7.3 System tuning
|
| < Day Day Up > |
|
7.2 Application tuning
Tuning the DB2 UDB server is very important to achieve the performance goal. Well-designed databases and a performance-optimized application play a major role in reaching the performance tuning goal. From our experiences, very often the application or the database design are the reasons for a performance problem. In this section we discuss, from a performance-tuning point of view, some major topics and the best practices for database design and what to keep in mind when developing an application. Performance tuning is an on-going task. These guidelines are also applicable for database and application tuning once the application is in production.
7.2.1 Database design
Before you start the database design, you need to understand application requirements and performance goals. The database logical and physical design, database server system resource needed will be based on the application requirement and performance goal. If you can request the system you need, examine the performance requirement carefully and order hardware with enough capacity. If you are given a system, check if the system has enough capacity to meet the performance goal.
Often the database server resides on a separate server. In this case, you can use all the resources available. You will have to share the resources with the application if you have a single server containing the application and database server. The recommendation is to have a separate server for DB2 UDB when having an environment including WebSphere application server.
Gather the information
To gather the application requirements for setting up a database, you should look for the following items:
-
How many users will connect to DB2 UDB? This number may be different from the number of real users when using connection pooling. The more connections you have the more memory is necessary.
-
How many instances/databases will be on the system? The configuration is different when more than one instances/databases are on the server. So you have to think about how many instances to create and where to put the databases.
-
How big is the volume of the data?
Consider the following resources for DB2 UDB database server:
-
CPU: How many and what speed?
It is better to have more than one CPU to allow parallel processing. The speed of the CPU is necessary for the optimizer. During installation, DB2 UDB will measure the speed. Any change afterwards need to be configured in the DBM CFG.
-
Memory: How much is available or required (if one machine, how much available for DB2)?
You need to know how much memory is available when configuring the database server.
-
Disks: What kind of storage and how many disks?
How the data is stored is important and only one disk will slow down the system because I/O will become the bottleneck. Many disks allow parallel processing.
You should consider the performance from the very beginning on both logical and physical database design. There is a lot of literature available that covers the database design theory. We cannot discuss them one by one but we provide information here to give you a basic understanding of this topic.
Logical database design
DB2 UDB is a relational database server. A relation can be displayed as a table with two dimensions. The first dimension is the fields of the table, while the second dimension is the values. Each field has a data type. The data types of DB2 UDB are described in "Data types" on page 67.
Data types
Data types should be defined to minimize disk storage consumption, and any unnecessary processing, such as data type transformations. The following are some of the main recommendations as they apply to the choice of data types required by the application:
-
Use SMALLINT rather than INTEGER if SMALLINT can contain the size of the number.
-
Use the DATE and TIME data types rather than CHAR for data/time data.
-
Use NOT NULL for columns wherever possible.
-
Choose data types that can be processed most efficiently.
-
Use CHAR rather than VARCHAR for any narrow columns (for example, those that are less than 50 characters wide).
-
Choose VARCHAR instead of LONG VARCHAR when the row size is less than 32 K.
-
Use FLOAT rather than DECIMAL if exact precision is not required.
-
Use IDENTITY columns where appropriate.
Normalization
An important thing in designing tables is to use normalization. There are several level of normalization to guarantee consistency of the data and to reduce redundant data. Figure 7-5 shows how tables get normalized and denormalized. In general normalization means more tables with less columns, and denormalization vice versa.
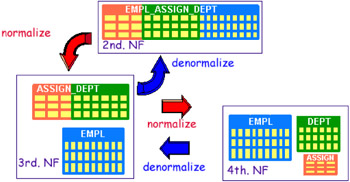
Figure 7-5: Normalization and denormalization
The level most often used is called the third normal form. For performance reasons, sometimes it makes sense to have some data redundancy to speed up access, especially in Data Warehouses where only read accesses occur. Redundant data has the following characteristics:
-
More disk space is needed.
-
More network traffic and memory usage when inserting data.
-
Data can become inconsistent because of failure during insert or update.
-
When redundant data gets updated all occurrences need an update.
-
Can be faster for accessing data because less optimization is needed and data can be accessed with less read operations.
Once the tables are normalized, you should consider defining constraints and primary keys to let DB2 UDB take care of data consistency. The constraint is a relation put in place between two tables and is one of the good practices in database design. We do not discuss this topic here because it is not a performance factor.
