Section 3.2. Processor Abstractions
|
|
3.2. Processor AbstractionsThe kernel dispatcher primarily manages two types of objects: threads and processors. Threads were discussed in the previous chapter. Before we probe the internals of the dispatcher, we need a clear view of how hardware processors (CPUs) are abstracted and a definition of what specific groupings of processors are maintained in the kernel. Previous releases of Solaris defined a cpu structure (cpu_t), and a one-to-one mapping existed between physical processors and instantiated cpu_t structures in the kernel. The cpu_t maintains information required by the dispatcher and kernel-at-large for thread scheduling, interrupt handling, CPU state transitions, utilization and accounting, processor groupings, and administrative controls (psradm(1M)). Processor resource control facilitiesprocessor sets and resource poolsare implemented through abstractions in the kernel that define groups of processors. Multicore processor technology and multiprocessor system designs introduced architectural considerations that require visibility by the kernel; thus, some new abstractions were needed for the kernel to take full advantage of new processors and systems. The following processor-related abstractions are defined and maintained in the kernel:
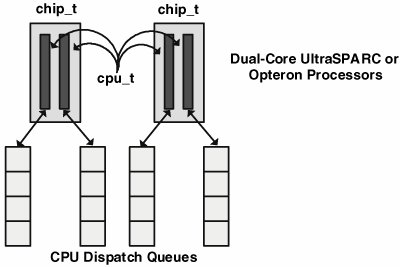
Figure 3.2. Chips and CPUs The chip_t object provides various structure members used by the dispatcher for load balancing, assigning chips into latency groups (lgroupsmore on that in a minute), maintaining per-chip statistics, and identifying an enumerated chip type that can be used to make scheduling decisions based on the shared resources implemented in the chip, for example, shared hardware caches. The chip types are enumerated below. typedef enum chip_type { CHIP_DEFAULT, /* Default, non CMT processor */ CHIP_SMT, /* SMT, single core */ CHIP_CMP_SPLIT_CACHE, /* CMP with split caches */ CHIP_CMP_SHARED_CACHE, /* CMP with shared caches */ CHIP_NUM_TYPES } chip_type_t; See usr/src/uts/common/sys/chip.h
You can determine the kernel's defined chip type for your system by using mdb(1). An UltraSPARC II-based system: # mdb -k > ::walk cpu |::print cpu_t cpu_chip |::print chip_t chip_type chip_type = 0 (CHIP_DEFAULT) chip_type = 0 (CHIP_DEFAULT) . . . chip_type = 0 (CHIP_DEFAULT) # prtdiag | more System Configuration: Sun Microsystems sun4u 8-slot Sun Enterprise 4000/5000 System clock frequency: 84 MHz Memory size: 4096Mb ========================= CPUs ========================= Run Ecache CPU CPU Brd CPU Module MHz MB Impl. Mask --- --- ------- ----- ------ ------ ---- 0 0 0 336 4.0 US-II 2.0 0 1 1 336 4.0 US-II 2.0 . . . A T2000 UltraSPARC T1 based system: # mdb -k > ::walk cpu |::print cpu_t cpu_chip |::print chip_t chip_type chip_type = 3 (CHIP_CMP_SHARED_CACHE) chip_type = 3 (CHIP_CMP_SHARED_CACHE) chip_type = 3 (CHIP_CMP_SHARED_CACHE) . . . # prtdiag | more System Configuration: Sun Microsystems sun4v Sun Fire T200 System clock frequency: 200 MHz Memory size: 32760 Megabytes ========================= CPUs =============================================== CPU CPU Location CPU Freq Implementation Mask ------------ ----- -------- ------------------- ----- MB/CMP0/P0 0 1200 MHz SUNW,UltraSPARC-T1 MB/CMP0/P1 1 1200 MHz SUNW,UltraSPARC-T1 . . . A CPU will belong to one of the CPU groupings listed here:
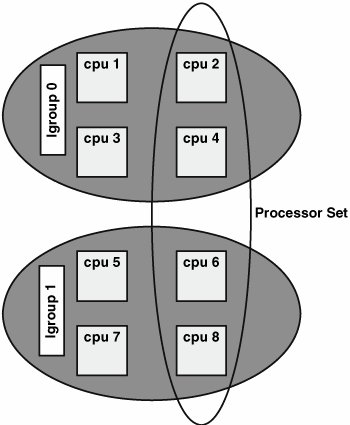
Note two sets of lgroup-related pointers, cpu_next_lgrp and cpu_next_lpl (and their respective prev pointers). An lgroup can be partitioned when the CPUs in the lgroup reside in different CPU partitions (processor sets). An lgroup partition partition represents the intersection of an lgroup and processor set, as shown in Figure 3.3. The scheduling implications of dealing with lgroup partitions is discussed in Section 3.9 Figure 3.3. Lgroup Partitions In Figure 3.3, CPUs 2, 4, 6, and 8 are in a user-created processor set spanning two lgroups. CPUs 2 and 4 would be on one cpu_[next|prev]_lpl list, and CPUs 6 and 8 on another. CPUs 2, 4, 6 and 8 would be linked togther on each cpu_[next|prev]_part list. CPUs 1, 2, 3, and 4 would be linked in the cpu_[next|prev]_lgrp pointer chain (as would CPUs 4, 5, 6, and 7). Maintaining multiple linked lists that reflect different group abstractions (partitions, lgroups, and lgroup partitions) simplifies operations from the dispatcher and the kernel-at-large that target a CPU group abstraction, such as determining the size and membership of a specific grouping of interest. For example, the dispatcher uses these lists to determine on what CPUs in a given lgroup a thread bound to a particular processor set could be legally scheduled to run on. The chip_t objects are also linked in several useful ways. typedef struct chip { chipid_t chip_id; /* chip's "id" */ chipid_t chip_seqid; /* sequential id */ struct chip *chip_prev; /* previous chip on list */ struct chip *chip_next; /* next chip on list */ struct chip *chip_prev_lgrp; /* prev chip in lgroup */ struct chip *chip_next_lgrp; /* next chip in lgroup */ chip_type_t chip_type; /* type of chip */ uint16_t chip_ncpu; /* number of active cpus */ uint16_t chip_ref; /* chip's reference count */ struct cpu *chip_cpus; /* per chip cpu list */ struct lgrp *chip_lgrp; /* chip lives in this lgroup */ ... See usr/src/uts/common/sys/chip.h A CPU can belong to only one partition and lgroup at any time. CPUs in the same lgroup can be part of different partitions (such as a user-defined processor set or resource pool). All the CPUs in a chip_t belong to the same lgroup as the chip. In Section 3.9, we walk through the process of selecting which CPU's dispatch queue a thread will be inserted on, given configured partitions and lgroups and the possibility of user-defined thread-to-CPU bindings. At the thread level, several fields in the thread_t structure maintain information on CPU bindings, the partition that contains the thread, and the thread's lgroup affinity. We examine the specific structure members in Section 3.9 as we go through the CPU selection algorithm. 3.2.1. Processor ObservabilityIn the next few pages we have examples of lgroup observability [1]how the CPUs and lgroup configurations can be determined, and tracking the execution of all the threads in a targetshowing which CPUs in which lgroups execute the threads.
