6.6. Filesystem-Independent Services The vnode interface not only supplies an object-oriented interface to the underlying filesystems but also provides a set of management routines that can be used by the client filesystems. These facilities are described in this section. When the final file-entry reference to a file is closed, the usage count on the vnode drops to zero and the vnode interface calls the inactive() vnode operation. The inactive() call notifies the underlying filesystem that the file is no longer being used. The filesystem will often use this call to write dirty data back to the file but will not typically reclaim the memory holding file data. The filesystem is permitted to cache the file so that the latter can be reactivated quickly (i.e., without disk or network I/O) if the file is reopened. In addition to the inactive() vnode operation being called when the reference count drops to zero, the vnode is placed on a systemwide free list. Unlike many vendor's vnode implementations, which have a fixed number of vnodes allocated to each filesystem type, the FreeBSD kernel keeps a single systemwide collection of vnodes. When an application opens a file that does not currently have an in-memory vnode, the client filesystem calls the getnewvnode() routine to allocate a new vnode. The kernel maintains two lists of free vnodes: those that have data pages cached in memory and those that do not have any data pages cached in memory. The preference is to reuse vnodes with no cached pages, since the reuse of a vnode with cached pages will cause all the cached pages associated with that vnode to lose their identity. If the vnodes were not classified separately, then an application that walked the filesystem tree doing stat calls on each file that it encountered would eventually flush all the vnodes referencing data pages, thus losing the identity of all the cached pages in the kernel. So when allocating a new vnode, the getnewvnode() routine first checks the front of the free list of vnodes with no cached pages and only if that list is empty does it select from the front of the list of vnodes with cached pages. Having selected a vnode, the getnewvnode() routine then calls the vnode's reclaim() operation to notify the filesystem currently using that vnode that it is about to be reused. The reclaim() operation writes back any dirty data associated with the underlying object, removes the underlying object from any lists that it is on (such as hash lists used to find it), and frees up any auxiliary storage that was being used by the object. The vnode is then returned for use by the new client filesystem. The benefit of having a single global vnode table is that the kernel memory dedicated to vnodes is used more efficiently than when several filesystem-specific collections of vnodes are used. Consider a system that is willing to dedicate memory for 1000 vnodes. If the system supports 10 filesystem types, then each filesystem type will get 100 vnodes. If most of the activity moves to a single filesystem (e.g., during the compilation of a kernel located in a local filesystem), all the active files will have to be kept in the 100 vnodes dedicated to that filesystem while the other 900 vnodes sit idle. In a FreeBSD system, all 1000 vnodes could be used for the active filesystem, allowing a much larger set of files to be cached in memory. If the center of activity moved to another filesystem (e.g., compiling a program on an NFS mounted filesystem), the vnodes would migrate from the previously active local filesystem over to the NFS filesystem. Here, too, there would be a much larger set of cached files than if only 100 vnodes were available using a partitioned set of vnodes. The reclaim() operation is a disassociation of the underlying filesystem object from the vnode itself. This ability, combined with the ability to associate new objects with the vnode, provides functionality with usefulness that goes far beyond simply allowing vnodes to be moved from one filesystem to another. By replacing an existing object with an object from the dead filesystem-a filesystem in which all operations except close fail the kernel revokes the object. Internally, this revocation of an object is provided by the vgone() routine. This revocation service is used for session management, where all references to the controlling terminal are revoked when the session leader exits. Revocation works as follows. All open terminal descriptors within the session reference the vnode for the special device representing the session terminal. When vgone() is called on this vnode, the underlying special device is detached from the vnode and is replaced with the dead filesystem. Any further operations on the vnode will result in errors, because the open descriptors no longer reference the terminal. Eventually, all the processes will exit and will close their descriptors, causing the reference count to drop to zero. The inactive() routine for the dead filesystem returns the vnode to the front of the free list for immediate reuse because it will never be possible to get a reference to the vnode again. The