Index
Indexes are important for a good performance and we will cover them in more detail during the system tuning discussion. The need of indexes can be seen when you designed the application. In general this task is performed by the DBA. Some considerations should be taken into account during the design:
-
Define primary keys and unique keys, wherever possible, by using the CREATE UNIQUE INDEX statement. That helps by avoiding some sorts.
-
To improve join performance with a multiple-column index, if you have more than one choice for the first key column, use the column most often specified with the "=" predicate or the column with the greatest number of distinct values as the first key.
-
To improve data retrieval, add INCLUDE columns to unique indexes. Good candidates are columns that:
-
Are accessed frequently and therefore would benefit from index-only access
-
Are not required to limit the range of index scans
-
Do not affect the ordering or uniqueness of the index key
-
The creation of indexes should be done by a DBA. The DBA can monitor the system to see if an index is necessary. DBA also has to decide where to put the index (when using DMS) and what buffer pool should be used. A good teaming between developer and DBA is the best way to find a solution with a good performance.
Physical database design
After specifying the logical database design the DBA has to think about the placement of the data. This includes understanding the files that will be created to support and manage the database, understanding how much space will be required to store the data, and determining how to use the table spaces that are required to store your data.
The data placement is also one of the performance considerations. Just think about a database that stores all the data on one physical disk. You can understand that there will be no chance to allow parallel processing and I/O will become the bottleneck in the system.
Buffer pool
The buffer pool is the memory area where DB2 UDB caches the data that are requested, updated or inserted by client applications. The reason for buffer pools is better performance, because the access to memory is much faster than to a disk. Therefore it is good for performance if you can keep as many as you can the data needed by the client applications in the memory. If the data requested by a client is not in the buffer pool it will be retrieved from disk into the buffer pool. If the buffer pool has no more space left, the data currently retrieved from disk will push some data out of the buffer pool.
Buffer pools are assigned to table spaces with a single buffer pool supporting one or more table spaces. This flexibility allows the database designer to group data table spaces and indexes table spaces into separate buffer pools (only with DMS possible, not with SMS), assign small lookup tables to a small buffer pool to keep the pages memory resident, maintain a separate buffer pool for the system catalog tables, etc. These techniques can minimize disk I/O by allowing better reuse of data from the buffer pool(s), which provides another mechanism to improve overall DB2 system performance.
Since the space for a buffer pool is allocated at database startup at the full amount of memory and pages cannot be shared between buffer pools, it is usually a good idea to start with a small amount of buffer pools. Upon further analysis and monitoring additional buffer pools may be added, but initially you should keep the number from one to three.
If the database server is "small," a single buffer pool is usually the most efficient choice. Large systems with applications utilizing dynamic SQL that may do table scans intermixed with index access usually benefit from multiple buffer pools by separating the indexes and data for frequently accessed tables. This configuration prevents a table scan from "flushing" the index pages from the buffer pool to make room for additional data pages. Since most table accesses are via an index, this will allow the index data to remain in the buffer pool (since it is sharing space with other index pages only, not data pages).
Fewer shared buffer pools allow for some margin of error in sizing, when multiple table spaces are sharing a buffer pool. If one table space is less used than initially thought, and another is more used, the overall buffer pool impact is easier to balance. Single table space buffer pools could waste server memory with little or no performance benefit to the database, if that table space is not frequently read by the application.
Buffer pool data page management
Pages in the buffer pool are either in use, dirty, or clean:
-
In-use pages are currently being read or updated. They can be read, but not updated, by other agents.
-
Dirty pages contain data that has been changed but has not yet been written to disk.
-
After a changed page is written to disk, it is clean but remains in the buffer pool until its space is needed for new pages. Clean pages can also be migrated to an associated extended storage cache, if one is defined.
When the percentage of space occupied by changed pages in the buffer pool exceeds the value specified by the CHNGPGS_THRESH configuration parameter, page-cleaner agents begin to write clean buffer pages to disk.
Page-cleaner agents
Page-cleaner agents perform I/O as background processes and allow applications to run faster because their agents can perform actual transaction work. Page-cleaner agents are sometimes referred to as asynchronous page cleaners or asynchronous buffer writers because they are not coordinated with the work of other agents and work only when required.
