8.3. Naming Filesystems contain files, most of which contain ordinary data. Certain files are distinguished as directories and contain pointers to files that may themselves be directories. This hierarchy of directories and files is organized into a tree structure; Figure 8.5 (on page 308) shows a small filesystem tree. Each of the circles in the figure represents an inode with its corresponding inode number inside. Each of the arrows represents a name in a directory. For example, inode 4 is the /usr directory with entry ., which points to itself, and entry .., which points to its parent, inode 2, the root of the filesystem. It also contains the name bin, which references directory inode 7, and the name foo, which references file inode 6. Figure 8.5. A small filesystem tree. 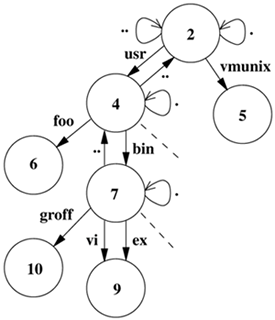
Directories Directories are allocated in units called chunks; Figure 8.5 shows a typical directory chunk. The size of a chunk is chosen such that each allocation can be transferred to disk in a single operation. The ability to change a directory in a single operation makes directory updates atomic. Chunks are broken up into variable-length directory entries to allow filenames to be of nearly arbitrary length. No directory entry can span multiple chunks. The first four fields of a directory entry are of fixed length and contain the following: The inode number, an index into a table of on-disk inode structures; the selected entry describes the file (inodes were described in Section 8.2) The size of the entry in bytes The type of the entry The length of the filename contained in the entry in bytes
The remainder of an entry is of variable length and contains a null-terminated filename padded to a 4-byte boundary. The maximum length of a filename in a directory is 255 characters. The filesystem records free space in a directory by having entries accumulate the free space in their size fields. Thus, some directory entries are larger than required to hold the entry name plus fixed-length fields. Space allocated to a directory should always be accounted for completely by the total of the sizes of the directory's entries. When an entry is deleted from a directory, the system coalesces the entry's space into the previous entry in the same directory chunk by increasing the size of the previous entry by the size of the deleted entry. If the first entry of a directory chunk is free, then the pointer to the entry's inode is set to zero to show that the entry is unallocated. Figure 8.6. Format of directory chunks. 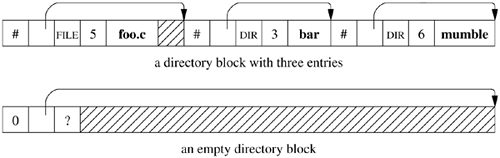
When creating a new directory entry, the kernel must scan the entire directory to ensure that the name does not already exist. While doing this scan it also checks each directory block to see if it has enough space in which to put the new entry. The space need not be contiguous. The kernel will compact the valid entries within a directory block to coalesce several small unused spaces together into a single space that is big enough to hold the new entry. The first block that has enough space is used. The kernel will neither compact space across directory blocks nor create an entry that spans two directory blocks as it always wants to be able to do directory updates by writing a single directory block. If no space is found when scanning the directory, a new block is allocated at the end of the directory. Applications obtain chunks of directories from the kernel by using the getdirentries system call. For the local filesystem, the on-disk format of directories is identical to that expected by the application, so the chunks are returned uninterpreted. When directories are read over the network or from non-BSD filesystems, such as Apple's HFS, the getdirentries system call has to convert the on-disk representation of the directory to that described. Normally, programs want to read directories one entry at a time. This interface is provided by the directory-access routines. The opendir() function returns a structure pointer that is used by readdir() to get chunks of directories using getdirentries; readdir() returns the next entry from the chunk on each call. The closedir() function deallocates space allocated by opendir() and closes the directory. In addition, there is the rewinddir() function to reset the read position to the beginning, the telldir() function that returns a structure describing the current directory position, and the seekdir() function that returns to a position previously obtained with telldir(). The UFS1 filesystem