International Features
Among the international features that Uniscribe provides are its support for typographic issues such as kerning, ligatures, combining marks and character reordering. As you will see in the following sections, it also handles right-to-left (RTL) and left-to-right (LTR) reading order, the many-to-many relationship that exists between characters and glyphs, and finally, caret placement.
Kerning
One typographic issue that Uniscribe handles is kerning. Every glyph in a font is designed with an advance width. This advance width should allow glyphs that are placed adjacent to each other to look as though they are uniform in density, and each glyph should appear distinct. The designer must consider every possible glyph pair and adjust each glyph's advance width-in a process called "kerning"-to achieve the best effect in the most common cases, and acceptable results in the most difficult cases.
Difficult cases occur when the shape of the adjacent sides of a pair of glyphs makes the glyphs appear either too close together or too far apart. An example of problematic spacing is the letter pair "AV." The normal spacing for this pair is too wide because the slopes of the "A" and "V" are identical, leaving too much white. (See Table 24-2.)
Table 24-2 Examples of standard spacing and kerning.
| Standard spacing | |
| With kern feature applied | |
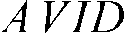
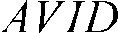
The advance-width adjustment is provided by the font designer in the font's Glyph Positioning (GPOS) OpenType table. When you use Uniscribe to display text, kerning specified by a font's GPOS table is applied automatically.
Ligatures
In addition to kerning, a second typographic issue that Uniscribe addresses is ligatures, which are used in most scripts. Combination glyphs such as "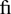 " are referred to as "ligatures," reflecting the fact that they are composed from separate glyphs that are tied or bound together. In English, the most common purpose of ligatures is to improve legibility. For instance, character combinations like "fi" can look amiss, because the dot on the "i" meshes with the overhanging top of the "f." Therefore, most English fonts supply a separate glyph for the "
" are referred to as "ligatures," reflecting the fact that they are composed from separate glyphs that are tied or bound together. In English, the most common purpose of ligatures is to improve legibility. For instance, character combinations like "fi" can look amiss, because the dot on the "i" meshes with the overhanging top of the "f." Therefore, most English fonts supply a separate glyph for the "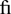 " combination. Compare the word "fit" in Table 24-3 with and without the "fi" ligature glyph.
" combination. Compare the word "fit" in Table 24-3 with and without the "fi" ligature glyph.
Table 24-3 Comparison of the "fi" character combination, with and without the "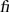 " ligature glyph.
" ligature glyph.
| | |
| Using separate "f" and "i" glyphs | Using the " |
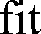
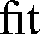
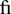 " ligature glyph
" ligature glyphUnicode includes separate code points for a few ligatures simply because they were already coded in pre-existing character sets. Unicode does not, and will not, encode new ligature combinations as separate code points. Applications should not use the ligature code points since they break both search and sorting algorithms. Instead, "ligaturization" is a font feature provided in the Glyph Substitution (GSUB) tables of OpenType fonts. (For more information on GSUB tables, see Chapter 20.)
Fonts can also contain optional ligatures. For example, the Palatino font includes ligatures for "ft" and "st." (See Table 24-4.)
Table 24-4 Ligatures for "ft" and "st" in the Palatino font.
| | |
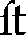
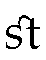
Such optional ligatures can be enabled by passing OpenType feature requests to the ScriptShape and ScriptPlace APIs. Many scripts use ligatures far more extensively than English does. Wherever a ligature is a standard part of the script, Uniscribe will apply it automatically. For example, the letters "lam" (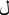 ), "meem" (
), "meem" (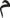 ), and "hah" (
), and "hah" (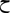 ) are displayed with a ligature in some Arabic fonts. (See Table 24-5.)
) are displayed with a ligature in some Arabic fonts. (See Table 24-5.)
Table 24-5 Example of a ligature in Simplified Arabic and Traditional Arabic fonts.
| Arabic Font | Ligature |
| Simplified Arabic | |
| Traditional Arabic | |
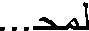
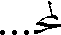
Note
Uniscribe will apply ligature and kerning features only where they are supplied in the fonts. Since this functionality has previously been available in only a handful of applications, few fonts include GPOS and GSUB tables at the time of this writing.
Combining Marks and Character Reordering
Another aspect of multilingual text involves combining marks, since they appear in most scripts. Once again, Uniscribe provides support for dealing with this typographic feature. Combining marks range from the accent marks utilized in Western Europe to the far more complex combinations found in Indic scripts, for example. While Unicode encodes many precomposed characters, it does not do so as a general rule. The number of combinations used internationally is far more than will fit conveniently in a 16- or 20-bit character set. Unicode encodes only those precomposed forms that were already encoded in previous character sets. In Table 24-6 involving Thai, notice how the base character can take one or two combining marks, and that the position of the combining mark used in the first example has changed in the second example.
Table 24-6 Thai base character and combining marks.
| |