To improve performance in update-intensive workloads, configure more page-cleaner agents. Performance improves if more page-cleaner agents are available to write dirty pages to disk. This is also true when there are many data-page or index-page writes in relation to the number of asynchronous data-page or index-page writes.
Table spaces
For the physical design you have to decide whether to use DMS or SMS table spaces. The arguments for SMS are the ease of administration and that only the space needed becomes allocated. The administration is easier because you only need to tell DB2 UDB in which directory to store the data. The only time you need to worry about space for a SMS table space is when the device is full. Especially if the database temporarily needs a high amount of disk space, it makes sense to use SMS because the space is released after completion. With DMS table spaces the space is preallocated and will not increase automatically.
From the performance point of view we recommend DMS table spaces using raw devices. With this option DB2 UDB will handle the storage itself without the operating system and is able to store table data in contiguous pages on the disk. The operating system cannot assure this and the data could be fragmented, resulting in worse performance during read and write operations.
With DMS table spaces it is possible to separate the index data and long data from the regular table data. Using this feature can result in better performance. If the index data and the regular data get stored in separated table spaces it is, for example, possible to assign a separate buffer pool for the index data to have the index resident in memory.
By default DB2 uses three SMS table spaces. One is to store the system catalog, one is for temporarily needed space (during a sort, for example), and one is for the user data. The output of DB2 LIST TABLESPACES is shown in Example 7-7.
Example 7-7: Default table spaces
Tablespaces for Current Database Tablespace ID = 0 Name = SYSCATSPACE Type = System managed space Contents = Any data State = 0x0000 Detailed explanation: Normal Tablespace ID = 1 Name = TEMPSPACE1 Type = System managed space Contents = System Temporary data State = 0x0000 Detailed explanation: Normal Tablespace ID = 2 Name = USERSPACE1 Type = System managed space Contents = Any data State = 0x0000 Detailed explanation: Normal
Two key factors must be considered when designing SMS table spaces:
-
Containers for the table space: When specifying the number of containers for the table space, it is very important to identify all the containers required up front, since containers cannot be added or deleted after the SMS table space has been created. Each container used for an SMS table space identifies an absolute or relative directory name. Each of these directories can be located on a different file system (or physical disk).
-
Extent size for the table space: The extent size can only be specified when the table space is created. Because it cannot be changed later, it is important to select an appropriate value for the extent size, as described in "Tablespaces and container" on page 61.
To calculate the optimal size for the table space extent, you should calculate the row length of the tables within the table space and determine how many rows will fit on each data page (remember there is a maximum of 255 rows per page) and how rows will fill up the selected extent size (number of rows per page x extent size). Then the update/insert activity of the tables must be estimated to determine how often an extent will be filled. For example, if you assume the default extent size of 32 pages, and a particular table row length allows one hundred (100) rows per page, it would take 3200 rows of data to fill an extent. If this particular table had a transaction rate of 6000 rows per hour, it would take roughly one half-hour to fill the extent. Therefore, the default extent size of 32 would be adequate for this table. Generally, the default extent size of 32 has been shown to be the optimal extent size through numerous DB2 UDB benchmark tests. The only time that the extent size should be set differently is if the extent size is too small and will fill up every several minutes. This would cause the database manager to allocate an additional extent every few minutes, and since there is some overhead involved in the extent allocation process, this could impact overall database performance.
When choosing an extent size, if it is difficult to determine which of two extent sizes is best (for example, 16 and 32), it is better to choose the larger extent size. If an extent size is too large, the worst scenario is that part of the last extent for the table is unused (that is, the table is very small, just 40 rows of 50 bytes each). If an extent size is too small, the database manager will have to allocate new extents frequently, which could cause a performance impact.
Using DMS table spaces makes it necessary to think about sizing because you have to pre-allocate the space for DMS table spaces. From the Control Center you can access, for example, a table and right click it. From the pop-up menu chose ESTIMATE SIZE... to estimate the size of the table and the indexes by entering the expected row count. That helps you to decide how much space is needed. It is also helpful for choosing the right page size.
By default, the page size is 4 KB. Each page (regardless of page size) contains 68 bytes of overhead for the database manager. This leaves 4028 bytes to hold user data (or rows), although no row on a 4-KB page can exceed 4005 bytes in length. A row will not span multiple pages. You can have a maximum of 500 columns when using a 4-KB page size.
