| Both the Tokenizer class in sjm.parse.tokens and StreamTokenizer in java.io use lookup tables to decide how to build a token. The classes are similar in that the first character of a token determines the tokenizer's state. The classes differ in that Tokenizer transfers control to a TokenizerState object, whereas the state of StreamTokenizer is internal to the StreamTokenizer class. Figure 9.5 shows the table that a default Tokenizer object uses to determine which state to use to build a token. Figure 9.5. This table depicts the default lookup table used by the class Tokenizer in sjm.parse.tokens to determine which TokenizerState can produce a Token . The Unicode value of each character is the sum of its row number value and column value, which appear in hexadecimal format. 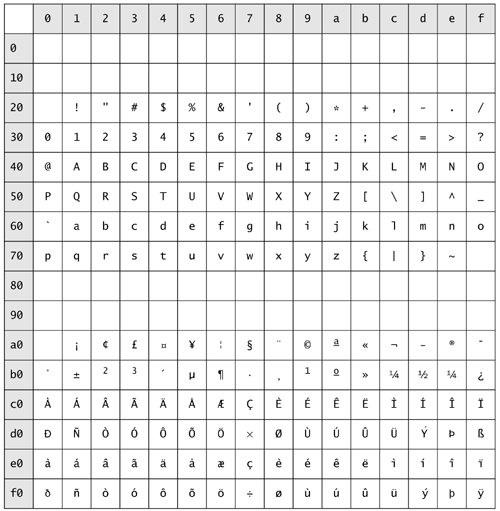 Figure 9.5 shows the Unicode encoding that maps numbers to characters. This encoding handles characters from most written languages. The Tokenizer class in sjm.parse.tokens , however, handles only the first 256 characters of Unicode. If you are working with languages other than English and the European languages, you may need to modify Tokenizer to handle a broader array of characters. See http://unicode.org/ for more information about Unicode. The sum of the encoding table's row and column labels indicates the numeric value, in hexadecimal (base 16), of each character. For example, row 40, column 1 contains A , meaning that 41 in hexadecimal format represents an A . There are several reasons for showing the numeric value of characters in base 16. First, there is some periodicity around the number 16 in the table, which shows the standard Unicode values of characters. For example, lowercase letters appear 32 positions after their uppercase counterparts. A deeper reason for showing character values in hexadecimal is that developers who work with characters at the low level required by tokenizers tend to acquire an understanding of exactly how the bits and bytes of characters translate into either numbers or text. A final reason for using hexadecimal is that Unicode escape sequences must appear in Java in hexadecimal format. Java lets you represent hexadecimal numbers by preceding them with 0x . For example, you can write the numeric value of A as 0x41 . Java also expects Unicode escape values to appear in hexadecimal, so the Unicode escape of A is \u0041 . Each of the following lines prints an A : System.out.println('A'); System.out.println((char) 0x41); System.out.println((char) 65); System.out.println("\u0041"); The casts to char are important because a char value prints as a character rather than as a number. A char is essentially an integer that knows how to print as a character. For this reason, you can use a char as an index into an array. The lookup table that Tokenizer objects use to determine which TokenizerState to use is an array. Its declaration is protected TokenizerState[] characterState = new TokenizerState[256]; The Tokenizer class provides access to this array through the method setCharacterState() , which takes two int arguments followed by a TokenizerState argument. The constructor for Tokenizer uses this method to set its default states. For example, the constructor includes the line // ... setCharacterState('0', '9', numberState()); // ... This statement in the constructor uses the method numberState() to access a default number-recognizing state, and it places this state in positions '0' through '9' of the lookup table. Here, the char values work as indexes, delineating locations 48 through 57 (or 0x30 through 0x39) of the array. The default states that Tokenizer uses are as follows : From To State 0 ' ' whitespaceState 'a' 'z' wordState 'A' 'Z' wordState 0xc0 0xff wordState '0' '9' numberState '-' '-' numberState '.' '.' numberState '"' '"' quoteState '\'' '\'' quoteState '/' '/' slashState For any index not in this list, such as '<' , a default Tokenizer uses a SymbolState object to consume a token. | 