In some scripts, combining marks can take up space beside the base character-to the left, to the right, or both. (See Table 24-7.)
Table 24-7 Positioning of combining marks in relation to the base character.
| Combining Character | Base Character | Description |
| | | Note that the combining vowel changes shape slightly, so that its hook lands on top of the stem of the base consonant. |
| | | Note that this combining vowel displays to the left of the consonant even though it is pronounced after the consonant, just as in the first example. |
| | | Note that this leading consonant is represented by the extra hook attached at the top of the consonant. |
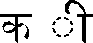
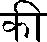
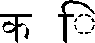

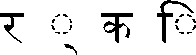

Table 24-7 also illustrates reordering and combining-the initial reph (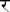 ) is joined to the syllable without an intervening vowel by the halant/virama (
) is joined to the syllable without an intervening vowel by the halant/virama (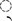 ). In this case, the representation for the reph is the combining hook at the top. Character reordering is script-specific and follows rules defined by Unicode.
). In this case, the representation for the reph is the combining hook at the top. Character reordering is script-specific and follows rules defined by Unicode.
RTL and LTR Reading Order
All Arabic and Hebrew scripts are written from right to left. However, numbers and certain other scripts are written from left to right even when part of Arabic or Hebrew text. When the reader encounters a direction boundary, the eye must skip to the far end of the reversed item (word or phrase) and read in the opposite direction.
Books that have a mixture of languages can be published with an overall LTR reading order (if the content is not predominantly Arabic or Hebrew), or with a RTL reading order (if the content is predominantly Arabic or Hebrew). The Unicode bidirectional algorithm provides a standard way to handle character ordering in the absence of higher level semantics. For example, the algorithm defines that a space inside a run of one direction has the same direction as the run; a space between runs of opposite direction takes the overall direction. (See Table 24-8.)
Table 24-8 Examples of LTR and RTL overall direction.
| LTR Overall Direction | | means good morning. |
| RTL Overall Direction | .means good morning | |
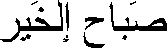
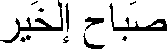
In looking at Table 24-8, there are several things you should notice. First, the final period is displayed at the logical end of the line. Second, the content of the LTR run and of the RTL run is unchanged. Third, the LTR run and the RTL run swap places.
Many-to-Many Relationship Between Characters and Glyphs
A corollary of supporting ligatures, combining marks, and character reordering is that there is a many-to-many relationship between characters and glyphs. The term "cluster" describes the shortest run of characters wholly represented by one or more glyphs. (For more information, see Chapter 5.) For example, the code point U+0061 ("a") followed by U+00E9 (" ") might be displayed as an "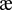 " ligature glyph and an acute accent glyph. In this case, the pair of code points would be considered as one cluster. Uniscribe can return a mapping table that points (lists the offset into the glyph array) to the first glyph that represents the cluster to which this code point belongs.
" ligature glyph and an acute accent glyph. In this case, the pair of code points would be considered as one cluster. Uniscribe can return a mapping table that points (lists the offset into the glyph array) to the first glyph that represents the cluster to which this code point belongs.
Caret Placement
A final typographic issue that Unicode handles is caret placement. Where should the editing caret appear when there are ligatures, combining marks, and character reordering? In some languages, the convention is that the caret is never placed inside a cluster. In other languages the caret is positioned proportionally through the cluster. Uniscribe provides APIs to retrieve the caret position associated with the leading and trailing edges of any character, and to identify the character edge nearest to any pixel offset. These APIs automatically take the script rules into account.
For scripts such as Thai and Devanagari, the caret is never placed inside a cluster. Uniscribe will snap pixel offsets to the nearest cluster boundary. For scripts such as Arabic and Hebrew, the caret advances through the cluster in proportion to the number of code points covered. Uniscribe will interpolate pixel offsets in a linear fashion.
In order to advance the caret to the correct position when the user presses the Arrow keys, Uniscribe provides the ScriptStringGetLogAttr and ScriptBreak APIs. These APIs return an array of flag bitsets, one per code point. One of the flags identifies code points in front of which the caret can validly sit.
EAN: 2147483647
Pages: 198