If you have rows that need more space, DB2 UDB offers the ability to create table spaces with page sizes of 8 KB, 16 KB or 32 KB. The maximum row sizes for these page sizes are:
-
8 KB: Up to 8101 bytes
-
16 KB: Up to 26293 bytes
-
32 KB: Up to 32677 bytes
A buffer pool assigned to a table space must have the same page size. During installation a small buffer pool of each page size is created that cannot be seen and is not big enough for supporting a table space. It is possible to use the same buffer pool for each table space, but when you have tables that are more frequently accessed than others it may be useful to use a separate buffer pool to have much of the data resident in the memory. Or if you have a large table that is not as frequently accessed you can assign a small buffer pool to the table space where the table is located because it is no problem when this data is not present in the memory.
If you have only one large table in a tablespace it might be useful to use a bigger page size for the tablespace because the bigger the page size the more data a table can contain. When using small and large tables within one tablespace use the smallest page size fitting your large tables. For small tables use a 4-KB page size to not waste memory, as described in the following note.
| Note | There is a maximum of 255 rows per page. If the row size is smaller than the page size divided by 255, space is wasted on each page. |
Refer to Chapter 5, "Physical Database Design", in the manual IBM DB2 Universal Database Administration Guide: Planning, SC09-4822, for a complete description.
As you can see from Example 7-7 on page 260, DB2 UDB creates, by default, a system temporary table space. This table space is used to store internal temporary data required during SQL operations such as sorting, reorganizing tables, creating indexes, and joining tables. Although you can create any number of system temporary table spaces, it is recommended that you create only one, using the page size that the majority of your tables use.
User temporary table spaces are used to store declared global temporary tables that store application temporary data. User temporary table spaces are not created by default at database creation time.
Separating an index from the data makes sense if you have a table with many columns that is frequently accessed and has many rows. In this case the tablespace for the indexes can have a separate buffer pool to make the most of the index pages resident in memory. Think about the feature of putting additional columns on the index to avoid accessing the table.
Figure 7-6 shows an example of how table space can be arranged.
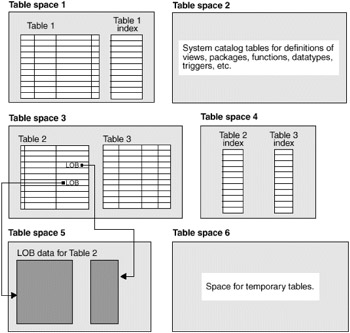
Figure 7-6: Table spaces
Container
Table spaces are a logical view while a container is a physical storage device. Each table space has at least one container and a container can belong only to one table space. When using more than one container per table space, DB2 UDB uses a striping mechanism to distribute the data across the containers.
If you have several disks then create the containers for a tablespace on different disks to allow parallel processing. We recommend using striped devices like RAID systems, because a RAID system is already striped. It is recommended to use only one container per tablespace. If you use a RAID system you have to set the registration variable DB_PARALLEL_IO=* to allow parallel data access from all tablespaces. The size of an extent should be a multiple of the RAID stripe size. The prefetch size should be a multiple of the extent size and a multiple of the RAID stripe size multiplied by the count of devices.
For the physical design it is also important to think about the location of the log files. Because any change to the data is written to the log files, the number of I/Os on these files is high. It is a good practice to have a different disk on which to put the logs. If you have to use any disk for your data, use the disk with the lowest I/O for the log files.
The path to the log files is stored in the database configuration. Use the command DB2 GET DB CFG and look for PATH TO LOGFILE. To change the path, update the NEWLOGPATH parameter in the database configuration. The new setting does not become the value of logpath until both of the following occur:
-
The database is in a consistent state, as indicated by the DATABASE_CONSISTENT parameter from the output of DB2 GET DB CFG.
-
All users are disconnected from the database.
When the first new connection is made to the database, the database manager will move the logs to the new location specified by logpath.