revocation service supports forcible unmounting of filesystems. If the kernel finds an active vnode when unmounting a filesystem, it simply calls the vgone() routine to disassociate the active vnode from the filesystem object. Processes with open files or current directories within the filesystem find that they have simply vanished, as though they had been removed. It is also possible to downgrade a mounted filesystem from read-write to read-only. Instead of access being revoked on every active file within the filesystem, only those files with a nonzero number of references for writing have their access revoked. Finally, the ability to revoke objects is exported to processes through the revoke system call. This system call can be used to ensure controlled access to a device such as a pseudo-terminal port. First, the ownership of the device is changed to the desired user and the mode is set to owner-access only. Then the device name is revoked to eliminate any interlopers that already had it open. Thereafter, only the new owner is able to open the device. The Name Cache Name-cache management is another service that is provided by the vnode management routines. The interface provides a facility to add a name and its corresponding vnode, to lookup a name to get the corresponding vnode, and to delete a specific name from the cache. In addition to providing a facility for deleting specific names, the interface also provides an efficient way to invalidate all names that reference a specific vnode. Each vnode has a list that links together all their entries in the name cache. When the references to the vnode are to be deleted, each entry on the list is purged. Each directory vnode also has a second list of all the cache entries for names that are contained within it. When a directory vnode is to be purged, it must delete all the name-cache entries on this second list. A vnode's name-cache entries must be purged each time it is reused by getnewvnode() or when specifically requested by a client (e.g., when a directory is being renamed). The cache-management routines also allow for negative caching. If a name is looked up in a directory and is not found, that name can be entered in the cache, along with a null pointer for its corresponding vnode. If the name is later looked up, it will be found in the name table, and thus the kernel can avoid scanning the entire directory to determine that the name is not there. If a name is added to a directory, then the name cache must lookup that name and purge it if it finds a negative entry. Negative caching provides a significant performance improvement because of path searching in command shells. When executing a command, many shells will look at each path in turn, looking for the executable. Commonly run executables will be searched for repeatedly in directories in which they do not exist. Negative caching speeds these searches. Buffer Management Historically, UNIX systems divided the main memory into two main pools. The first was the virtual-memory pool that was used to cache process pages. The second was the buffer pool and was used to cache filesystem data. The main memory was divided between the two pools when the system booted and there was no memory migration between the pools once they were created. With the addition of the mmap system call, the kernel supported the mapping of files into the address space of a process. If a file is mapped in with the MAP_SHARED attribute, changes made to the mapped file are to be written back to the disk and should show up in read calls done by other processes. Providing these semantics is difficult if there are copies of a file in both the buffer cache and the virtual-memory cache. Thus, FreeBSD merged the buffer cache and the virtual-memory cache into a single-page cache. As described in Chapter 5, virtual memory is divided into a pool of pages holding the contents of files and a pool of anonymous pages holding the parts of a process that are not backed by a file such as its stack and heap. Pages backed by a file are identified by their vnode and logical block number. Rather than rewrite all the filesystems to lookup pages in the virtual-memory pool, a buffer-cache emulation layer was written. The emulation layer has the same interface as the old buffer-cache routines but works by looking up the requested file pages in the virtual-memory cache. When a filesystem requests a block of a file, the emulation layer calls the virtual-memory system to see if it is in memory. If it is not in memory, the virtual-memory system arranges to have it read. Normally, the pages in the virtual-memory cache are not mapped into the kernel address space. However, a filesystem often needs to inspect the blocks that it requests for example, if it is a directory or filesystem metadata. Thus, the buffer-cache emulation layer must not only find the requested block but also allocate some kernel address space and map the requested block into it. The filesystem then uses the buffer to read, write, or manipulate the data and when done releases the buffer. On release, the buffer may be held briefly but soon is dissolved by