uses 32-bit inode numbers. While it is tempting to increase these inode numbers to 64 bits in UFS2, doing so would require that the directory format be changed. There is much code that works directly on directory entries. Changing directory formats would entail creating many more filesystemspecific functions that would increase the complexity and maintainability issues with the code. Furthermore, the current APIs for referencing directory entries use 32-bit inode numbers. So even if the underlying filesystem supported 64-bit inode numbers, they could not currently be made visible to user applications. In the short term, applications are not running into the 4 billion-files-per-filesystem limit that 32-bit inode numbers impose. If we assume that the growth rate in the number of files per filesystem over the last 20 years will continue at the same rate, we estimate that the 32-bit inode number should be enough for another 10 to 20 years. However, the limit will be reached before the 64-bit block limit of UFS2 is reached, so the UFS2 filesystem has reserved a flag in the superblock to show that it is a filesystem with 64-bit inode numbers. When the time comes to begin using 64-bit inode numbers, the flag can be turned on and the new directory format can be used. Kernels that predate the introduction of 64-bit inode numbers check this flag and will know that they cannot mount such filesystems. Finding of Names in Directories A common request to the filesystem is to lookup a specific name in a directory. The kernel usually does the lookup by starting at the beginning of the directory and going through, comparing each entry in turn. First, the length of the sought-after name is compared with the length of the name being checked. If the lengths are identical, a string comparison of the name being sought and the directory entry is made. If they match, the search is complete; if they fail, either in the length or in the string comparison, the search continues with the next entry. Whenever a name is found, its name and containing directory are entered into the systemwide name cache described in Section 6.6. Whenever a search is unsuccessful, an entry is made in the cache showing that the name does not exist in the particular directory. Before starting a directory scan, the kernel looks for the name in the cache. If either a positive or negative entry is found, the directory scan can be avoided. Another common operation is to lookup all the entries in a directory. For example, many programs do a stat system call on each name in a directory in the order that the names appear in the directory. To improve performance for these programs, the kernel maintains the directory offset of the last successful lookup for each directory. Each time that a lookup is done in that directory, the search is started from the offset at which the previous name was found (instead of from the beginning of the directory). For programs that step sequentially through a directory with n files, search time decreases from Order(n2) to Order(n). One quick benchmark that demonstrates the maximum effectiveness of the cache is running the ls -l command on a directory containing 600 files. On a system that retains the most recent directory offset, the amount of system time for this test is reduced by 85 percent. Unfortunately, the maximum effectiveness is much greater than the average effectiveness. Although the cache is 90 percent effective when hit, it is applicable to only about 25 percent of the names being looked up. Despite the amount of time spent in the lookup routine itself decreasing substantially, the improvement is diminished because more time is spent in the routines that that routine calls. Each cache miss causes a directory to be accessed twice once to search from the middle to the end and once to search from the beginning to the middle. These caches provide good directory lookup performance but are ineffective for large directories that have a high rate of entry creation and deletion. Each time a new directory entry is created, the kernel must scan the entire directory to ensure that the entry does not already exist. When an existing entry is deleted, the kernel must scan the directory to find the entry to be removed. For directories with many entries these linear scans are time-consuming. The approach to solving this problem in FreeBSD 5.2 is to introduce dynamic directory hashing that retrofits a directory indexing system to UFS [Dowse & Malone, 2002]. To avoid repeated linear searches of large