A set of system catalog tables is created and maintained for each database. These tables contain information about the definitions of the database objects (for example, tables, views, indexes, and packages), and security information about the type of access that users have to these objects. These tables are stored in the SYSCATSPACE table space.
| Note | The catalog tables are flagrantly accessed and it is recommended to use a separate disk or a disk with less activity for the SYSCATSPACE. |
7.2.2 SQL tuning
The next step is implementing the application. SQL is the language to speak with relational databases like DB2 UDB. It is used to select, insert and update the data. DB2 UDB uses an SQL compiler to produce an access plan. Figure 7-7 shows the steps for the SQL compiler.
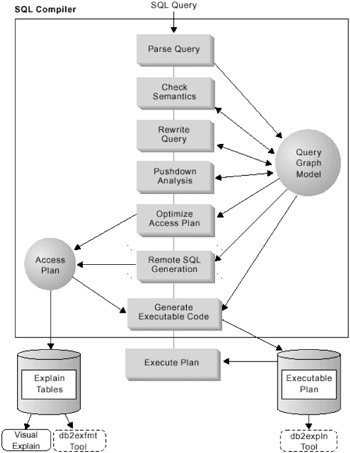
Figure 7-7: Steps of the SQL compiler
Like every compiler the SQL compiler checks the syntax and the semantic first. If one of the checks fails an error will be returned to the application. If these checks are passed the compiler tries to rewrite the statement if necessary. The compiler uses the global semantics stored in the query graph model to transform the query into a form that can be optimized more easily and stores the result in the query graph model.
The next step is to optimize the query. How intensive the optimizations will be is configurable. More details are in "Explain utilities" on page 250.
Static/dynamic SQL
With DB2 UDB you have the ability to use static SQL or dynamic SQL. The difference is that static SQL uses a precalculated access plan. This allows faster access because there is no need to optimize the query every time. So if you look at Figure 7-7 you see a process that needs to be done every time a dynamic SQL statement requests data from the server. For static SQL statements this step is done only once at creation time. But you need to rebind the code every time the conditions change and the optimizer might find another access plan. Do a rebind after:
-
The package is marked as invalid.
-
An index was created or removed.
-
The statistics of the tables used in the statement became updated.
-
A fix pack was installed.
Efficient SELECT statements
Also, the optimizer is able to optimize the select statement. You have to take care of the following points that the optimizer could not do for you:
-
Specify only the columns needed. Unnecessary columns will waste CPU cycles and slow down the network traffic.
-
Avoid selecting more rows than needed by specifying all applicable predicates in the query, to reduce the answer set to a minimum. Do not discard rows in your application code, let DB2 do it for you.
-
When the number of rows you need is significantly less than the total number of rows that might be returned, specify the OPTIMIZE FOR clause.
-
Use the FOR READ ONLY or FOR FETCH ONLY clause to avoid exclusive lock and to take advantage of row blocking.
-
Use the FOR UPDATE OF clause for update cursors to prevent deadlocks.
-
Avoid numeric data type conversion whenever possible.
-
Use operations like DISTINCT and ORDER BY only if needed. Sorting is very CPU intensive. If the order of the result set is insignificant, do not order it.
-
Use COUNT(*) FROM only when needed.
-
Use WHERE COL1 IN (1,2,5) instead of WHERE COL1= 1 OR COL1 = 2 OR COL1 = 5.
-
Do not use user-defined functions in join conditions. If you need a function in a join condition then create a view with an additional field including the UDF and join the view with the other table.
It is a good practice to use the same code page on both the client and the server site because the conversion of data types slows down the application. Character conversion occurs in the following circumstances:
-
When a client or application runs in a code page that is different from the code page of the database that it accesses.
The conversion occurs on the database server machine that receives the data. If the database server receives the data, character conversion is from the application code page to the database code page. If the application machine receives the data, conversion is from the database code page to the application code page.
-
When a client or application that imports or loads a file runs in a code page different from the file being imported or loaded.
7.2.3 Stored procedures
Stored Procedures (SPs) are programs running in the database environment. SPs can be written in SQL, C and Java and help to reduce the network traffic. In any case, procedures are typically written to contain multiple SQL data manipulation language (DML) statements as well as procedure logic constructs such as loops and if/else statements. Therefore, stored procedures are conceptually similar to "small" applications, providing useful, database-intensive business service to multiple applications. These applications, which typically are remote from DBMS itself, invoke the procedure with a single call statement.
