in a register) to a location on the stack.
12.1.4 CIL Instructions and Numeric Types
Most CIL instructions that deal with numbers take their operands from the evaluation stack (see Partition I, section 12.3.2.1), and these inputs have an associated type that is known to the VES. As a result, a single operation like add can have inputs of any numeric data type, although not all instructions can deal with all combinations of operand types. Binary operations other than addition and subtraction require that both operands be of the same type. Addition and subtraction allow an integer to be added to or subtracted from a managed pointer (types & and O). Details are specified in Partition II. Instructions fall into the following categories: Numeric: These instructions deal with both integers and floating point numbers, and consider integers to be signed. Simple arithmetic, conditional branch, and comparison instructions fit in this category. Integer: These instructions deal only with integers. Bit operations and unsigned integer division/remainder fit in this category. Floating point: These instructions deal only with floating point numbers. Specific: These instructions deal with integer and/or floating point numbers, but have variants that deal specially with different sizes and unsigned integers. Integer operations with overflow detection, data conversion instructions, and operations that transfer data between the evaluation stack and other parts of memory (see Partition I, section 12.3.2) fit into this category. Unsigned/unordered: There are special comparison and branch instructions that treat integers as unsigned and consider unordered floating point numbers specially (as in "branch if greater than or unordered"): Load constant: The load constant (ldc.*) instructions are used to load constants of type int32, int64, float32, or float64. Native size constants (type native int) shall be created by conversion from int32 (conversion from int64 would not be portable) using conv.i or conv.u. Table 2-7, CIL Instructions by Numeric Category, shows the CIL instructions that deal with numeric values, along with the category to which they belong. Instructions that end in ".*" indicate all variants of the instruction (based on size of data and whether the data is treated as signed or unsigned).
12.1.5 CIL Instructions and Pointer Types
RATIONALE Some implementations of the CLI will require the ability to track pointers to objects and to collect objects that are no longer reachable (thus providing memory management by "garbage collection"). This process moves objects in order to reduce the working set and thus will modify all pointers to those objects as they move. For this to work correctly, pointers to objects may only be used in certain ways. The O (object reference) and & (managed pointer) datatypes are the formalization of these restrictions. The use of object references is tightly restricted in the CIL. They are used almost exclusively with the "virtual object system" instructions, which are specifically designed to deal with objects. In addition, a few of the base instructions of the CIL handle object references. In particular, object references can be:
Managed pointers have several additional base operations.
Arithmetic operations upon managed pointers are intended only for use on pointers to elements of the same array. Other uses of arithmetic on managed pointers is unspecified. RATIONALE Since the memory manager runs asynchronously with respect to programs and updates managed pointers, both the distance between distinct objects and their relative position can change.
12.1.6 Aggregate Data
The CLI supports aggregate data, that is, data items that have sub-components (arrays, structures, or object instances) but are passed by copying the value. The sub-components can include references to managed memory. Aggregate data is represented using a value type, which can be instantiated in two different ways:
Because value type instances, specified as method arguments, are copied on method call, they do not have "identity" in the sense that Objects (boxed instances of classes) have. 12.1.6.1 Homes for ValuesThe home of a data value is where it is stored for possible reuse. The CLI directly supports the following home locations:
For each home location, there is a means to compute (at runtime) the address of the home location and a means to determine (at JIT compile time) the type of a home location. These are summarized in Table 2-8, Address and Type of Home Locations. In addition to homes, built-in values can exist in two additional ways (i.e., without homes):
12.1.6.2 Operations on Value Type InstancesValue type instances can be created (see Partition I, section 12.1.6.2.1), passed as arguments (see Partition I, section 12.1.6.2.3), returned as values (see Partition I, section 12.1.6.2.3), and stored into and extracted from locals, fields, and elements of arrays (i.e., copied). Like classes, value types may have both static and non-static members (methods and fields). But, because they carry no type information at runtime, value type instances are not substitutable for items of type Object; in this respect, they act like the built-in types int, long, and so forth. There are two operations, box and unbox (see Partition I, sections 8.2.4 and 12.1.6.2.5), that convert between value type instances and Objects. 12.1.6.2.1 Initializing Instances of Value TypesThere are three options for initializing the home of a value type instance. You can zero it by loading the address of the home (see Table 2-8, Address and Type of Home Locations) and using the initobj instruction (for local variables this is also accomplished by setting the zero initialize bit in the method's header). You can call a user-defined constructor by loading the address of the home (see Table 2-8, Address and Type of Home Locations) and then calling the constructor directly. Or you can copy an existing instance into the home, as described in Partition I, section 12.1.6.2.
