| A tokenizer state is an object that can return a token from an input reader. The Tokenizer class in sjm.parse.tokens uses, by default, the classes that Figure 9.6 shows. Figure 9.6. The TokenizerState hierarchy. This diagram shows the hierarchy of TokenizerState in sjm.parse.tokens . A Tokenizer object can use these states to consume tokens from a string. 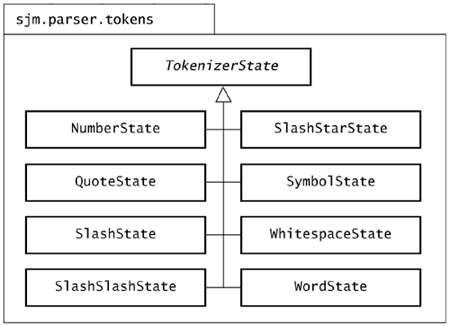 Each subclass implements the nextToken() method of the abstract class TokenizerState , which Figure 9.7 shows. Figure 9.7. The TokenizerState class. TokenizerState is an abstract class that defines the minimal behavior of an object that can read characters and build a corresponding Token object. 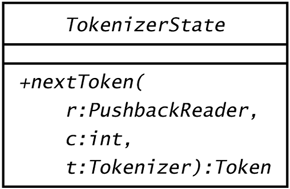 The PushbackReader is usually created in the Tokenizer constructor, although you can override this with the Tokenizer class's setReader() method. Section 9.8, "Setting a Tokenizer's Source," shows how. A PushbackReader object provides the ability to unread characters. This is especially useful when your parser is reading symbols; the tokenizer state may read several characters in pursuit of a long symbol and then must push them back if the entire symbol is not found. When the Tokenizer object is deciding which state to use, it looks at the next character of the input and uses this character as an index into the Tokenizer object's character table. Rather than push this back and let the state reread it, the Tokenizer object passes the character it reads to the TokenizerState object. The Tokenizer object also passes a copy of itself. This allows states to discard characters from the input and eventually call back the Tokenizer object to find the next token. Whitespace and comment states work this way. 9.7.1 QuoteState One of the simpler tokenizer states is QuoteState , which Figure 9.8 depicts. Figure 9.8. The QuoteState class. A QuoteState object reads characters until it matches the initial character c that it receives in nextToken() . 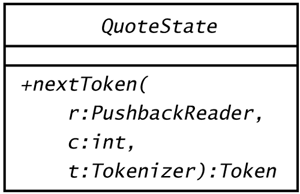 The method QuoteState.nextToken() reads characters until it finds a match for the initial character it receives as its int c argument, or until it finds the end of the string. Here is an example that tokenizes out quoted strings: package sjm.examples.tokens; import java.io.*; import sjm.parse.tokens.*; /** * This class demonstrates how <code>QuoteState</code> * works. */ public class ShowQuoteState { public static void main(String args[]) throws IOException { Tokenizer t = new Tokenizer( "Hamlet says #Alas, poor Yorick!# and " + "#To be, or not..."); t.setCharacterState('#', '#', t.quoteState()); while (true) { Token tok = t.nextToken(); if (tok.equals(Token.EOF)) { break; } System.out.println(tok); } } } This prints out: Hamlet says #Alas, poor Yorick!# and #To be, or not...# The main() method creates a Tokenizer , giving it a string to tokenize. Next, main() tells the tokenizer to enter a quote state when the tokenizer sees a " # " character. The main() method passes the tokenizer the tokenizer's own, default quote state object to use. The first time the tokenizer sees a " # ", it uses the quote state to read up to the next " # ", producing a token whose string is "Alas, poor Yorick!" Next, the tokenizer finds the word "and" amidst some whitespace, and then it finds another " # ". The tokenizer calls its QuoteState object a second time, and this time it consumes all the text up to the end of the string. Because there is no closing quote, the QuoteState object appends a quote symbol that matches the initial one. This ensures that quoted strings always appear between a pair of quote symbols. The QuoteState class's task of reading text until it matches a specific character is relatively simple. The only subtlety is that QuoteState must use some caution to make sure its buffer of characters is large enough. Here is the code in QuoteState.java : package sjm.parse.tokens; import java.io.*; /** * A quoteState returns a quoted string token from a reader. * This state will collect characters until it sees a match * to the character that the tokenizer used to switch to * this state. For example, if a tokenizer uses a double- * quote character to enter this state, then <code> * nextToken()</code> will search for another double-quote * until it finds one or finds the end of the reader. */ public class QuoteState extends TokenizerState { protected char charbuf[] = new char[16]; /* * Fatten up charbuf as necessary. */ protected void checkBufLength(int i) { if (i >= charbuf.length) { char nb[] = new char[charbuf.length * 2]; System.arraycopy(charbuf, 0, nb, 0, charbuf.length); charbuf = nb; } } /** * Return a quoted string token from a reader. This method * will collect characters until it sees a match to the * character that the tokenizer used to switch to this * state. */ public Token nextToken( PushbackReader r, int cin, Tokenizer t) throws IOException { int i = 0; charbuf[i++] = (char) cin; int c; do { c = r.read(); if (c < 0) { c = cin; } checkBufLength(i); charbuf[i++] = (char) c; }while (c != cin); String sval = String.copyValueOf(charbuf, 0, i); return new Token(Token.TT_QUOTED, sval, 0); } } This code performs its own memory management, expanding the size of charbuf as necessary. You could delegate this to an existing class, particularly StringBuffer . In fact, in Java 1.1.7, StringBuffer uses a memory management technique similar to the approach taken here. When tokenizing, however, you are concerned with efficiency and with the details of how characters become tokens, and tokenizers typically retain fine-grained control of this conversion. 