Section 3.1. Fundamentals
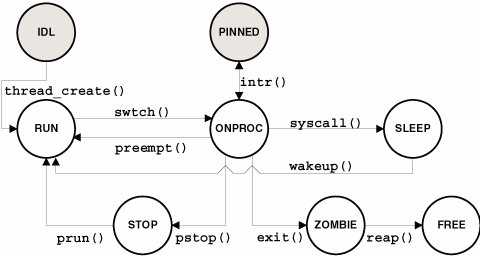
3.1. FundamentalsThe kernel dispatcher is the code that places runnable threads on a dispatch queue (run queue), selects the next thread to run on a processor, and manages the switching of threads on and off processors. A thread's priority determines how soon it will run, and the kernel implements a global priority scheme that selects the highest-priority runnable thread from all other runnable threads at any time. Every thread is in one of several possible scheduling classes; this arrangement determines the range of priorities for the thread, as well as which class-specific scheduling algorithms will be applied as the thread goes through its state transitions. By and large, the life cycle of a thread is typically spent in the ready-to-run (RUN) state, running (ONPROC) state, and waiting-for-an-event (SLEEP) state. A thread's transition between these states in managed largely by the dispatcher. The PINNED and IDL states in the figure are represented in shaded circles because they are not technically thread states. The states are defined as follows. /* * Values that t_state may assume. Note that t_state cannot have more * than one of these flags set at a time. */ #define TS_FREE 0x00 /* Thread at loose ends */ #define TS_SLEEP 0x01 /* Awaiting an event */ #define TS_RUN 0x02 /* Runnable, but not yet on a processor */ #define TS_ONPROC 0x04 /* Thread is being run on a processor */ #define TS_ZOMB 0x08 /* Thread has died but hasn't been reaped */ #define TS_STOPPED 0x10 /* Stopped, initial state */ See usr/src/uts/common/sys/thread.h IDL is a process state set when a process is created. A thread that is in the ONPROC state is pinned when the processor on which the thread is executing fields an interrupt. The processor switches to running an interrupt thread, temporarily moving aside (pinning) the thread that was running. This is discussed in Section 3.11. As Figure 3.1 suggests, the core of the dispatcher's work can be described as a queue management system. All threads in the RUN state reside on dispatch queues, and all threads in the SLEEP state reside on a sleep queue. The available processors on the system can also be thought of as a queue of resources (execution resources in this case). Thus, we can summarize the core functions of the dispatcher as follows:
Figure 3.1. Thread States Scheduling decisions and actions taken by the dispatcher code are either time based or event based. That is, some dispatcher functions occur synchronously at regular intervals, while others are asynchronous, originating at random times while the system is running. The time-based work is through the kernel clock interrupt mechanism and callout facility. By default, a clock interrupt occurs 100 times per second (every 10 milliseconds). The clock interrupt handler processes the running threads and determines their time quantum expiration. Also in the kernel callout queue are dispatcher kernel threads that execute at regular intervals. Events of interest to the dispatcher originate from many places: the creation of a new thread, thread wakeups, etc. Such events may require a thread preemption, which forces the dispatcher to remove a thread running on a processor to make the processor available to run a higher-priority thread. A detailed look at the time-based and event-based work performed by the dispatcher is just around the corner, so stay with us. Different workloads have different scheduling and execution requirements. By default, a Solaris system prioritizes and runs threads on a time-share basis, attempting to maintain an even distribution of processor resources among the threads. A Solaris desktop systema workstation or notebook computer running a windowing systemruns threads on a time-share basis as well but accords an extra priority boost for threads bound to active windows on the user's computer. This is done with the interactive scheduling class. Solaris implements several scheduling classes that constitute a powerful and flexible infrastructure for managing a variety of workloads by establishing the range of priorities a thread will be assigned, as well as which set of scheduling rules will apply. The following scheduling classes are integrated into Solaris 10:
For the dispatcher to make the appropriate scheduling decisions with thousands of threads at different priorities and scheduling classes, a global priority scheme is required. Every thread has a global priority, allowing the dispatcher to determine its position relative to all other threads on the system. In addition to priority, other conditions and configuration parameters factor into dispatcher scheduling decisions. These can be broadly categorized as resource management parameters and system architecture. Resource management refers to a set of technologies integrated into Solaris that provide the framework, tools, and utilities for allocating and managing different amounts of hardware resources. From the kernel dispatcher perspective, the effects on scheduling decisions have to do with some form of binding or affinity between processors and threads. The specific resource controls are listed below.
The second category, system architecture, refers to enhancements and optimizations made to the dispatcher code to account for the architectural nuances of the system. A good example of this is Memory Placement Optimization (MPO). MPO was introduced in Solaris 9; it mitigates the effects of systems with nonuniform memory access times by scheduling threads onto processors that are close to the thread's allocated physical memory. MPO is described in Kernel Support for NUMA and CMT Hardware. A second, and more recent, architectural consideration is chip technology. Specifically the implementation of chip multithreading (CMT) processors, which integrate multiple execution pipelines (cores) and multiple hardware threads per core on a single piece of silicon. Sun's UltraSPARC T1 processor is a CMT design, with eight execution pipelines and four hardware threads per pipeline. To the Solaris kernel, a single UltraSPARC T1 chip appears as 32 processors (8 cores times 4 hardware threads per coreeach hardware thread is viewed as a processor by the kernel dispatcher). The dispatcher has been modified to accommodate certain implementation details of the hardware design, such as the level of sharing of hardware resources among the cores (caches, data paths, etc.) to minimize contention, while at the same time maintaining cache warmth through judicious assignments of threads to cores. CMT is discussed in Chapter 16. The idea of placing unbound threads on the processor on which they last executed is not new. The kernel dispatcher implemented warm affinity as early as Solaris 2.5. The idea again is that a thread placed back on the same processor has a better probability of finding a warm cachea hardware cache that has some of the thread's instructions and data, thus reducing pipeline stalls for memory references. As we move through the remainder of this chapter, we explore the topics introduced here in greater detail:
|
EAN: 2147483647
Pages: 244
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Measuring ROI in E-Commerce Applications: Analysis to Action
- Governing Information Technology Through COBIT
- The Evolution of IT Governance at NB Power
- Governance Structures for IT in the Health Care Industry