Using mdb(1), we can examine a running system and determine which CPUs are members of which lgroups and partitions. Example from a Sun v40Z 4-way Opteron based system: > ::walk cpu |::print cpu_t cpu_lpl |::print lgrp_t lgrp_id lgrp_id = 0x1 lgrp_id = 0x2 lgrp_id = 0x3 lgrp_id = 0x4 Example from a Sun Fire T2000 8-core UltraSPARC T1 based system: > ::walk cpu |::print cpu_t cpu_lpl |::print lgrp_t lgrp_id lgrp_id = 0 lgrp_id = 0 ... lgrp_id = 0 lgrp_id = 0 Note in the Sun Fire T2000 example, most of the lines were cut for brevity. All 32 virtual CPUs are in the same lgroup (0) because the T2000 has a uniform memory access architecture. Here's a handy script created by Jon Haslam (author of the DTrace chapter in Solaris™ Perfarmance and Tools) that reports the lgroup of a particular process and dumps the CPUs and lgroups configured on the system. # cat getlgrp /usr/ucb/echo -n "PID $1 lgrp = " echo "0t$1::pid2proc | ::walk thread | ::print -t kthread_t t_lpl | \ ::print struct lgrp_ld lpl_lgrpid" | mdb -k echo echo "CPUs on system" echo "cpus::list cpu_t cpu_next | ::print cpu_t cpu_id" | mdb -k echo echo "... and their lgrps" echo "cpus::list cpu_t cpu_next | ::print -t struct cpu cpu_lpl | \ ::print -t struct lgrp_ld lpl_lgrpid" | mdb -k # ./getlgrp $$ PID 3321 lgrp = lpl_lgrpid = 0x1 CPUs on system cpu_id = 0 cpu_id = 0x1 cpu_id = 0x2 cpu_id = 0x3 ... and their lgrps lgrp_id_t lpl_lgrpid = 0x1 lgrp_id_t lpl_lgrpid = 0x2 lgrp_id_t lpl_lgrpid = 0x3 lgrp_id_t lpl_lgrpid = 0x4 The kernel maintains statistics on lgroups through the kstats framework, and these can be examined on a running system to track load, migrations (number of times a thread was migrated to the lgroup), and memory events. # kstat -m lgrp -n lgrp4 module: lgrp instance: 4 name: lgrp4 class: misc alloc fail 2 cpus 1 crtime 252.646499713 default policy 0 load average 65516 lwp migrations 44 next-touch policy 119290 pages avail 2097152 pages failed to mark 0 pages failed to migrate from 0 pages failed to migrate to 0 pages free 2078708 pages installed 2097152 pages marked for migration 0 pages migrated from 0 pages migrated to 0 random policy 15584 round robin policy 0 snaptime 679637.602945989 span process policy 0 span psrset policy 0 And, of course, we can use DTrace to track which CPUs and lgrps the thread was scheduled on: #!/usr/sbin/dtrace -qs sched:::on-cpu / pid == $1/ { self->lgrp = curthread->t_cpu->cpu_chip->chip_lgrp->lgrp_id; @[tid,self->lgrp,cpu]=count(); } END { printf("Threads CPUs and lgrps for PID %d\n",pid); printf("%-8s %-8s %-8s %-8s\n","TID","LGRP","CPUID","COUNT"); printf("==================================\n"); printa("%-8d %-8d %-8d %-@8d\n",@); } # ./lgrp.d 3416 ^C Threads CPUs and lgrps for PID 3416 TID LGRP CPUID COUNT ================================== 1 2 1 1 2 2 1 1014 5 3 2 1149 4 3 2 1193 3 2 1 1313 3 1 0 1460 3 3 2 1465 5 4 3 1820 2 1 0 1898 . . . The D script above was saved in a file called lgrp.d and executed to track process 3416. The aggregation shows the number of times (COUNT) a given thread (TID) executed on a particular CPU and lgroup. We can see from the output that each thread is getting a respectable number of runs on a given CPU, but some migration is also happening, likely the result of load balancing by the dispatcher. |
|
|
EAN: 2147483647
Pages: 244