12.1.6.2.2 Loading and Storing Instances of Value TypesThere are two ways to load a value type onto the evaluation stack:
Similarly, there are two ways to store a value type from the evaluation stack:
12.1.6.2.3 Passing and Returning Value TypesValue types are treated just as any other value would be treated:
12.1.6.2.4 Calling MethodsStatic methods on value types are handled no differently from static methods on an ordinary class: use a call instruction with a metadata token specifying the value type as the class of the method. Non-static methods (i.e., instance and virtual methods) are supported on value types, but they are given special treatment. A non-static method on a class (rather than a value type) expects a this pointer that is an instance of that class. This makes sense for classes, since they have identity and the this pointer represents that identity. Value types, however, have identity only when boxed. To address this issue, the this pointer on a non-static method of a value type is a by-ref parameter of the value type rather than an ordinary by-value parameter. A non-static method on a value type may be called in the following ways:
12.1.6.2.5 Boxing and UnboxingBox and unbox are conceptually equivalent to (and may be seen in higher-level languages as) casting between a value type instance and System.Object. Because they change data representations, however, boxing and unboxing are like the widening and narrowing of various sizes of integers (the conv and conv.ovf instructions) rather than the casting of reference types (the isinst and castclass instructions). The box instruction is a widening (always typesafe) operation that converts a value type instance to System.Object by making a copy of the instance and embedding it in a newly allocated object. Unbox is a narrowing (runtime exception may be generated) operation that converts a System.Object (whose runtime type is a value type) to a value type instance. This is done by computing the address of the embedded value type instance without making a copy of the instance. 12.1.6.2.6 Castclass and Isinst on Value TypesCasting to and from value type instances isn't permitted (the equivalent operations are box and unbox). When boxed, however, it is possible to use the isinst instruction to see whether a value of type System.Object is the boxed representation of a particular class. 12.1.6.3 Opaque ClassesSome languages provide multi-byte data structures whose contents are manipulated directly by address arithmetic and indirection operations. To support this feature, the CLI allows value types to be created with a specified size but no information about their data members. Instances of these "opaque classes" are handled in precisely the same way as instances of any other class, but the ldfld, stfld, ldflda, ldsfld, and stsfld instructions shall not be used to access their contents.
12.2 Module InformationPartition II[, section 24 and its subsections] provides details of the CLI PE file format. The CLI relies on the following information about each method defined in a PE file:
In addition, the file format is capable of indicating the degree of portability of the file. There is one kind of restriction that may be described:
By stating which restrictions are placed on executing the code, the CLI class loader can prevent non-portable code from running on an architecture that it cannot support.
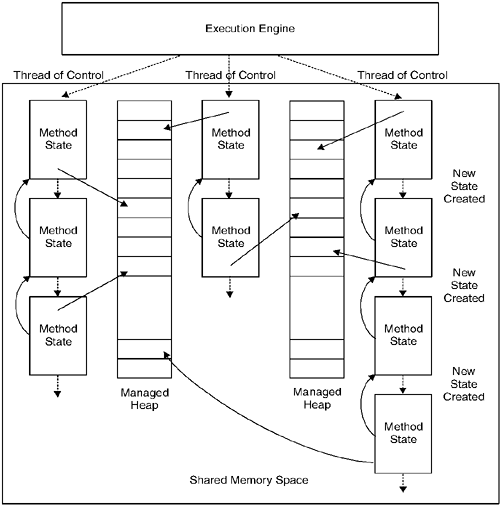
12.3 Machine StateOne of the design goals of the CLI is to hide the details of a method call frame from the CIL code generator. This allows the VES (and not the CIL code generator) to choose the most efficient calling convention and stack layout. To achieve this abstraction, the call frame is integrated into the CLI. The machine state definitions below reflect these design choices, where machine state consists primarily of global state and method state. 12.3.1 The Global StateThe CLI manages multiple concurrent threads of control (not necessarily the same as the threads provided by a host operating system), multiple managed heaps, and a shared memory address space. NOTE A thread of control can be thought of, somewhat simplistically, as a singly linked list of method states, where a new state is created and linked back to the current state by a method call instruction the traditional model of a stack-based calling sequence. Notice that this model of the thread of control doesn't correctly explain the operation of tail., jmp, or throw instructions. Figure 2-4, Machine State Model, illustrates the machine state model, which includes threads of control, method states, and multiple heaps in a shared address space. Method state, shown separately in Figure 2-5, Method State, is an abstraction of the stack frame. Arguments and local variables are part of the method state, but they can contain Object References that refer to data stored in any of the managed heaps. In general, arguments and local variables are only visible to the executing thread, while instance and static fields and array elements may be visible to multiple threads, and modification of such values is considered a side-effect. Figure 2-4. Machine State Model
