13.3 Network Service Vulnerabilities and Attacks
| In this section, I concentrate on Internet-based network service vulnerabilities, particularly how software running at both the kernel and system daemon levels processes data. These vulnerabilities can be categorized into two high-level groups: memory manipulation weaknesses and simple logic flaws. Memory manipulation attacks are detailed here to help you understand the classification of bugs and the respective approaches that can be taken to mitigate risks. Simple logic flaws are identified and tackled throughout the book already (see Section 6.6) and are a much simpler threat to deal with. 13.3.1 Memory Manipulation AttacksMemory manipulation attacks involve sending malformed data to the target network service in a manner so that the logical program flow is affected (the idea is to execute arbitrary code on the host, although crashes sometimes occur, resulting in denial of service). Here are the three high-level categories of remotely exploitable memory manipulation attacks:
I discuss these three attack groups and describe individual attacks within each group (such as stack saved instruction and frame pointer overwrites). There are a small number of exotic bug types (e.g., index array manipulation and static overflows) that unfortunately lie outside the scope of this book, but which are covered in niche application security publications and online presentations. Through understanding how exploits work, you can effectively implement changes to your critical systems to protect against future vulnerabilities. To appreciate these low-level issues, you must first have an understanding of runtime memory organization and logical program flow. 13.3.2 Runtime Memory OrganizationMemory manipulation attacks involve overwriting values within memory (such as instruction pointers) to change the logical program flow and execute arbitrary code. Figure 13-2 shows memory layout when a program is run, along with descriptions of the four key areas: text, data and BSS, the stack, and the heap. Figure 13-2. Runtime memory layout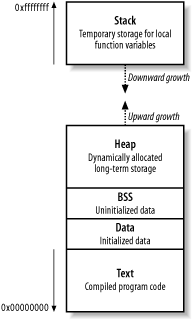 13.3.2.1 The text segmentThis segment contains all the compiled executable code for the program. Write permission to this segment is disabled for two reasons:
In the older days of computing, code would often modify itself to increase runtime speed. Today's modern processors are optimized for read-only code, so any modification to code only slows the processor. You can safely assume that if a program attempts to modify its own code, the attempt was unintentional. 13.3.2.2 The data and BSS segmentsThe data and Block Started by Symbol (BSS) segments contain all the global variables for the program. These memory segments have read and write access enabled, and, in Intel architectures, data in these segments can be executed. 13.3.2.3 The stackThe stack is a region of memory used to dynamically store and manipulate most program function variables. These local variables have known sizes (such as a password buffer with a size of 128 characters), so the space is assigned, and the data is manipulated in a relatively simply way. By default in most environments, data and variables on the stack can be read from, written to, and executed. When a program enters a function, space on the stack is provided for variables and data; i.e., a stack frame is created. Each function's stack frame contains the following:
As the size of the stack is adjusted to create this space, the processor stack pointer is incremented to point to the new end of the stack. The frame pointer points at the start of the current function stack frame. Two saved pointers are placed in the current stack frame: the saved instruction pointer and the saved frame pointer. The saved instruction pointer is read by the processor as part of the function epilogue (when the function has exited, and the space on the stack is freed up), and points the processor to the next function to be executed. The saved frame pointer is also processed as part of the function epilogue; it defines the beginning of the parent function's stack frame, so that logical program flow can continue cleanly. 13.3.2.4 The heapThe heap is a very dynamic area of memory and often the largest segment of memory assigned by a program. Programs use the heap to store data that must exist after a function returns (and its variables are wiped from the stack). The data and BSS segments could be used to store the information, but this isn't efficient, nor is it the purpose of those segments. The allocator and deallocator algorithms manage data on the heap. In C, these functions are called malloc( ) and free( ). When data is to be placed in the heap, malloc( ) is called to allocate a chunk of memory, and when the chunk is to be unlinked, free( ) releases the data. Various operating systems manage heap memory in different ways, using different algorithms. Table 13-1 shows the heap implementations in use across a number of popular operating systems.
Most software uses standard operating-system heap-management algorithms, although enterprise server packages, such as Oracle, use their own proprietary algorithms to provide better database performance. 13.3.3 Processor Registers and MemoryMemory contains the following: compiled machine code for the executable program (in the text segment), global variables (in the data and BSS segments), local variables and pointers (in the stack segment), and other data (in the heap segment). The processor reads and interprets values in memory by using registers. A register is an internal processor value that increments and jumps to point to memory addresses used during program execution. Register names are different under various processor architectures. Throughout this chapter I use the Intel IA32 processor architecture and register names (eip, ebp, and esp in particular). Figure 13-3 shows a high-level representation of a program executing in memory, including these processor registers and the various memory segments. Figure 13-3. The processor registers and runtime memory layout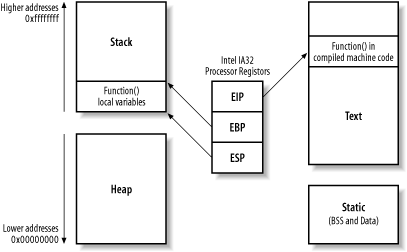 The three important registers from a security perspective are eip (the instruction pointer), ebp (the stack frame pointer), and esp (the stack pointer). The stack pointer should always point to the last address on the stack as it grows and shrinks in size, and the stack frame pointer defines the start of the current function's stack frame. The instruction pointer is an important register that points to compiled executable code (usually in the text segment) for execution by the processor. In Figure 13-3, the executable program code is processed from the text segment, and local variables and temporary data stored by the function exist on the stack. The heap is used for more long-term storage of data because when a function has run, its local variables are no longer referenced. Next, I'll discuss how, by corrupting memory in these segments, you can influence logical program flow. |
EAN: 2147483647
Pages: 166