releasing the kernel mapping, dropping the reference count on the virtual-memory pages and releasing the header. The virtual-memory system does not have any way to describe blocks that are identified as a block associated with a disk. A small remnant of the buffer cache remains to hold these disk blocks that are used to hold filesystem metadata such as superblocks, bitmaps, and inodes. The internal kernel interface to the buffer-cache emulation layer is simple. The filesystem allocates and fills buffers by calling the bread() routine. Bread() takes a vnode, a logical block number, and a size, and returns a pointer to a locked buffer. The details on how a buffer is created are given in the next subsection. Any other thread that tries to obtain the buffer will be put to sleep until the buffer is released. A buffer can be released in one of four ways. If the buffer has not been modified, it can simply be released through use of brelse(), which checks for any threads that are waiting for it. If any threads are waiting, they are awakened. Otherwise the buffer is dissolved by returning its contents back to the virtual-memory system, releasing its kernel address-space mapping and releasing the buffer. If the buffer has been modified, it is called dirty. Dirty buffers must eventually be written back to their filesystem. Three routines are available based on the urgency with which the data must be written. In the typical case, bdwrite() is used. Since the buffer may be modified again soon, it should be marked as dirty but should not be written immediately. After the buffer is marked as dirty, it is returned to the dirty-buffer list and any threads waiting for it are awakened. The heuristic is that, if the buffer will be modified again soon, the I/O would be wasted. Because the buffer is typically held for 20 to 30 seconds before it is written, a thread doing many small writes will not repeatedly access the disk or network. If a buffer has been filled completely, then it is unlikely to be written again soon, so it should be released with bawrite(). Bawrite() schedules an I/O on the buffer but allows the caller to continue running while the output completes. The final case is bwrite(), which ensures that the write is complete before proceeding. Because bwrite() can introduce a long latency to the writer, it is used only when a process explicitly requests the behavior (such as the fsync system call), when the operation is critical to ensure the consistency of the filesystem after a system crash, or when a stateless remote filesystem protocol such as NFS is being served. A buffer that is written using bawrite() or bwrite() is placed on the appropriate output queue. When the output completes, the brelse() routine is called to awaken any threads that are waiting for it or, if there is no immediate need for it, to dissolve the buffer. Some buffers, though clean, may be needed again soon. To avoid the overhead of repeatedly creating and dissolving buffers, the buffer-cache emulation layer provides the bqrelse() routine to let the filesystem notify it that it expects to use the buffer again soon. The bqrelse() routine places the buffer on a clean list rather than dissolving it. Figure 6.8 shows a snapshot of the buffer pool. A buffer with valid contents is contained on exactly one bufhash hash chain. The kernel uses the hash chains to determine quickly whether a block is in the buffer pool, and if it is, to locate it. A buffer is removed only when its contents become invalid or it is reused for different data. Thus, even if the buffer is in use by one thread, it can still be found by another thread, although it will be locked so that it will not be used until its contents are consistent. Figure 6.8. Snapshot of the buffer pool. Key: V vnode; X file offset. 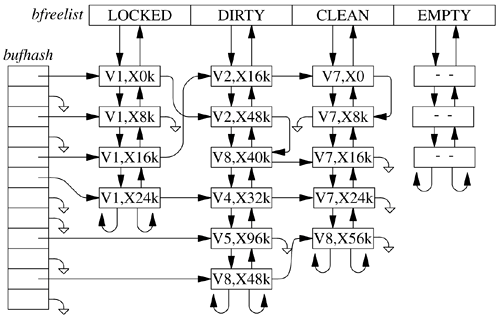
In addition to appearing on the hash list, each unlocked buffer appears on exactly one free list. The first free list is the LOCKED list. Buffers on this list cannot be flushed from the cache. This list was originally intended to hold superblock data; in FreeBSD, it holds only buffers being written in background. In a background write, the contents of a dirty buffer are copied to another anonymous buffer. The anonymous buffer is then written to disk. The original buffer can continue to be used while the anonymous buffer is being written. Background writes are used primarily for fast and continuously changing blocks such as those that hold filesystem allocation bitmaps. If the block holding the bitmap was written normally, it would be locked and unavailable while it waited on the disk queue to be written. Thus, applications trying to write files in the area described by the bitmap would be blocked from running while they waited for the write of the bitmap to finish so that they could update the bitmap. By using background writes for bitmaps, applications are rarely forced to wait to update a bitmap. The second list is the DIRTY list. Buffers that have been modified, but not yet written to disk, are stored on this list. The DIRTY list is managed using a least-recently used algorithm. When a