Figure 2-5. Method State
12.3.2 Method StateMethod state describes the environment within which a method executes. (In conventional compiler terminology, it corresponds to a superset of the information captured in the "invocation stack frame.") The CLI method state consists of the following items:
The four areas of the method state incoming arguments array, local variables array, local memory pool, and evaluation stack are specified as if logically distinct areas. A conforming implementation of the CLI may map these areas into one contiguous array of memory, held as a conventional stack frame on the underlying target architecture, or use any other equivalent representation technique. 12.3.2.1 The Evaluation StackAssociated with each method state is an evaluation stack. Most CLI instructions retrieve their arguments from the evaluation stack and place their return values on the stack. Arguments to other methods and their return values are also placed on the evaluation stack. When a procedure call is made, the arguments to the called methods become the incoming arguments array (see Partition I, section 12.3.2.2) to the method. This may require a memory copy, or simply a sharing of these two areas by the two methods. The evaluation stack is made up of slots that can hold any data type, including an unboxed instance of a value type. The type state of the stack (the stack depth and types of each element on the stack) at any given point in a program shall be identical for all possible control flow paths. For example, a program that loops an unknown number of times and pushes a new element on the stack at each iteration would be prohibited. While the CLI, in general, supports the full set of types described in Partition I, section 12.1, the CLI treats the evaluation stack in a special way. While some JIT compilers may track the types on the stack in more detail, the CLI only requires that values be one of:
The other types are synthesized through a combination of techniques:
12.3.2.2 Local Variables and ArgumentsPart of each method state is an array that holds local variables and an array that holds arguments. Like the evaluation stack, each element of these arrays can hold any single data type or an instance of a value type. Both arrays start at 0 (that is, the first argument or local variable is numbered 0). The address of a local variable can be computed using the ldloca instruction, and the address of an argument using the ldarga instruction. Associated with each method is metadata that specifies:
The VES inserts padding as appropriate for the target architecture. That is, on some 64-bit architectures all local variables may be 64-bit aligned, while on others they may be 8-, 16-, or 32-bit aligned. The CIL generator shall make no assumptions about the offsets of local variables within the array. In fact, the VES is free to reorder the elements in the local variable array, and different JITters may choose to order them in different ways. 12.3.2.3 Variable[-Length] Argument ListsThe CLI works in conjunction with the class library to implement methods that accept argument lists of unknown length and type ("varargs methods"). Access to these arguments is through a typesafe iterator in the [Base] Class Library, called System.ArgIterator (see the .NET Framework Standard Library Annotated Reference). The CIL includes one instruction provided specifically to support the argument iterator, arglist. This instruction may be used only within a method that is declared to take a variable number of arguments. It returns a value that is needed by the constructor for a System.ArgIterator object. Basically, the value created by arglist provides access both to the address of the argument list that was passed to the method and a runtime data structure that specifies the number and type of the arguments that were provided. This is sufficient for the class library to implement the user-visible iteration mechanism. From the CLI point of view, varargs methods have an array of arguments like other methods. But only the initial portion of the array has a fixed set of types, and only these may be accessed directly using the ldarg, starg, and ldarga instructions. The argument iterator allows access to both this initial segment and the remaining entries in the array.
12.3.2.4 Local Memory PoolPart of each method state is a local memory pool. Memory can be explicitly allocated from the local memory pool using the localloc instruction. All memory in the local memory pool is reclaimed on method exit, and that is the only way local memory pool memory is reclaimed (there is no instruction provided to free local memory that was allocated during this method invocation). The local memory pool is used to allocate objects whose type or size is not known at compile time and which the programmer does not wish to allocate in the managed heap. Because the local memory pool cannot be shrunk during the lifetime of the method, a language implementation cannot use the local memory pool for general-purpose memory allocation.
12.4 Control FlowThe CIL instruction set provides a rich set of instructions to alter the normal flow of control from one CIL instruction to the next.
