5.3. Kernel Memory Management There are two ways in which the kernel's memory can be organized. The most common is for the kernel to be permanently mapped into the high part of every process address space. In this model, switching from one process to another does not affect the kernel portion of the address space. The alternative organization is to switch between having the kernel occupy the whole address space and mapping the currently running process into the address space. Having the kernel permanently mapped does reduce the amount of address space available to a large process (and the kernel), but it also reduces the cost of data copying. Many system calls require data to be transferred between the currently running user process and the kernel. With the kernel permanently mapped, the data can be copied via the efficient block-copy instructions. If the kernel is alternately mapped with the process, data copying requires the use of special instructions that copy to and from the previously mapped address space. These instructions are usually a factor of 2 slower than the standard block-copy instructions. Since up to one-third of the kernel time is spent in copying between the kernel and user processes, slowing this operation by a factor of 2 significantly slows system throughput. Although the kernel is able to freely read and write the address space of the user process, the converse is not true. The kernel's range of virtual address space is marked inaccessible to all user processes. Writing is restricted so user processes cannot tamper with the kernel's data structures. Reading is restricted so user processes cannot watch sensitive kernel data structures, such as the terminal input queues, that include such things as users typing their passwords. Usually, the hardware dictates which organization can be used. All the architectures supported by FreeBSD map the kernel into the top of the address space. Kernel Maps and Submaps When the system boots, the first task that the kernel must do is to set up data structures to describe and manage its address space. Like any process, the kernel has a vm_map with a corresponding set of vm_map_entry structures that describe the use of a range of addresses. Submaps are a special kernel-only construct used to isolate and constrain address-space allocation for kernel subsystems. One use is in subsystems that require contiguous pieces of the kernel address space. To avoid intermixing of unrelated allocations within an address range, that range is covered by a submap, and only the appropriate subsystem can allocate from that map. For example, several network buffer (mbuf) manipulation macros use address arithmetic to generate unique indices, thus requiring the network buffer region to be contiguous. Parts of the kernel may also require addresses with particular alignments or even specific addresses. Both can be ensured by use of submaps. Finally, submaps can be used to limit statically the amount of address space and hence the physical memory consumed by a subsystem. A typical layout of the kernel map is shown in Figure 5.5. The kernel's address space is described by the vm_map structure shown in the upperleft corner of the figure. Pieces of the address space are described by the vm_map_entry structures that are linked in ascending address order from K0 to K8 on the vm_map structure. Here, the kernel text, initialized data, uninitialized data, and initially allocated data structures reside in the range K0 to Kl and are represented by the first vm_map_entry. The next vm_map_entry is associated with the address range from K2 to K6. This piece of the kernel address space is being managed via a submap headed by the referenced vm_map structure. This submap currently has two parts of its address space used: the address range K2 to K3, and the address range K4 to K5. These two submaps represent the kernel malloc arena and the network buffer arena, respectively. The final part of the kernel address space is being managed in the kernel's main map, the address range K7 to K8 representing the kernel I/O staging area. Figure 5.5. Kernel address-space maps. 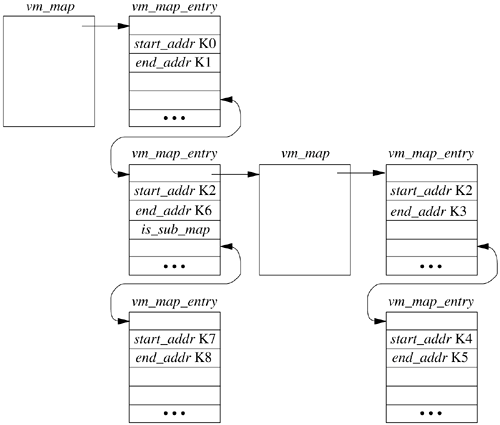
Kernel Address-Space Allocation The virtual-memory system implements a set of primitive functions for allocating and freeing the page-aligned, page-rounded virtual-memory ranges that the kernel uses. These ranges may be allocated either from the main kernel-address map or from a submap. The allocation routines take a map and size as parameters but do not take an address. Thus, specific addresses within a map cannot be selected. There are different allocation routines for obtaining nonpageable and pageable memory ranges. A nonpageable, or wired, range has physical memory assigned at the time of the call, and this memory is not subject to replacement by the pageout daemon. Wired pages must never cause a page fault that might result in a blocking operation. Wired memory is allocated with kmem_alloc() and kmem_malloc(). Kmem_alloc() returns zero-filled memory and may block if insufficient physical memory is available to honor the request. It will return a failure only if no address space is available in the indicated map. Kmem_malloc() is a variant of kmem_alloc() used by only the general allocator, malloc(), described in the next subsection. This routine has a nonblocking option that protects callers against inadvertently blocking on kernel data structures; it will fail if insufficient physical memory is available to fill the requested range. This nonblocking option allocates memory at interrupt time and during other critical sections of code. In general, wired memory should be allocated via the general-purpose kernel allocator. Kmem_alloc() should be used only to allocate memory from specific kernel submaps. Pageable kernel virtual memory can be allocated with kmem_alloc_pageable() and kmem_alloc_wait(). A pageable range has physical memory allocated on demand, and this memory can be written out to backing store by the pageout daemon as part of the latter's normal replacement policy. Kmem_alloc_pageable() will return an error if insufficient address space is available for the desired allocation; kmem_alloc_wait() will block until space is available. Currently, pageable kernel memory is used only for temporary storage of exec arguments. Kmem_free() deallocates kernel wired memory and pageable memory allocated with kmem_alloc_pageable(). Kmem_free_wakeup() should be used with kmem_alloc_wait() because it wakes