Availability
Introduction
The main technique for increasing the availability of an site is to add redundant components. These redundant components can be used to create multiple communications paths, multiple servers that offer the same service, and standby servers that take over in the event of a server failure.
Consider Figure A.11, which shows a medium-sized site with some redundancy, and Figure A.12, which illustrates a large site with full redundancy.
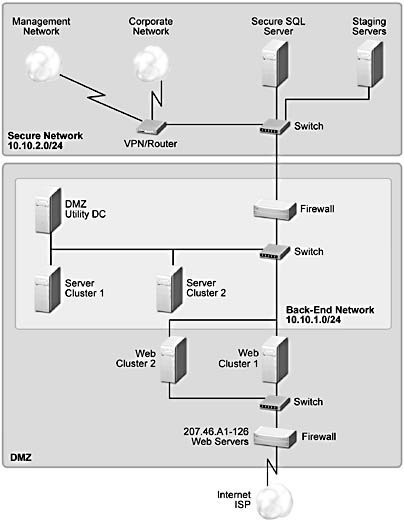
Figure A.11 A medium-sized site with some redundancy
In Figure A.11, we have two Web clusters, each with multiple servers, and we have two server clusters, each of which is configured as a failover cluster using Microsoft Cluster Services. We discuss these basic building blocks for increasing the availability of services in the following sections.
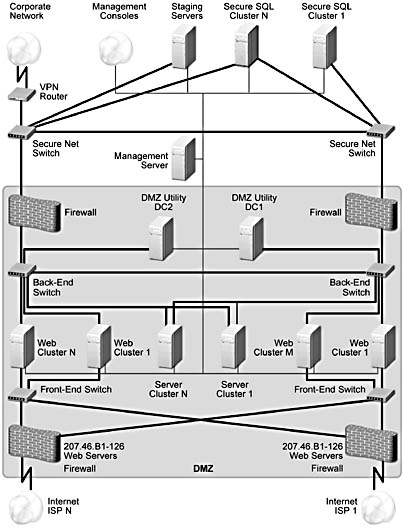
Figure A.12 A large site with complete redundancy
In a large site with complete redundancy, such as the one illustrated in Figure A.12, not only are there multiple Web clusters, but each server is also configured as a failover cluster using Microsoft Cluster Services. In addition, there are connections to multiple ISPs and a separate management network.
Availability of Front-End Systems
The cloning technique, described previously in "Scalability," when coupled with NLBS load balancing and the use of stateless web servers can be used to provide very highly available front-end Web servers. When multiple NLBS Web clusters are configured with round-robin DNS, as described previously, it is possible to make the Web servers resilient to networking infrastructure failures as well.
The basic idea is exactly as described in "Scalability," with the additional requirement that when a clone fails, or a Web server running on the clone stops responding, the load-balancing system must remove the clone from the Web cluster until it is repaired. NLBS automatically keeps track of the operating members of the Web cluster and regroups when one fails. When the IIS Web server fails on Windows 2000, it restarts automatically. However, when the IIS Web server hangs, it must be detected with a monitoring tool. Microsoft's HTTPMon or a third-party tool such as NetIQ (http://www.netiq.com/) can be scripted to do this.
Availability of the Networking Infrastructure
It is critical that the networking infrastructure and the connectivity of the site to the Internet are continuously available. As shown in the example site, the first important technique is to have multiple connections to the Internet using multiple ISPs. Connections should be diverse; that is, communication facilities should take physically separate paths from the provider to the customer's premises. This eliminates failure of the site due to a cut cable—not an uncommon occurrence.
For the highest availability, diverse power and redundant uninterruptible power sources should also be considered. Diversity in the infrastructure is often one of the major attractions of hosting a site at a facility dedicated to offering a hosting service collocated with multiple ISPs.
Within the site, switches and routers should be interconnected in such a way that there are always multiple paths to each service. Finally, a separate management network and an out-of-band network, as described in the "Management and Operations" section later in the chapter, are important for being able to manage performance and recover functions even in the face of various network infrastructure failures.
Availability of Back-End Systems
Back-end systems can be made highly available by clustering them using Microsoft Cluster Services, a core technology that provides redundancy at the data layer and failover capability for services running on the cluster. Microsoft Cluster Services enables multiple SQL databases and file shares to share a RAID device, so if a primary file or database server fails, a backup comes online automatically to take its place. Like NLBS, no specific programming is required to take advantage of this system-level service.
The data for both the database and the Web content needs to be further protected by being stored on a RAID disk array. In the event that a hard disk fails, the data will continue to be available, and a functioning hard disk can be hot-swapped into the array with no interruption in service.
The back-end servers send periodic messages, called heartbeats, to each other to detect failed applications or servers. The heartbeats are sent on a dedicated network (shown as the cluster heartbeat network), using NICs dedicated to this purpose. In the event that one server detects a heartbeat network communication failure, it requests verification of the cluster state. If the other server does not respond, it automatically transfers ownership of resources (such as disk drives and IP addresses) from a failed server to a surviving server. It then restarts the failed server's workload on the surviving server. If an individual application fails (but the server does not), Microsoft Cluster Services will typically try to restart the application on the same server. If that fails, Microsoft Cluster Services moves the application's resources and restarts them on the other server.
EAN: N/A
Pages: 183