While the CLI supports control transfers within a method, there are several restrictions that shall be observed:
12.4.1 Method CallsInstructions emitted by the CIL code generator contain sufficient information for different implementations of the CLI to use different native calling conventions. All method calls initialize the method state areas (see Partition I, section 12.3.2) as follows:
12.4.1.1 Call Site DescriptorsCall sites specify additional information that enables an interpreter or JIT compiler to synthesize any native calling convention. All CIL calling instructions (call, calli, and callvirt) include a description of the call site. This description can take one of two forms. The simpler form, used with the calli instruction, is a "call site description" (represented as a metadata token for a stand-alone call signature) that provides:
The more complicated form, used for the call and callvirt instructions, is a "method reference" (a metadata methodref token) that augments the call site description with an identifier for the target of the call instruction.
12.4.1.2 Calling InstructionsThe CIL has three call instructions that are used to transfer new argument values to a destination method. Under normal circumstances, the called method will terminate and return control to the calling method.
In addition, each of these instructions may be immediately preceded by a tail. instruction prefix. This specifies that the calling method terminates with this method call (and returns whatever value is returned by the called method). The tail. prefix instructs the JIT compiler to discard the caller's method state prior to making the call (if the call is from untrusted code to trusted code, the frame cannot be fully discarded for security reasons). When the called method executes a ret instruction, control returns not to the calling method but rather to wherever that method would itself have returned (typically, to the caller's caller). Notice that the tail. instruction shortens the lifetime of the caller's frame so it is unsafe to pass managed pointers (type &) as arguments. Finally, there is an instruction that indicates an optimization of the tail. case, which is the jmp instruction, followed by a methodref or methoddef token, and indicates that the current method's state should be discarded, its arguments should be transferred intact to the destination method, and control should be transferred to the destination. The signature of the calling method shall exactly match the signature of the destination method. 12.4.1.3 Computed DestinationsThe destination of a method call may be either encoded directly in the CIL instruction stream (the call and jmp instructions) or computed (the callvirt and calli instructions). The destination address for a callvirt instruction is automatically computed by the CLI based on the method token and the value of the first argument (the this pointer). The method token shall refer to a virtual method on a class that is a direct ancestor of the class of the first argument. The CLI computes the correct destination by locating the nearest ancestor of the first argument's class that supplies an implementation of the desired method. NOTE The implementation can be assumed to be more efficient than the linear search implied here. For the calli instruction the CIL code is responsible for computing a destination address and pushing it on the stack. This is typically done through the use of a ldftn or ldvirtfn instruction at some earlier time. The ldftn instruction includes a metadata token in the CIL stream that specifies a method, and the instruction pushes the address of that method. The ldvirtfn instruction takes a metadata token for a virtual method in the CIL stream and an object on the stack. It performs the same computation described above for the callvirt instruction but pushes the resulting destination on the stack rather than calling the method. The calli instruction includes a call site description that includes information about the native calling convention that should be used to invoke the method. Correct CIL code shall specify a calling convention specified in the calli instruction that matches the calling convention for the method that is being called. 12.4.1.4 Virtual Calling ConventionThe CIL provides a "virtual calling convention" that is converted by the JIT into a native calling convention. The JIT determines the optimal native calling convention for the target architecture. This allows the native calling convention to differ from machine to machine, including details of register usage, local variable homes, copying conventions for large call-by-value objects (as well as deciding, based on the target machine, what is considered "large"). This also allows the JIT to reorder the values placed on the CIL virtual stack to match the location and order of arguments passed in the native calling convention. The CLI uses a single uniform calling convention for all method calls. It is the responsibility of the JITters to convert this into the appropriate native calling convention. The contents of the stack at the time of a call instruction (call, calli, or callvirt any of which may be preceded by tail.) are as follows:
12.4.1.5 Parameter PassingThe CLI supports three kinds of parameter passing, all indicated in metadata as part of the signature of the method. Each parameter to a method has its own passing convention (e.g., the first parameter may be passed by value while all others are passed by ref). Parameters shall be passed in one of the following ways (see detailed descriptions below):