buffer is found on the DIRTY list, it is removed and used. The buffer is then returned to the end of the DIRTY list. When too many buffers are dirty, the kernel starts the buffer daemon running. The buffer daemon writes buffers starting from the front of the DIRTY list. Thus, buffers written repeatedly will continue to migrate to the end of the DIRTY list and are not likely to be prematurely written or reused for new blocks. The third free list is the CLEAN list. This list holds blocks that a filesystem is not currently using but that it expects to use soon. The CLEAN list is also managed using a least-recently used algorithm. If a requested block is found on the CLEAN list, it is returned to the end of the list. The final list is the list of empty buffers the EMPTY list. The empty buffers are just headers and have no memory associated with them. They are held on this list waiting for another mapping request. When a new buffer is needed, the kernel first checks to see how much memory is dedicated to the existing buffers. If the memory in use is below its permissible threshold, a new buffer is created from the EMPTY list. Otherwise the oldest buffer is removed from the front of the CLEAN list. If the CLEAN list is empty, the buffer daemon is awakened to clean up and release a buffer from the DIRTY list. Implementation of Buffer Management Having looked at the functions and algorithms used to manage the buffer pool, we now turn our attention to the implementation requirements for ensuring the consistency of the data in the buffer pool. Figure 6.9 shows the support routines that implement the interface for getting buffers. The primary interface to getting a buffer is through bread(), which is called with a request for a data block of a specified size for a specified vnode. There is also a related interface, breadn(), that both gets a requested block and starts read-ahead for additional blocks. Bread() first calls getblk() to find out whether the data block is available in an existing buffer. If the block is available in a buffer, getblk() calls bremfree() to take the buffer off whichever free list it is on and to lock it; bread() can then return the buffer to the caller. Figure 6.9. Procedural interface to the buffer-allocation system. 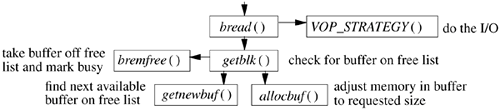
If the block is not already in an existing buffer, getblk() calls getnewbuf() to allocate a new buffer, using the algorithm described in the previous subsection. The new buffer is then passed to allocbuf(), which is responsible for determining how to constitute the contents of the buffer. The common case is that the buffer is to contain a logical block of a file. Here, allocbuf() must request the needed block from the virtual-memory system. If the virtual-memory system does not already have the needed block, it arranges to get it brought into its page cache. The allocbuf() routine then allocates an appropriately sized piece of kernel address space and requests the virtual-memory system to map the needed file block into that address space. The buffer is then marked filled and returned through getblk() and bread(). The other case is that the buffer is to contain a block of filesystem metadata such as a bitmap or an inode block that is associated with a disk device rather than a file. Because the virtual memory does not (currently) have any way to track such blocks, they can be held in memory only within buffers. Here, allocbuf() must call the kernel malloc() routine to allocate memory to hold the block. The allocbuf() routine then returns the buffer to getblk() and bread() marked busy and unfilled. Noticing that the buffer is unfilled, bread() passes the buffer to the strategy() routine for the underlying filesystem to have the data read in. When the read completes, the buffer is returned. To maintain the consistency of the filesystem, the kernel must ensure that a disk block is mapped into at most one buffer. If the same disk block were present in two buffers, and both buffers were marked dirty, the system would be unable to determine which buffer had the most current information. Figure 6.10 shows a sample allocation. In the middle of the figure are the blocks on the disk. Above the disk is shown an old buffer containing a 4096-byte fragment for a file that presumably has been removed or shortened. The new buffer is going to be used to hold a 4096-byte fragment for a file that is presumably being created and that will reuse part of the space previously held by the old file. The kernel maintains the consistency by purging old buffers when files are shortened or removed. Whenever a file is removed, the kernel traverses its list of dirty buffers. For each buffer, the kernel cancels its write request and dissolves the buffer so that the buffer cannot be found in the buffer pool again. For a file being partially truncated, only the buffers following the truncation point are invalidated. The system can then allocate the new buffer, knowing that the buffer maps the corresponding disk blocks uniquely. Figure 6.10. Potentially overlapping allocation of buffers. 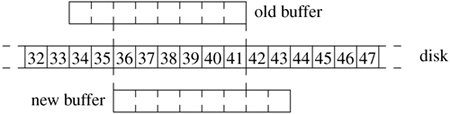
|