directories, the dynamic directory hashing builds a hash table of directory entries on the fly when the directory is first accessed. This table avoids directory scans on later lookups, creates, and deletes. Unlike filesystems originally designed with large directories in mind, these indices are not saved on disk and so the system is backward compatible. The drawback is that the indices need to be built the first time that a large directory is encountered after each system reboot. The effect of the dynamic directory hashing is that large directories in UFS cause minimal performance problems. When we built UFS2, we contemplated solving the large directory update problem by changing to a more complex directory structure such as one that uses B-trees. This technique is used in many modern filesystems such as XFS [Sweeney et al., 1996], JFS [Best & Kleikamp, 2003], ReiserFS [Reiser, 2001], and in later versions of Ext2 [Phillips, 2001]. We decided not to make the change at the time that UFS2 was first implemented for several reasons. First, we had limited time and resources, and we wanted to get something working and stable that could be used in the time frame of FreeBSD 5.2. By keeping the same directory format, we were able to reuse all the directory code from UFS1, did not have to change numerous filesystem utilities to understand and maintain a new directory format, and were able to produce a stable and reliable filesystem in the time frame available to us. The other reason that we felt that we could retain the existing directory structure is because of the dynamic directory hashing that was added to FreeBSD. Borrowing the technique used by the Ext2 filesystem a flag was also added to show that an on-disk indexing structure is supported for directories [Phillips, 2001]. This flag is unconditionally turned off by the existing implementation of UFS. In the future, if an implementation of an on-disk directory-indexing structure is added, the implementations that support it will not turn the flag off. Index-supporting kernels will maintain the indices and leave the flag on. If an old non-index-supporting kernel is run, it will turn off the flag so that when the filesystem is once again run under a new kernel, the new kernel will discover that the indexing flag has been turned off and will know that the indices may be out date and have to be rebuilt before being used. The only constraint on an implementation of the indices is that they have to be an auxiliary data structure that references the old linear directory format. Pathname Translation We are now ready to describe how the filesystem looks up a pathname. The small filesystem introduced in Figure 8.5 is expanded to show its internal structure in Figure 8.7. Each of the files in Figure 8.5 is shown expanded into its constituent inode and data blocks. As an example of how these data structures work, consider how the system finds the file /usr/bin/vi. It must first search the root directory of the filesystem to find the directory usr. It first finds the inode that describes the root directory. By convention, inode 2 is always reserved for the root directory of a filesystem; therefore, the system finds and brings inode 2 into memory. This inode shows where the data blocks are for the root directory. These data blocks must also be brought into memory so that they can be searched for the entry usr. Having found the entry for usr, the system knows that the contents of usr are described by inode 4. Returning once again to the disk, the system fetches inode 4 to find where the data blocks for usr are located. Searching these blocks, it finds the entry for bin. The bin entry points to inode 7. Next, the system brings in inode 7 and its associated data blocks from the disk to search for the entry for vi. Having found that vi is described by inode 9, the system can fetch this inode and the blocks that contain the vi binary. Figure 8.7. Internal structure of a small filesystem. 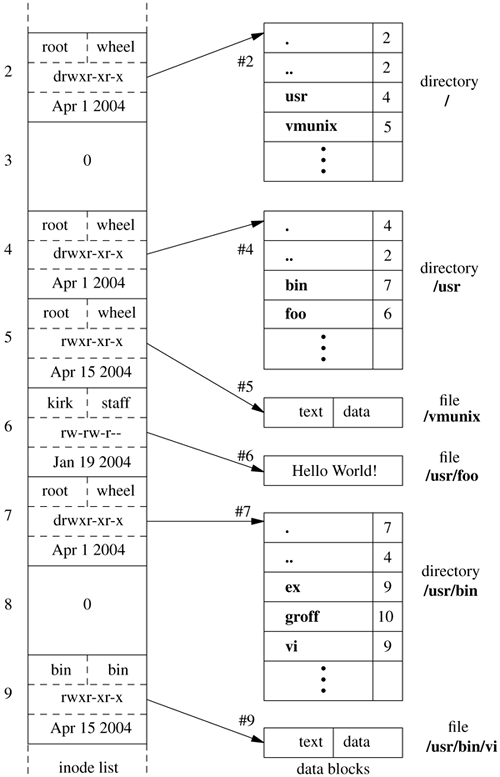
Links As shown in Figure 8.8, each file has a single inode, but multiple directory entries in the same filesystem may reference that inode (i.e., the inode may have multiple names). Each directory entry creates a hard link of a filename to the inode that describes the file's contents. The link concept is fundamental; inodes do not reside in directories but exist separately and are referenced by links. When all the links to an inode are removed, the inode is deallocated. If one link to a file is removed and the filename is recreated with new contents, the other links will continue to point to the old inode. Figure 8.8 shows two different directory entries, foo and bar, that reference the same file; thus, the inode for the file shows a reference count of 2. Figure 8.8. Hard links to a file. 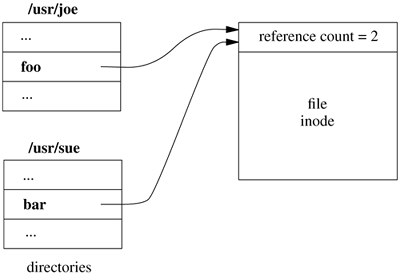