It is the responsibility of the CIL generator to follow these conventions. Verification checks that the types of parameters match the types of values passed, but is otherwise unaware of the details of the calling convention. 12.4.1.5.1 By-Value ParametersFor built-in types (integers, floats, etc.) the caller copies the value onto the stack before the call. For objects, the object reference (type O) is pushed on the stack. For managed pointers (type &) or unmanaged pointers (type native unsigned int), the address is passed from the caller to the callee. For value types, see the protocol in Partition I, section 12.1.6.2. 12.4.1.5.2 By-Ref ParametersBy-ref parameters are the equivalent of C++ reference parameters or Pascal var parameters: instead of passing as an argument the value of a variable, field, or array element, its address is passed instead; and any assignment to the corresponding parameter actually modifies the corresponding caller's variable, field, or array element. Much of this work is done by the higher-level language, which hides from the user the need to compute addresses to pass a value and the use of indirection to reference or update values. Passing a value by reference requires that the value have a home (see Partition I, section 12.1.6.1), and it is the address of this home that is passed. Constants, and intermediate values on the evaluation stack, cannot be passed as by-ref parameters because they have no home. The CLI provides instructions to support by-ref parameters:
Some addresses (e.g., local variables and arguments) have lifetimes tied to that method invocation. These shall not be referenced outside their lifetimes, and so they should not be stored in locations that last beyond their lifetime. The CIL does not (and cannot) enforce this restriction, so the CIL generator shall enforce this restriction or the resulting CIL will not work correctly. For code to be verifiable (see Partition I, section 8.8), by-ref parameters may only be passed to other methods or referenced via the appropriate stind or ldind instructions. 12.4.1.5.3 Typed Reference ParametersBy-ref parameters and value types are sufficient to support statically typed languages (C++, Pascal, etc.). They also support dynamically typed languages that pay a performance penalty to box value types before passing them to polymorphic methods (Lisp, Scheme, Smalltalk, etc.). Unfortunately, they are not sufficient to support languages like Visual Basic that require by-reference passing of unboxed data to methods that are not statically restricted as to the type of data they accept. These languages require a way of passing both the address of the home of the data and the static type of the home. This is exactly the information that would be provided if the data were boxed, but without the heap allocation required of a box operation. Typed reference parameters address this requirement. A typed reference parameter is very similar to a standard by-ref parameter, but the static data type is passed as well as the address of the data. Like by-ref parameters, the argument corresponding to a typed reference parameter will have a home. NOTE If it were not for the fact that verification and the memory manager need to be aware of the data type and the corresponding address, a by-ref parameter could be implemented as a standard value type with two fields: the address of the data and the type of the data. Like a regular by-ref parameter, a typed reference parameter can refer to a home that is on the stack, and that home will have a lifetime limited by the call stack. Thus, the CIL generator shall apply appropriate checks on the lifetime of by-ref parameters; and verification imposes the same restrictions on the use of typed reference parameters as it does on by-ref parameters (see Partition I, section 12.4.1.5.2). A typed reference is passed by either creating a new typed reference (using the mkrefany instruction) or by copying an existing typed reference. Given a typed reference argument, the address to which it refers can be extracted using the refanyval instruction; the type to which it refers can be extracted using the refanytype instruction.
12.4.1.5.4 Parameter InteractionsA given parameter may be passed using any one of the parameter passing conventions: by-value, by-ref, or typed reference. No combination of these is allowed for a single parameter, although a method may have different parameters with different calling mechanisms. A parameter that has been passed in as typed reference shall not be passed on as by-ref or by-value without a runtime type check and (in the case of by-value) a copy. A by-ref parameter may be passed on as a typed reference by attaching the static type. Table 2-9, Parameter Passing Conventions, illustrates the parameter passing convention used for each data type.
12.4.2 Exception HandlingException handling is supported in the CLI through exception objects and protected blocks of code. When an exception occurs, an object is created to represent the exception. All exception objects are instances of some class (i.e., they can be boxed value types, but not pointers, unboxed value types, etc.). Users may create their own exception classes, typically by subclassing System.Exception (see the .NET Framework Standard Library Annotated Reference). There are four kinds of handlers for protected blocks. A single protected block shall have exactly one handler associated with it:
Protected regions, the type of the associated handler, and the location of the associated handler and (if needed) user-supplied filter code are described through an Exception Handler Table associated with each method. The exact format of the Exception Handler Table is specified in detail in Partition II. Details of the exception handling mechanism are also specified in Partition II, section 18.