9.7.2 NumberState A NumberState object builds a double value that corresponds to the digits and decimal point in a string of characters. It divides its task primarily into two parts : Read the number to the left of a decimal point, and read the remaining digits after the decimal point. This state also has to handle negative numbers and two special cases that result from reading only a minus sign and only a dot. Figure 9.9 shows the NumberState class. Figure 9.9. The NumberState class. A NumberState object builds a token that contains a number.  To construct a token, NumberState.nextToken() takes the following steps: -
Set the initial value of the number to . -
Note whether there is a minus sign. -
Absorb digits until there are no more. For each digit, multiply value by 10 and add the new digit. -
If the next character is a decimal point, again absorb digits until there are no more. For each digit, multiply value by 10 and add the new digit's value. Also keep track of a divisor, multiplying it by 10 for each digit. After consuming all remaining digits, divide value by this divisor. -
Negate value if the number began with a minus sign, and return value . Consider tokenizing the string "123.456" . A NumberState object sets value to and stores the initial character it receives from the Tokenizer in the variable c . Then the NumberState object consumes the digits up to the decimal point with the following code: /* * Convert a stream of digits into a number, making this * number a fraction if the boolean parameter is true. */ protected double absorbDigits( PushbackReader r, boolean fraction) throws IOException { int divideBy = 1; double v = 0; while ('0' <= c && c <= '9') { gotAdigit = true; v = v * 10 + (c - '0'); c = r.read(); if (fraction) { divideBy *= 10; } } if (fraction) { v = v / divideBy; } return v; } A NumberState object uses this method to absorb digits on both sides of a decimal point. If the object has seen a decimal point, then fraction is true. The NumberState object records, in gotADigit , that at least one digit appears in the number. This allows an evaluation method to recognize that a stand-alone " . " is a symbol and not a number. After reading the left side of the number, the NumberState object reuses the preceding logic to read the right side. After reading both sides of the number, the NumberState object unreads the last character it read and evaluates a token. The value of the token depends on whether the input string had a leading minus and whether it had any digits. If the input had no digits, the input is not a number at all, and the NumberState object passes control to a SymbolState object to create a symbol token. 9.7.3 SlashState By default, a Tokenizer passes read control to a SlashState object when the Tokenizer sees a " / " character. Incidentally, you can change this behavior by informing the Tokenizer object to treat the " / " as a symbol. For example, package sjm.examples.tokens; import java.io.*; import sjm.parse.tokens.*; /** * This class shows how to <i>not</i> ignore Java-style * comments. */ public class ShowNoComment { public static void main(String args[]) throws IOException { Tokenizer t = new Tokenizer("Show /* all */ // this"); t.setCharacterState('/', '/', t.symbolState()); while (true) { Token tok = t.nextToken(); if (tok.equals(Token.EOF)) { break; } System.out.println(tok); } } } This prints the following: Show / * all * / / / this The default behavior is for a Tokenizer to ignore these Java-style comments. By default, a Tokenizer object passes control to a SlashState object upon seeing a " / ". Figure 9.10 shows the slash states. Figure 9.10. Three states for slash. Note that the diagram shows attributes of class SlashState and not inheritance. A SlashState object uses the other states to consume a comment. 