Stored procedures can require parameters for input (IN), output (OUT), or input and output (INOUT). They may return one or more sets of results.
Keep in mind that calling a SP has an overhead and it should be clear that it makes no sense to have a single statement inside the SP. The benefit arises if the network traffic reduces significantly. This can be the case if the SP includes several SQL statements, especially when the result set of the SP is smaller than the result set that the SP itself has to handle, or if the SP has loops including SQL statements.
FENCED vs. NOT FENCED - Security vs. performance
A stored procedure can run in two modes, FENCED and NOT FENCED. A SP running in a fenced mode uses a different address space than the database server, while a not fenced SP runs in the same process as the database manager. We recommend using FENCED SPs only because an error in a NOT FENCED SP can accidentally or maliciously corrupt the database or damage the database control structure.
The benefit of a NOT FENCED SP is the better performance. So for performance reasons it might be useful to use a SP NOT FENCED, but again it is a high risk. Use the SP as a FENCED one first and later, if you know that the SP runs stably and has no errors, create the SP in a NOT FENCED mode.
Java routines
For Java routines running on UNIX platforms, scalability may be an issue if NOT FENCED is specified. This is due to the nature of the DB2 UNIX process model, which is one process per agent. As a result, each invocation of a NOT FENCED Java routine will require its own JVM. This can result in poor scalability, because JVMs have a large memory footprint. Many invocations of NOT FENCED routines on a UNIX-based DB2 server will use a significant portion of system memory.
This is not the case for Java routines running on Windows NT and Windows 2000, where each DB2 agent is represented by a thread in a process shared with other DB2 agent threads. This model is scalable, as a single JVM is shared among all the DB2 agent threads in the process.
If you intend to run a Java routine with large memory requirements, it is recommended that you register it as FENCED NOT THREADSAFE. For FENCED THREADSAFE Java routine invocations, DB2 attempts to choose a threaded Java fenced mode process with a Java heap that is large enough to run the routine. Failure to isolate large heap consumers in their own process may result in out of Java heap errors in multi-threaded Java db2fmp processes. If your Java routine does not fall into this category, FENCED routines will run better in thread safe mode where they can share a small number of JVMs.
C/C++ routines
C or C++ routines are generally faster than Java routines, but are more prone to errors, memory corruption, and crashing. For these reasons, the ability to perform memory operations makes C or C++ routines risky candidates for THREADSAFE or NOT FENCED mode registration. These risks can be mitigated by adhering to programming practices for secure routines (see the topic "Security Considerations for Routines" in the DB2 Information Center), and thoroughly testing your routine.
SQL-bodied routines
SQL-bodied routines are also generally faster than Java routines, and usually share comparable performance with C routines. SQL routines always run in NOT FENCED mode, providing a further performance benefit over external routines.
| Note | For creating SQL Stored Procedures you need a C-Compiler. For further details have a look at Cross-Platform DB2 Procedures: Building and Debugging. |
7.2.4 Declared global temporary tables
The DECLARE GLOBAL TEMPORARY TABLE statement defines a temporary table for the current session. The benefit of temporary tables is that their description does not appear in the system catalog and that any action on them is not logged. A temporary table consists only as long as the session exists that created it. So if the session terminates the temporary is gone.
For some circumstances temporary tables are very helpful and in some case they can become very big. With DB2 UDB Version 8 it is now possible to optimize the access to the data in temporary tables because it is now possible to create indexes and update the statistics on them. With these options the temporary tables are now much more powerful than in former versions.
So think about a very large temporary table in your system. Every time you need some data from that table a tablescan on this temporary table is necessary. With an index and with statistical data it is now possible to have the same performance as with regular tables.
7.2.5 Concurrency
When designing applications it is important to think about concurrency. There is a need to balance between the requirement of the application for consistency when accessing data and the impact of performance when the isolation level is set too high.
Generally, in a production environment, DBA is the one that binds the system utilities like CLI, etc. Therefore, DBA will set the default isolation level for applications that use those utilities. In order to set a proper default isolation level, DBA should understand the applications running on the server. A good communication between DBA and the application designer/programmer is necessary. More important is that developer should always explicitly set the isolation best suit for the application.
