6.7. Stackable Filesystems The early vnode interface was simply an object-oriented interface to an underlying filesystem. As the demand grew for new filesystem features, it became desirable to find ways of providing them without having to modify the existing and stable filesystem code. One approach is to provide a mechanism for stacking several filesystems on top of one another other [Rosenthal, 1990]. The stacking ideas were refined and implemented in the 4.4BSD system [Heidemann & Popek, 1994]. The implementation of the stacking has been refined in FreeBSD, but the semantics remain largely unchanged from those found in 4.4BSD. The bottom of a vnode stack tends to be a disk-based filesystem, whereas the layers used above it typically transform their arguments and pass on those arguments to a lower layer. In all UNIX systems, the mount command takes a special device as a source and maps that device onto a directory mount point in an existing filesystem. When a filesystem is mounted on a directory, the previous contents of the directory are hidden; only the contents of the root of the newly mounted filesystem are visible. To most users, the effect of the series of mount commands done at system startup is the creation of a single seamless filesystem tree. Stacking also uses the mount command to create new layers. The mount command pushes a new layer onto a vnode stack; an unmount command removes a layer. Like the mounting of a filesystem, a vnode stack is visible to all processes running on the system. The mount command identifies the underlying layer in the stack, creates the new layer, and attaches that layer into the filesystem name space. The new layer can be attached to the same place as the old layer (covering the old layer) or to a different place in the tree (allowing both layers to be visible). An example is shown in the next subsection. If layers are attached to different places in the name space, then the same file will be visible in multiple places. Access to the file under the name of the new layer's name space will go to the new layer, whereas that under the old layer's name space will go to only the old layer. When a file access (e.g., an open, read, stat, or close) occurs to a vnode in the stack, that vnode has several options: Do the requested operations and return a result. Pass the operation without change to the next-lower vnode on the stack. When the operation returns from the lower vnode, it may modify the results or simply return them. Modify the operands provided with the request and then pass it to the next-lower vnode. When the operation returns from the lower vnode, it may modify the results, or simply return them.
If an operation is passed to the bottom of the stack without any layer taking action on it, then the interface will return the error "operation not supported." Vnode interfaces released before 4.4BSD implemented vnode operations as indirect function calls. The requirements that intermediate stack layers bypass operations to lower layers and that new operations can be added into the system at boot or module load time mean that this approach is no longer adequate. Filesystems must be able to bypass operations that may not have been defined at the time that the filesystem was implemented. In addition to passing through the function, the filesystem layer must also pass through the function parameters, which are of unknown type and number. To resolve these two problems in a clean and portable way, the kernel places the vnode operation name and its arguments into an argument structure. This argument structure is then passed as a single parameter to the vnode operation. Thus, all calls on a vnode operation will always have exactly one parameter, which is the pointer to the argument structure. If the vnode operation is one that is supported by the filesystem, then it will know what the arguments are and how to interpret them. If it is an unknown vnode operation, then the generic bypass routine can call the same operation in the next-lower layer, passing to the operation the same argument structure that it received. In addition, the first argument of every operation is a pointer to the vnode operation description. This description provides to a bypass routine the information about the operation, including the operation's name and the location of the operation's parameters. An example access-check call and its implementation for the UPS filesystem are shown in Figure 6.11. Note that the vop_access_args structure is normally declared in a header file, but here it is declared at the function site to simplify the example. Figure 6.11. Call to and function header for access vnode operation. { . . . /* * Check for read permission on file ''vp''. */ if (error = VOP_ACCESS(vp, VREAD, cred, td)) return (error); . . . } /* * Check access permission for a file. */ int ufs_access( struct vop_access_args { struct vnodeop_desc *a_desc; /* operation descrip. */ struct vnode *a_vp; /* file to be checked */ int a_mode; /* access mode sought */ struct ucred *a_cred; /* user seeking access */ struct thread *a_td; /* associated thread */ } *ap); { if (permission granted) return (1); return (0); }