12.4.2.1 Exceptions Thrown by the CLICLI instructions can throw the following exceptions as part of executing individual instructions. The documentation for each instruction lists all the exceptions the instruction can throw (except for the general-purpose ExecutionEngineException described below that may be generated by all instructions). Base Instructions (see Partition III[, section 3])
Object Model Instructions (see Partition III[, section 4])
The ExecutionEngineException is special. It can be thrown by any instruction and indicates an unexpected inconsistency in the CLI. Running exclusively verified code can never cause this exception to be thrown by a conforming implementation of the CLI. However, unverified code (even though that code is conforming CIL) can cause this exception to be thrown if it corrupts memory. Any attempt to execute non-conforming CIL or non-conforming file formats can cause completely unspecified behavior: a conforming implementation of the CLI need not make any provision for these cases. There are no exceptions for things like "MetaDataTokenNotFound." CIL verification (see Partition V) will detect this inconsistency before the instruction is executed, leading to a verification violation. If the CIL is not verified, this type of inconsistency shall raise the generic ExecutionEngineException. Exceptions can also be thrown by the CLI, as well as by user code, using the throw instruction. The handing of an exception is identical, regardless of the source. 12.4.2.2 Subclassing of ExceptionsCertain types of exceptions thrown by the CLI may be subclassed to provide more information to the user. The specification of CIL instructions in Partition III describes what types of exceptions should be thrown by the runtime environment when an abnormal situation occurs. Each of these descriptions allows a conforming implementation to throw an object of the type described or an object of a subclass of that type. NOTE For instance, the specification of the ckfinite instruction requires that an exception of type ArithmeticException or a subclass of ArithmeticException be thrown by the CLI. A conforming implementation may simply throw an exception of type ArithmeticException, but it may also choose to provide more information to the programmer by throwing an exception of type NotFiniteNumberException with the offending number. 12.4.2.3 Resolution ExceptionsCIL allows types to reference, among other things, interfaces, classes, methods, and fields. Resolution errors occur when references are not found or are mismatched. Resolution exceptions can be generated by references from CIL instructions, references to base classes, to implemented interfaces, and by references from signatures of fields, methods, and other class members. To allow scalability with respect to optimization, detection of resolution exceptions is given latitude such that it may occur as early as install time and as late as execution time. The latest opportunity to check for resolution exceptions from all references except CIL instructions is as part of initialization of the type that is doing the referencing (see Partition II). If such a resolution exception is detected, the static initializer for that type, if present, shall not be executed. The latest opportunity to check for resolution exceptions in CIL instructions is as part of the first execution of the associated CIL instruction. When an implementation chooses to perform resolution exception checking in CIL instructions as late as possible, these exceptions, if they occur, shall be thrown prior to any other non-resolution exception that the VES may throw for that CIL instruction. Once a CIL instruction has passed the point of throwing resolution errors (it has completed without exception, or has completed by throwing a non-resolution exception), subsequent executions of that instruction shall no longer throw resolution exceptions. If an implementation chooses to detect some resolution errors, from any references, earlier than the latest opportunity for that kind of reference, it is not required to detect all resolution exceptions early. An implementation that detects resolution errors early is allowed to prevent a class from being installed, loaded, or initialized as a result of resolution exceptions detected in the class itself or in the transitive closure of types from following references of any kind. For example, each of the following represents a permitted scenario. An installation program can throw resolution exceptions (thus failing the installation) as a result of checking CIL instructions for resolution errors in the set of items being installed. An implementation is allowed to fail to load a class as a result of checking CIL instructions in a referenced class for resolution errors. An implementation is permitted to load and initialize a class that has resolution errors in its CIL instructions. The following exceptions are among those considered resolution exceptions:
For example, when a referenced class cannot be found, a TypeLoadException is thrown. When a referenced method (whose class is found) cannot be found, a MissingMethodException is thrown. If a matching method being used consistently is accessible but violates declared security policy, a SecurityException is thrown.