The system also supports a symbolic link, or soft link. A symbolic link is implemented as a file that contains a pathname. When the system encounters a symbolic link while looking up a component of a pathname, the contents of the symbolic link are prepended to the rest of the pathname; the lookup continues with the resulting pathname. If a symbolic link contains an absolute pathname, that absolute pathname is used. Otherwise, the contents of the symbolic link are evaluated relative to the location of the link in the file hierarchy (not relative to the current working directory of the calling process). A symbolic link is illustrated in Figure 8.9. Here, there is a hard link, foo, that points to the file. The other reference, bar, points to a different inode whose contents are a pathname of the referenced file. When a process opens bar, the system interprets the contents of the symbolic link as a pathname to find the file the link references. Symbolic links are treated like data files by the system, rather than as part of the filesystem structure; thus, they can point at directories or files on other filesystems. If a filename is removed and replaced, any symbolic links that point to it will access the new file. Finally, if the filename is not replaced, the symbolic link will point at nothing, and any attempt to access it will return an error. Figure 8.9. Symbolic link to a file. 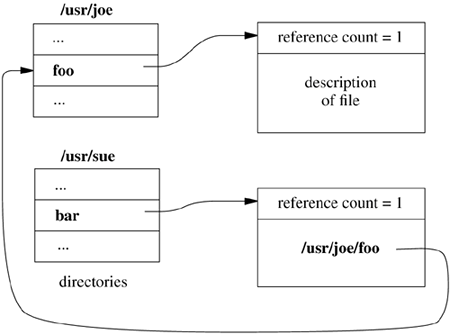
When open is applied to a symbolic link, it returns a file descriptor for the file pointed to, not for the link itself. Otherwise, it would be necessary to use indirection to access the file pointed to and that file, rather than the link, is what is usually wanted. For the same reason, most other system calls that take pathname arguments also follow symbolic links. Sometimes, it is useful to be able to detect a symbolic link when traversing a filesystem or when making an archive tape. So the lstat system call is available to get the status of a symbolic link, instead of the object at which that link points. A symbolic link has several advantages over a hard link. Since a symbolic link is maintained as a pathname, it can refer to a directory or to a file on a different filesystem. So that loops in the filesystem hierarchy are prevented, unprivileged users are not permitted to create hard links (other than . and ..) that refer to a directory. The design of hard links prevents them from referring to files on a different filesystem. There are several interesting implications of symbolic links. Consider a process that has current working directory /usr/keith and does cd src, where src is a symbolic link to directory /usr/src. If the process then does a cd .., the current working directory for the process will be in /usr instead of in /usr/keith, as it would have been if src was a normal directory instead of a symbolic link. The kernel could be changed to keep track of the symbolic links that a process has traversed and to interpret .. differently if the directory has been reached through a symbolic link. There are two problems with this implementation. First, the kernel would have to maintain a potentially unbounded amount of information. Second, no program could depend on being able to use .., since it could not be sure how the name would be interpreted. Many shells keep track of symbolic-link traversals. When the user changes directory through .. from a directory that was entered through a symbolic link, the shell returns the user to the directory from which they came. Although the shell might have to maintain an unbounded amount of information, the worst that will happen is that the shell will run out of memory. Having the shell fail will affect only the user silly enough to traverse endlessly through symbolic links. Tracking of symbolic links affects only change-directory commands in the shell; programs can continue to depend on .. to reference its true parent. Thus, tracking symbolic links outside the kernel in a shell is reasonable. Since symbolic links may cause loops in the filesystem, the kernel prevents looping by allowing at most eight symbolic link traversals in a single pathname translation. If the limit is reached, the kernel produces an error (ELOOP). |