Simple Filesystem Layers The simplest filesystem layer is nullfs. It makes no transformations on its arguments, simply passing through all requests that it receives and returning all results that it gets back. Although it provides no useful functionality if it is simply stacked on top of an existing vnode, nullfs can provide a loopback filesystem by mounting the filesystem rooted at its source vnode at some other location in the filesystem tree. The code for nullfs is also an excellent starting point for designers who want to build their own filesystem layers. Examples that could be built include a compression layer or an encryption layer. A sample vnode stack is shown in Figure 6.12. The figure shows a local filesystem on the bottom of the stack that is being exported from /local via an NFS layer. Clients within the administrative domain of the server can import the /local filesystem directly because they are all presumed to use a common mapping of UIDs to user names. Figure 6.12. Stackable vnodes. 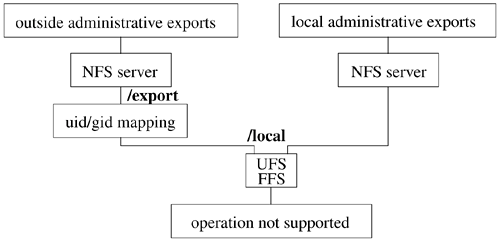
The umapfs filesystem works much like the nullfs filesystem in that it provides a view of the file tree rooted at the /local filesystem on the /export mount point. In addition to providing a copy of the /local filesystem at the /export mount point, it transforms the credentials of each system call made to files within the /export filesystem. The kernel does the transformation using a mapping that was provided as part of the mount system call that created the umapfs layer. The /export filesystem can be exported to clients from an outside administrative domain that uses different UIDs and GIDs. When an NFS request comes in for the /export filesystem, the umapfs layer modifies the credential from the foreign client by mapping the UIDs used on the foreign client to the corresponding UIDs used on the local system. The requested operation with the modified credential is passed down to the lower layer corresponding to the /local filesystem, where it is processed identically to a local request. When the result is returned to the mapping layer, any returned credentials are mapped inversely so that they are converted from the local UIDs to the outside UIDs, and this result is sent back as the NFS response. There are three benefits to this approach: There is no cost of mapping imposed on the local clients. There are no changes required to the local filesystem code or the NFS code to support mapping. Each outside domain can have its own mapping. Domains with simple mappings consume small amounts of memory and run quickly; domains with large and complex mappings can be supported without detracting from the performance of simpler environments.
Vnode stacking is an effective approach for adding extensions, such as the umapfs service. The Union Filesystem The union filesystem is another example of a middle filesystem layer. Like the nullfs, it does not store data but just provides a name-space transformation. It is loosely modeled on the work on the 3-D filesystem [Korn & Krell, 1989], on the Translucent filesystem [Hendricks, 1990], and on the Automounter [Pendry & Williams, 1994]. The union filesystem takes an existing filesystem and transparently overlays the latter on another filesystem. Unlike most other filesystems, a union mount does not cover up the directory on which the filesystem is mounted. Instead, it shows the logical merger of both directories and allows both directory trees to be accessible simultaneously [Pendry & McKusick, 1995]. A small example of a union-mount stack is shown in Figure 6.13. Here, the bottom layer of the stack is the src filesystem that includes the source for the shell program. Being a simple program, it contains only one source and one header file. The upper layer that has been union mounted on top of src initially contains just the src directory. When the user changes directory into shell, a directory of the same name is created in the top layer. Directories in the top layer corresponding to directories in the lower layer are created only as they are encountered while the top layer is traversed. If the user were to run a recursive traversal of the tree rooted at the top of the union-mount location, the result would be a complete tree of directories matching the underlying filesystem. In our example, the user now types make in the shell directory. The sh executable is created in the upper layer of the union stack. To the user, a directory listing shows the sources and executable all apparently together, as shown on the right in Figure 6.13. Figure 6.13. A union-mounted filesystem. The /usr/src filesystem is on the bottom, and the /tmp/src filesystem is on the top. 