12.4.2.4 Timing of ExceptionsCertain types of exceptions thrown by CIL instructions may be detected before the instruction is executed. In these cases, the specific time of the throw is not precisely defined, but the exception should be thrown no later than the instruction is executed. That relaxation of the timing of exceptions is provided so that an implementation may choose to detect and throw an exception before any code is run e.g., at the time of CIL-to-native-code conversion. There is a distinction between the time of detecting the error condition and throwing the associated exception. An error condition may be detected early (e.g., at JIT time), but the condition may be signaled later (e.g., at the execution time of the offending instruction) by throwing an exception. The following exceptions are among those that may be thrown early by the runtime:
12.4.2.5 Overview of Exception HandlingSee the Exception Handling specification in Partition II, section 18 for details. Each method in an executable has associated with it a (possibly empty) array of exception handling information. Each entry in the array describes a protected block, its filter, and its handler (which may be a catch handler, a filter handler, a finally handler, or a fault handler). When an exception occurs, the CLI searches the array for the first protected block
If a match is not found in the current method, the calling method is searched, and so on. If no match is found, the CLI will dump a stack trace and abort the program. NOTE A debugger can intervene and treat this situation like a breakpoint, before performing any stack unwinding, so that the stack is still available for inspection through the debugger. If a match is found, the CLI walks the stack back to the point just located, but this time calling the finally and fault handlers. It then starts the corresponding exception handler. Stack frames are discarded either as this second walk occurs or after the handler completes, depending on information in the exception handler array entry associated with the handling block. Some things to notice are:
12.4.2.6 CIL Support for ExceptionsThe CIL has special instructions to:
12.4.2.7 Lexical Nesting of Protected BlocksA protected region (also called a "try block") is described by two addresses: the trystart is the address of the first instruction to be protected, and [the] tryend is the address immediately following the last instruction to be protected. A handler region is described by two addresses: the handlerstart is the address of the first instruction of the handler, and the handlerend is the address immediately following the last instruction of the handler. There are three kinds of handlers: catch, finally, and fault. A single exception entry consists of
Every method has associated with it a set of exception entries, called the exception set. If an exception entry contains a filterstart, then filterstart < handlerstart. The filter region starts at the instruction specified by filterstart and contains all instructions up to (but not including) that specified by handlerstart. If there is no filterstart, then the filter region is empty (hence does not overlap with any region). No two regions (protected region, handler region, filter region) of a single exception entry may overlap with one another. For every pair of exception entries in an exception set, one of the following must be true:
The encoding of an exception entry in the file format (see Partition II) guarantees that only a catch handler (not a fault handler or finally handler) can have a filter region.
12.4.2.8 Control Flow Restrictions on Protected BlocksThe following restrictions govern control flow into, out of, and between try blocks and their associated handlers.
12.5 Proxies and RemotingA remoting boundary exists if it is not possible to share the identity of an object directly across the boundary. For example, if two objects exist on physically separate machines that do not share a common address space, then a remoting boundary will exist between them. There are other administrative mechanisms for creating remoting boundaries. The VES provides a mechanism, called the application domain, to isolate applications running in the same operating system process from one another. Types loaded into one application domain are distinct from the same type loaded into another application domain, and instances of objects shall not be directly shared from one application domain to another. Hence, the application domain itself forms a remoting boundary. The VES implements remoting boundaries based on the concept of a proxy. A proxy is an object that exists on one side of the boundary and represents an object on the other side. The proxy forwards references to instance fields and methods to the actual object for interpretation. Proxies do not forward references to static fields or calls to static methods. The implementation of proxies is provided automatically for instances of types that derive from System.MarshalByRefObject (see the .NET Framework Standard Library Annotated Reference). 12.6 Memory Model and Optimizations12.6.1 The Memory StoreBy "memory store" we mean the regular process memory that the CLI operates within. Conceptually, this store is simply an array of bytes. The index into this array is the address of a data object. The CLI accesses data objects in the memory store via the ldind.* and stind.* instructions. 12.6.2 AlignmentBuilt-in datatypes shall be properly aligned, which is defined as follows:
Thus, int16 and unsigned int16 start on even address; int32, unsigned int32, and float32 start on an address divisible by 4; and int64, unsigned int64, and float64 start on an address divisible by 4 or 8, depending on the target architecture. The native size types (native int, native unsigned int, and &) are always naturally aligned (4 bytes or 8 bytes, depending on architecture). When generated externally, these should also be aligned to their natural size, although portable code may use 8-byte alignment to guarantee architecture independence. It is strongly recommended that float64 be aligned on an 8-byte boundary, even when the size of native int is 32 bits. There is a special prefix instruction, unaligned., that may immediately precede a ldind, stind, initblk, or cpblk instruction. This prefix indicates that the data may have arbitrary alignment; the JIT is required to generate code that correctly performs the effect of the instructions regardless of the actual alignment. Otherwise, if the data is not properly aligned and no unaligned. prefix has been specified, executing the instruction may generate unaligned memory faults or incorrect data.
12.6.3 Byte OrderingFor data types larger than 1 byte, the byte ordering is dependent on the target CPU. Code that depends on byte ordering may not run on all platforms. The PE file format (see Partition I, section 12.2) allows the file to be marked to indicate that it depends on a particular type ordering. 12.6.4 OptimizationConforming implementations of the CLI are free to execute programs using any technology that guarantees, within a single thread of execution, that side-effects and exceptions generated by a thread are visible in the order specified by the CIL. For this purpose volatile operations (including volatile reads) constitute side-effects. Volatile operations are specified in Partition I, section 12.6.7. There are no ordering guarantees relative to exceptions injected into a thread by another thread (such exceptions are sometimes called "asynchronous exceptions" e.g., System.Threading.ThreadAbortException).