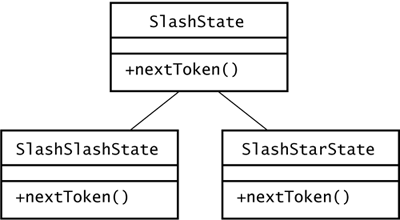 A SlashState handles three possibilities. It may need to ignore either type of comment, or it may be that the character read is only a slash. To decide the proper course, a SlashState object reads the next character and dispatches further responsibility to either a SlashSlashState object or a SlashStarState object. Or, if the next character is neither a " / " nor a " * ", the SlashState object returns the initial " / " as a symbol. If the character following a slash is an asterisk, a SlashStarState object consumes characters up to the next " */ ". The nextToken() method still needs to return a token, but SlashStarState delegates this responsibility back to the tokenizer. As Figure 9.7 shows, the signature of nextToken() includes a Tokenizer object. The SlashStarState implementation of nextToken() consumes a comment and then returns tokenizer.nextToken() . If the character following a slash is another slash, a SlashState object uses its SlashSlashState to ignore characters up to the end of the line. As with SlashStarState , this state consumes the comment and uses the tokenizer to find and return the next actual token. Comments bring out a weakness of the design of Tokenizer , which assumes that a single character is sufficient to determine which state to use to consume the next token. When this assumption is incorrect, the state must read further and must pass control to a substate. This design works reasonably well, because typically only one extra character at most is necessary for deciding which state to use. Another state that must sometimes peek ahead is SymbolState . 9.7.4 SymbolState Speaking loosely, a symbol is a character that typically should stand alone as a single token. Consider the string "(432+321)>(321+432)" and note that the middle of the string has the characters ")>(" . Most human readers will think of these three characters as three separate symbols and not as a string of related characters. The opposite applies to the characters "432" , which look like a single number and thus a single token. Given the string "(432+321)>(321+432)" , a default Tokenizer object returns tokens for a left parenthesis, the number 432 , a plus sign, the number 321 , a right parenthesis, a greater-than symbol, a left parenthesis, the number 321 , a plus sign, the number 432 , and a right parenthesis. A symbol is usually a single character that stands alone as its own token, such as a colon or comma. On seeing a symbol character, a Tokenizer object passes control to a SymbolState object. Typically, the SymbolState object reads no further and returns a Token object that represents a single character. For example, a typical tokenizer returns a less-than character in the input as a Token object of type TT_SYMBOL and a value of "<" . A problem arises when a language designer wants to allow multicharacter symbols. For example, in the string "cat<=dog" , the characters "<=" indicate a single symbol, with the meaning of less-than-or-equal. To allow for this, the class SymbolState provides a method for establishing strings of characters that together form a single symbol and should appear in a single Token : public void add(String s) Figure 9.11 shows the SymbolState class. Figure 9.11. The SymbolState class. A SymbolState object typically returns the single character that a tokenizer passes it as a symbol, such as " < ". 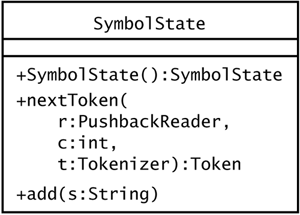 The SymbolState constructor uses this method to establish the following character strings as symbols: != :- <= >= Three of these symbols appear as operators in Java. The " :- " symbol, sometimes called if , is the predicate symbol of logic languages such as Prolog and Logikus. The following code gives an example of adding a new multicharacter symbol: package sjm.examples.tokens; import java.io.*; import sjm.parse.tokens.*; /** * This class shows how to add a new multicharacter symbol. */ public class ShowNewSymbol { public static void main(String args[]) throws IOException { Tokenizer t = new Tokenizer("42.001 =~= 42"); t.symbolState().add("=~="); while (true) { Token tok = t.nextToken(); if (tok.equals(Token.EOF)) { break; } System.out.println(tok); } } } This prints the following: 42.001 =~= 42.0 This output shows that the tokenizer has changed from the default, viewing " =~= " as a single symbol. To allow multicharacter symbols, the SymbolState class maintains a tree of SymbolNode objects. A SymbolNode object is a member of a tree that contains all possible prefixes of allowable symbols. Multicharacter symbols appear in a SymbolNode tree with one node for each character. For example, the symbol " =:~ " appears in a tree as three nodes, as Figure 9.12 shows. The first node contains an equal sign and has a child; that child contains a colon and has a child; this third child contains a tilde and has no children of its own. In this tree, the colon node has another child for a dollar sign character, so the tree contains the symbol " =:$ ". Figure 9.12. A SymbolNode tree. A SymbolNode tree contains all symbol prefixes, including many single character symbols such as " = ". The tree shown also contains the multicharacter symbols " =:~ " and " =:$ ". This diagram shows bold nodes that represent complete symbols. 