All filesystem layers, except the top one, are treated as though they were readonly. If a file residing in a lower layer is opened for reading, a descriptor is returned for that file. If a file residing in a lower layer is opened for writing, the kernel first copies the entire file to the top layer and then returns a descriptor referencing the copy of the file. The result is that there are two copies of the file: the original unmodified file in the lower layer and the modified copy of the file in the upper layer. When the user does a directory listing, any duplicate names in the lower layer are suppressed. When a file is opened, a descriptor for the file in the uppermost layer in which the name appears is returned. Thus, once a file has been copied to the top layer, instances of the file in lower layers become inaccessible. The tricky part of the union filesystem is handling the removal of files that reside in a lower layer. Since the lower layers cannot be modified, the only way to remove a file is to hide it by creating a whiteout directory entry in the top layer. A whiteout is an entry in a directory that has no corresponding file; it is distinguished by having an inode number of 1. If the kernel finds a whiteout entry while searching for a name, the lookup is stopped and the "no such file or directory" error is returned. Thus, the file with the same name in a lower layer appears to have been removed. If a file is removed from the top layer, it is necessary to create a whiteout entry for it only if there is a file with the same name in the lower level that would reappear. When a process creates a file with the same name as a whiteout entry, the whiteout entry is replaced with a regular name that references the new file. Because the new file is being created in the top layer, it will mask out any files with the same name in a lower layer. When a user does a directory listing, white-out entries and the files that they mask usually are not shown. However, there is an option that causes them to appear. One feature that has long been missing in UNIX systems is the ability to recover files after they have been deleted. For the union filesystem, the kernel can implement file recovery trivially simply by removing the whiteout entry to expose the underlying file. For filesystems that provide file recovery, users can recover files by using a special option to the remove command. Processes can recover files by using the undelete system call. When a directory whose name appears in a lower layer is removed, a whiteout entry is created just as it would be for a file. However, if the user later attempts to create a directory with the same name as the previously deleted directory, the union filesystem must treat the new directory specially to avoid having the previous contents from the lower-layer directory reappear. When a directory that replaces a whiteout entry is created, the union filesystem sets a flag in the directory metadata to show that this directory should be treated specially. When a directory scan is done, the kernel returns information about only the top-level directory; it suppresses the list of files from the directories of the same name in the lower layers. The union filesystem can be used for many purposes: It allows several different architectures to build from a common source base. The source pool is NFS mounted onto each of several machines. On each host machine, a local filesystem is union mounted on top of the imported source tree. As the build proceeds, the objects and binaries appear in the local filesystem that is layered above the source tree. This approach not only avoids contaminating the source pool with binaries, but also speeds the compilation, because most of the filesystem traffic is on the local filesystem. It allows compilation of sources on read-only media such as CD-ROMs. A local filesystem is union mounted above the CD-ROM sources. It is then possible to change into directories on the CD-ROM and to give the appearance of being able to edit and compile in that directory. It allows creation of a private source directory. The user creates a source directory in her own work area and then union mounts the system sources underneath that directory. This feature is possible because the restrictions on the mount command have been relaxed. If the sysctl vfs.usermount option has been enabled, any user can do a mount if she owns the directory on which the mount is being done and she has appropriate access permissions on the device or directory being mounted (read permission is required for a read-only mount, read-write permission is required for a read-write mount). Only the user who did the mount or the superuser can unmount a filesystem.
Other Filesystems There are several other filesystems included as part of FreeBSD. The portal filesystem mounts a process onto a directory in the file tree. When a pathname that traverses the location of the portal is used, the remainder of the path is passed to the process mounted at that point. The process interprets the path in whatever way it sees fit, then returns a descriptor to the calling process. This descriptor may be for a socket connected to the portal process. If it is, further operations on the descriptor will be passed to the portal process for the latter to interpret. Alternatively, the descriptor may be for a file elsewhere in the filesystem. Consider a portal process mounted on /dialout used to manage a bank of dialout modems. When a process wanted to connect to an outside number, it would open /dialout/15105551212/28800 to specify that it wanted to dial 1-510-555-1212 at 28800 baud. The portal process would get the final two pathname components. Using the final component, it would determine that it should find an unused 28800-baud modem. It would use the other component as the number to which to place the call. It would then write an accounting record for future billing, and would return the descriptor for the modem to the process. An interesting use of the portal filesystem is to provide an Internet service directory. For example, with an Internet portal process mounted on /net, an open of /net/tcp/McKusick.COM/smtp returns a TCP socket descriptor to the calling process that is connected to the SMTP server on McKusick.COM. Because access is provided through the normal filesystem, the calling process does not need to be aware of the special functions necessary to create a TCP socket and to establish a TCP connection [Stevens & Pendry, 1995]. There are several filesystems that are designed to provide a convenient interface to kernel information. The procfs filesystem is normally mounted at /proc and provides a view of the running processes in the system. Its primary use is for debugging, but it also provides a convenient interface for collecting information about the processes in the system. A directory listing of /proc produces a numeric list of all the processes in the system. The /proc interface is more fully described in Section 4.9. The fdesc filesystem is normally mounted on /dev/fd and provides a list of all the active file descriptors for the currently running process. An example where this is useful is specifying to an application that it should read input from its standard input. Here, you can use the pathname /dev/fd/0 instead of having to come up with a special convention, such as using the name - to tell the application to read from its standard input. The kernfs filesystem is normally mounted on /kern and contains files that have various information about the system. It includes information such as the host name, time of day, and version of the system. Finally there is the cd9660 filesystem. It allows ISO-9660-compliant filesystems, with or without Rock Ridge extensions, to be mounted. The ISO-9660 filesystem format is most commonly used on CD-ROMs. |