RATIONALE An optimizing compiler is free to reorder side-effects and synchronous exceptions to the extent that this reordering does not change any observable program behavior. NOTE An implementation of the CLI is permitted to use an optimizing compiler for example, to convert CIL to native machine code, provided the compiler maintains (within each single thread of execution) the same order of side-effects and synchronous exceptions. This is a stronger condition than ISO C++ (which permits reordering between a pair of sequence points) or ISO Scheme (which permits reordering of arguments to functions). 12.6.5 Locks and ThreadsThe logical abstraction of a thread of control is captured by an instance of the System.Threading.Thread object in the class library. Classes beginning with the string "System.Threading" (see the .NET Framework Standard Library Annotated Reference) provide much of the user-visible support for this abstraction. To create consistency across threads of execution, the CLI provides the following mechanisms:
Acquiring a lock (System.Threading.Monitor.Enter or entering a synchronized method) shall implicitly perform a volatile read operation, and releasing a lock (System.Threading.Monitor.Exit or leaving a synchronized method) shall implicitly perform a volatile write operation. See Partition I, section 12.6.7. 12.6.6 Atomic Reads and WritesA conforming CLI shall guarantee that read and write access to properly aligned memory locations no larger than the native word size (the size of type native int) is atomic (see Partition I, section 12.6.2). Atomic writes shall alter no bits other than those written. Unless explicit layout control (see Partition II, Controlling Instance Layout [section 9.7]) is used to alter the default behavior, data elements no larger than the natural word size (the size of a native int) shall be properly aligned. Object references shall be treated as though they are stored in the native word size. NOTE There is no guarantee about atomic update (read-modify-write) of memory, except for methods provided for that purpose as part of the class library (see the .NET Framework Standard Library Annotated Reference). An atomic write of a "small data item" (an item no larger than the native word size) is required to do an atomic read/write/modify on hardware that does not support direct writes to small data items. NOTE There is no guaranteed atomic access to 8-byte data when the size of a native int is 32 bits, even though some implementations may perform atomic operations when the data is aligned on an 8-byte boundary. 12.6.7 Volatile Reads and WritesThe volatile. prefix on certain instructions shall guarantee cross-thread memory ordering rules. They do not provide atomicity, other than that guaranteed by the specification of Partition I, section 12.6.6. A volatile read has "acquire semantics," meaning that the read is guaranteed to occur prior to any references to memory that occur after the read instruction in the CIL instruction sequence. A volatile write has "release semantics," meaning that the write is guaranteed to happen after any memory references prior to the write instruction in the CIL instruction sequence. A conforming implementation of the CLI shall guarantee this semantics of volatile operations. This ensures that all threads will observe volatile writes performed by any other thread in the order they were performed. But a conforming implementation is not required to provide a single total ordering of volatile writes as seen from all threads of execution.
An optimizing compiler that converts CIL to native code shall not remove any volatile operation, nor may it coalesce multiple volatile operations into a single operation. RATIONALE One traditional use of volatile operations is to model hardware registers that are visible through direct memory access. In these cases, removing or coalescing the operations may change the behavior of the program. NOTE An optimizing compiler from CIL to native code is permitted to reorder code, provided that it guarantees both the single-thread semantics described in Partition I, section 12.6 and the cross-thread semantics of volatile operations. 12.6.8 Other Memory Model IssuesAll memory allocated for static variables (other than those assigned RVAs within a PE file; see Partition II) and objects shall be zeroed before they are made visible to any user code. A conforming implementation of the CLI shall ensure that, even in a multi-threaded environment and without proper user synchronization, objects are allocated in a manner that prevents unauthorized memory access and prevents illegal operations from occurring. In particular, on multi-processor memory systems where explicit synchronization is required to ensure that all relevant data structures are visible (for example, vtable pointers) the VES shall be responsible for either enforcing this synchronization automatically or for converting errors due to lack of synchronization into non-fatal, non-corrupting, user-visible exceptions. It is explicitly not a requirement that a conforming implementation of the CLI guarantee that all state updates performed within a constructor be uniformly visible before the constructor completes. CIL generators may ensure this requirement themselves by inserting appropriate calls to the memory barrier or volatile write instructions. |

EAN: N/A
Pages: 121