up any processes waiting for address space in the specified map. Kernel Malloc The kernel also provides a generalized nonpageable memory-allocation and freeing mechanism that can handle requests with arbitrary alignment or size, as well as allocate memory at interrupt time. So it is the preferred way to allocate kernel memory other than large, fixed-size structures that are better handled by the zone allocator described in the next subsection. This mechanism has an interface similar to that of the well-known memory allocator provided for applications programmers through the C library routines malloc() and free(). Like the C library interface, the allocation routine takes a parameter specifying the size of memory that is needed. The range of sizes for memory requests are not constrained. The free routine takes a pointer to the storage being freed, but it does not require the size of the piece of memory being freed. Often, the kernel needs a memory allocation for the duration of a single system call. In a user process, such short-term memory would be allocated on the run-time stack. Because the kernel has a limited run-time stack, it is not feasible to allocate even moderate blocks of memory on it. Consequently, such memory must be allocated dynamically. For example, when the system must translate a pathname, it must allocate a 1-Kbyte buffer to hold the name. Other blocks of memory must be more persistent than a single system call and have to be allocated from dynamic memory. Examples include protocol control blocks that remain throughout the duration of a network connection. The design specification for a kernel memory allocator is similar, but not identical, to the design criteria for a user-level memory allocator. One criterion for a memory allocator is that it make good use of the physical memory. Use of memory is measured by the amount of memory needed to hold a set of allocations at any point in time. Percentage utilization is expressed as 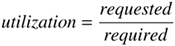
Here, requested is the sum of the memory that has been requested and not yet freed; required is the amount of memory that has been allocated for the pool from which the requests are filled. An allocator requires more memory than requested because of fragmentation and a need to have a ready supply of free memory for future requests. A perfect memory allocator would have a utilization of 100 percent. In practice, a 50 percent utilization is considered good [Korn & Vo, 1985]. Good memory utilization in the kernel is more important than in user processes. Because user processes run in virtual memory, unused parts of their address space can be paged out. Thus, pages in the process address space that are part of the required pool that are not being requested do not need to tie up physical memory. Since the kernel malloc arena is not paged, all pages in the required pool are held by the kernel and cannot be used for other purposes. To keep the kernel-utilization percentage as high as possible, the kernel should release unused memory in the required pool rather than hold it, as is typically done with user processes. Because the kernel can manipulate its own page maps directly, freeing unused memory is fast; a user process must do a system call to free memory. The most important criterion for a kernel memory allocator is that it be fast. A slow memory allocator will degrade the system performance because memory allocation is done frequently. Speed of allocation is more critical when executing in the kernel than it is in user code because the kernel must allocate many data structures that user processes can allocate cheaply on their run-time stack. In addition, the kernel represents the platform on which all user processes run, and if it is slow, it will degrade the performance of every process that is running. Another problem with a slow memory allocator is that programmers of frequently used kernel interfaces will think that they cannot afford to use the memory allocator as their primary one. Instead, they will build their own memory allocator on top of the original by maintaining their own pool of memory blocks. Multiple allocators reduce the efficiency with which memory is used. The kernel ends up with many different free lists of memory instead of a single free list from which all allocations can be drawn. For example, consider the case of two subsystems that need memory. If they have their own free lists, the amount of memory tied up in the two lists will be the sum of the greatest amount of memory that each of the two subsystems has ever used. If they share a free list, the amount of memory tied up in the free list may be as low as the greatest amount of memory that either subsystem used. As the number of subsystems grows, the savings from having a single free list grow. The kernel memory allocator uses a hybrid strategy. Small allocations are done using a power-of-2 list strategy. Using the zone allocator (described in the next subsection), the kernel creates a set of zones with one for each power-of-two between 16 and the page size. The allocation simply requests a block of memory from the appropriate zone. Usually, the zone will have an available piece of memory that it can return. Only if every piece of memory in the zone is in use will the zone allocator have to do a full allocation. When forced to do an additional allocation, it allocates an entire page and carves it up into the appropriate-sized pieces. This strategy speeds future allocations because several pieces of memory become available as a result of the call into the allocator. Freeing a small block also is fast. The memory is simply returned to the zone from which it came. Because of the inefficiency of power-of-2 allocation strategies for large allocations, the allocation method for large blocks is based on allocating pieces of memory in multiples of pages. The algorithm switches to the slower but more memory-efficient strategy for allocation sizes larger than a page. This value is chosen because the power-of-2 algorithm yields sizes of 1, 2, 4, 8, . . ., n pages, whereas the large block algorithm that allocates in multiples of pages yields sizes of 1, 2, 3, 4,. . ., n pages. Thus, for allocations of greater than one page, the large block algorithm will use less than or equal to the number of pages used by the power-of-2 algorithm, so the threshold between the large and small allocators is set at one page. Large allocations are first rounded up to be a multiple of the page