Isolation level
DB2 UDB offers four isolation levels: Repeatable read (RR), read stability (RS), cursor stability (CS) and uncommitted read (UR). Each of these isolation levels allows the user and application to control the number and duration of read (Share) locks held within a unit of work. By setting the appropriate isolation level based on a particular application's requirement, lock resources can be minimized and user concurrency (application's tendency to multiple users) can be increased as much as possible for a particular application. Each of the isolation levels and their definitions, along with a brief example, is shown in the Table 7-2 on page 271 (highest to lowest locking impact). The example is based on the following information:
-
A table (EMPLOYEES) that contains a column LAST_NAME with the following values:
ARNOLD, BLACK, BROWN, BRUEGGEMAN, BRUTY, HANCOCK, HURT, JAYNE, JONES, LAW, MORGAN, NOBLES,NOVACEK, OATES, STAUSKAS, TOBIAS
The table has no index on LAST_NAME.
-
The SQL query being executed is:
SELECT LAST_NAME, EMPLOYEE_NUMBER FROM A.EMPLOYEES WHERE LAST_NAME LIKE 'B%'
| Isolation level | Brief description | Example that illustrates impact on Share (read) locking |
|---|---|---|
| Repeatable Read (RR) | Repeatable Read means that the same query can be executed multiple times within the same unit-of-work and the results of the query will be identical every time (repeatable). A Share lock will be held on each row and examined during the execution of a SQL statement (for table scans, this would encompass each row within the table). | A Share lock would be held on every row within the table for the entire unit-of-work, effectively preventing updates (X locks) from occurring until this SQL statement is committed. |
| Read Stability (RS) | Read Stability means that the same query will return the same base set of information each time the query is executed in a unit-of-work, but additional rows may be included with each subsequent execution. A Share lock will be held on every row that satisfies the result set of the query (that is, is part of the answer), | A Share lock would be held on the rows containing BLACK, BROWN, BRUEGGEMAN and BRUTY, but all other rows could be available for update and read. |
| Cursor Stability (CS) | Cursor Stability means that the data is repeatable on the current position of the cursor only. Previously read rows or to-be-read rows will allow updates and/or reads. A Share lock will be held on the current position of the cursor only. | A Share lock would be held on the rows containing BLACH, BROWN, BRUEGGEMAN and BRUTY, but only when the cursor was positioned on that row. After the cursor is repositioned, the row is eligible for read and/or update by another user. |
| Uncommitted Read (UR) | Uncommitted Read means that no Share locks are held on any row by this query, and updates can take place as well. Only super exclusive (Z) locks prevent UR queries. No Shared locks are held at all. | No locks would be held on any rows of the table and the data could be in the process of being changed as it is read. |
In looking at the isolation levels and their descriptions, it is easy to see that using an unnecessary isolation level (too high a locking impact) will impact performance of a database environment that supports both database read and write transactions. A good rule to go by in selecting the isolation level is to use the lowest locking level that will support the application requirements. For some reporting applications, if the answer set does not have to be exact (but rather an approximation), UR might be the proper isolation level. There are actually very few instances where the RR isolation level is required, and the application requirements should be verified to confirm that RR isolation is necessary (due to the potential for lock waits and lock escalation).
Locking options
DB2 UDB offers options in the area of locking to reduce DB2 UDB resource consumption for the lock list memory area and reduce the chance of lock escalation for the entire database or an individual database agent. The LOCKSIZE of the table can be changed from the default of row level locking to table level locking via the ALTER TABLE statement. This will allow read-only tables to hold less DB2 UDB lock resources (as Share locks behave the same at the table or row level) due to the fact that one lock (at the table level) is all that will be required on the table. Depending on the isolation level setting, this can reduce the memory consumption within the lock list considerably.
Another locking option to perform essentially the same function of reducing the memory consumption within the lock list focuses on the application level by providing the LOCK TABLE statement. This statement can be issued by an application process or user to lock a table in either Share or Exclusive (X) mode. The use of this option allows locks to be reduced for a single application task or process, and will prevent other applications or tasks from accessing the table at all (through the use of Exclusive (X) mode).
Careful consideration should be given to the database usage requirements and application design before either of these locking options should be utilized. Since the lock granularity is at the table level, this type of locking strategy can have a major impact on overall database performance, if it is utilized in an inappropriate situation.
|
| < Day Day Up > |
|
EAN: N/A
Pages: 90