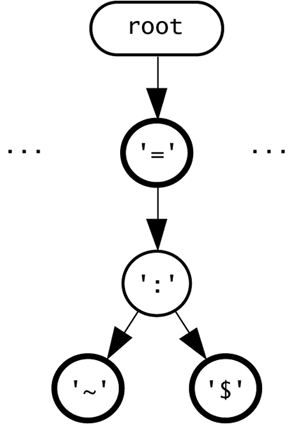 A tree of SymbolNode objects collaborate to read a potential multicharacter symbol from an input stream. A root node with no character of its own finds an initial node that represents the first character in the input. This node looks to see whether the next character in the input stream matches one of its children. If it matches, the node delegates its reading task to its child. This approach walks down the tree, pulling symbols from the input that match the path down the tree. When a node does not have a child that matches the next character, it will have read the longest possible symbol prefix from the input stream. This prefix may or may not be a valid symbol. Consider a symbol tree that has had " =:~ " added and has not had " =: " added, as in Figure 9.12. In this tree, of the three nodes that represent " =:~ ", only the first and third contain complete symbols. If, say, the input contains " =:a ", the colon node will not have a child that matches the a , so it will stop reading. The colon node must unread. It must push back its character and ask its parent to unread. Unreading continues until it reaches an ancestor that represents a valid symbol. The root node of a symbol node tree is a special case of a SymbolNode object. The class SymbolRootNode subclasses SymbolNode and overrides certain behaviors. A SymbolRootNode object has no symbol of its own, but it has children that represent all possible symbols. It keeps its children in an array and sets all its children to be valid symbols. The decision as to which characters are valid one-character symbols lies outside this tree. If a tokenizer asks a symbol tree to produce a symbol, the tree assumes that the first available character is a valid symbol. 9.7.5 WhitespaceState The term whitespace refers to a sequence of one or more whitespace characters. A whitespace character is subject to definition, but it usually includes at least spaces, tabs, and newlines. Figure 9.13 shows the WhitespaceState class. Figure 9.13. The WhitespaceState class. A Whitespace object ignores whitespace characters, such as spaces and tabs, and uses the tokenizer passed in nextToken() to find the actual next token.  For an example of whitespace, consider this declaration: int i; In this declaration, whitespace must occur between the type int and the variable i . Any combination of spaces, tabs, and other whitespace characters may appear as long as there is at least one whitespace character. By default, the Tokenizer class sets all characters with numeric values between 0 and 32 to be whitespace characters. Upon seeing one of these characters, a Tokenizer object transfers control to its default WhitespaceState object. The characters between 0 and 32 include all of Java's escape sequences. The lines System.out.println((int) '\b'); // backspace System.out.println((int) '\f'); // form feed System.out.println((int) '\n'); // newline System.out.println((int) '\r'); // carriage return System.out.println((int) '\t'); // tab System.out.println((int) ' '); // space print the following: 8 12 10 13 9 32 These numbers are the numeric values of the escape sequences. Each is less than or equal to 32, and by default the Tokenizer class treats them all as whitespace. The WhitespaceState.nextToken() method reads and ignores all whitespace characters and then, to return the next token, calls back the tokenizer object that called it. 9.7.6 WordState The decision that a character begins a word is the Tokenizer class's decision. The decision that a character belongs inside a word is the WordState class's decision. If you want to customize the characters that can make a word, you may need to customize the Tokenizer object, and you may need to customize the WordState object that the Tokenizer uses. To change how words may begin, update the Tokenizer object with a call to setCharacterState() . To change the characters that may appear inside a word, retrieve the Tokenizer object's WordState object with a call to wordState() , and update the WordState object with a call to setWordChars() . Figure 9.14 shows the WordState class. Figure 9.14. The WordState class. A WordState object builds a token that contains a word.  It's common to distinguish between the first character and the remaining characters of a word, especially in computer programming. In particular, words may conventionally contain digits but may not begin with a digit because the Tokenizer class (by default) does not transfer reading control to a WordState upon seeing a numeric digit. WordState objects do (by default) consider digits to be allowable characters within a word, so a word can contain digits. The WordState constructor contains these lines: setWordChars('a', 'z', true); setWordChars('A', 'Z', true); setWordChars('0', '9', true); setWordChars('-', '-', true); setWordChars('_', '_', true); setWordChars('\'', '\'', true); setWordChars(0xc0, 0xff, true); These calls to setWordChars() establish that, by default, a word can contain digits, minus signs (or hyphens), underscores, apostrophes , and most of the characters of European languages. You can change these defaults to suit the language you are tokenizing for. | 