size. The allocator then uses a "first-fit" algorithm to find space in the kernel address arena set aside for dynamic allocations. On a machine with a 4-Kbyte page size, a request for a 20-Kbyte piece of memory will use exactly five pages of memory, rather than the eight pages used with the power-of-2 allocation strategy. When a large piece of memory is freed, the memory pages are returned to the free-memory pool and the vm_map_entry structure is deleted from the submap, effectively coalescing the freed piece with any adjacent free space. Because the size is not specified when a block of memory is freed, the allocator must keep track of the sizes of the pieces that it has handed out. Many allocators increase the allocation request by a few bytes to create space to store the size of the block in a header just before the allocation. However, this strategy doubles the memory requirement for allocations that request a power-of-2-sized block. Therefore, instead of storing the size of each piece of memory with the piece itself, the zone allocator associates the size information with the memory page. Locating the allocation size outside of the allocated block improved utilization far more than expected. The reason is that many allocations in the kernel are for blocks of memory whose size is exactly a power of 2. The size of these requests would be nearly doubled if the more typical strategy were used. Now they can be accommodated with no wasted memory. The allocator can be called both from the top half of the kernel that is willing to wait for memory to become available and from the interrupt routines in the bottom half of the kernel that cannot wait for memory to become available. Clients show their willingness (and ability) to wait with a flag to the allocation routine. For clients that are willing to wait, the allocator guarantees that their request will succeed. Thus, these clients do not need to check the return value from the allocator. If memory is unavailable and the client cannot wait, the allocator returns a null pointer. These clients must be prepared to cope with this (typically infrequent) condition (usually by giving up and hoping to succeed later). The details of the kernel memory allocator are further described in McKusick & Karels [1988]. Kernel Zone Allocator Some commonly allocated items in the kernel such as process, thread, vnode, and control-block structures are not well handled by the general purpose malloc interface. These structures share several characteristics: They tend to be large and hence wasteful of space. For example, the process structure is about 550 bytes, which when rounded up to a power-of-2 size requires 1024 bytes of memory. They tend to be common. Because they are individually wasteful of space, collectively they waste too much space compared to a denser representation. They are often linked together in long lists. If the allocation of each structure begins on a page boundary, then the list pointers will all be at the same offset from the beginning of the page. When traversing these structures, the linkage pointers will all be located on the same hardware cache line, causing each step along the list to produce a cache miss, making the list-traversal slow. These structures often contain many lists and locks that must be initialized before use. If there is a dedicated pool of memory for each structure, then these substructures need to be initialized only when the pool is first created rather than after every allocation.
For these reasons, FreeBSD provides a zone allocator (sometimes referred to as a slab allocator). The zone allocator provides an efficient interface for managing a collection of items of the same size and type [Bonwick, 1994; Bonwick & Adams, 2001]. The creation of separate zones runs counter to the desire to keep all memory in a single pool to maximize utilization efficiency. However, the benefits from segregating memory for the small set of structures for which the zone allocator is appropriate outweighs the efficiency gains from keeping them in the general pool. The zone allocator minimizes the impact of the separate pools by freeing memory from a zone based on a reduction in demand for objects from the zone and when notified of a memory shortage by the pageout daemon. A zone is an extensible collection of items of identical size. The zone allocator keeps track of the active and free items and provides functions for allocating items from the zone and for releasing them back to make them available for later use. Memory is allocated to the zone as necessary. Items in the pool are type stable. The memory in the pool will not be used for any other purpose. A structure in the pool need only be initialized on its first use. Later uses may assume that the initialized values will retain their contents as of the previous free. A callback is provided before memory is freed from the zone to allow any persistent state to be cleaned up. A new zone is created with the uma_zcreate() function. It must specify the size of the items to be allocated and register two sets of functions. The first set is called whenever an item is allocated or freed from the zone. They typically track the number of allocated items. The second set is called whenever memory is allocated or freed from the zone. They provide hooks for initializing or destroying substructures within the items such as locks or mutexes when they are first allocated or are about to be freed. Items are allocated with uma_zalloc(), which takes a zone identifier returned by uma_zcreate(). Items are freed with uma_zfree(), which takes a zone identifier and a pointer to the item to be freed. No size is needed when allocating or freeing, since the item size was set when the zone was created. To aid performance on multiprocessor systems, a zone may be backed by pages from the per-CPU caches of each of the processors for objects that are likely to have processor affinity. For example, if a particular process is likely to be run on the same CPU, then it would be sensible to allocate its structure from the cache for that CPU. The zone allocator provides the uma_zone_set_max() function to set the upper limit of items in the zone. The limit on the total number of items in the zone includes the allocated and free items, including the items in the per-CPU caches. On multiprocessor systems, it may not be possible to allocate a new item for a particular CPU because the limit has been hit and all the free items are in the caches of the other CPUs. |