22.3. Bag of Testing Tricks
| < Free Open Study > |
| Why isn't it possible to prove that a program is correct by testing it? To use testing to prove that a program works, you'd have to test every conceivable input value to the program and every conceivable combination of input values. Even for simple programs, such an undertaking would become massively prohibitive. Suppose, for example, that you have a program that takes a name, an address, and a phone number and stores them in a file. This is certainly a simple program, much simpler than any whose correctness you'd really be worried about. Suppose further that each of the possible names and addresses is 20 characters long and that there are 26 possible characters to be used in them. This would be the number of possible inputs:
Even with this relatively small amount of input, you have one-with-66-zeros possible test cases. To put this in perspective, if Noah had gotten off the ark and started testing this program at the rate of a trillion test cases per second, he would be far less than 1 percent of the way done today. Obviously, if you added a more realistic amount of data, the task of exhaustively testing all possibilities would become even more impossible. Incomplete TestingSince exhaustive testing is impossible, practically speaking, the art of testing is that of picking the test cases most likely to find errors. Of the 1066 possible test cases, only a few are likely to disclose errors that the others don't. You need to concentrate on picking a few that tell you different things rather than a set that tells you the same thing over and over. Cross-Reference One way of telling whether you've covered all the code is to use a coverage monitor. For details, see "Coverage Monitors" in Section 22.5, "Test-Support Tools," later in this chapter. When you're planning tests, eliminate those that don't tell you anything new that is, tests on new data that probably won't produce an error if other, similar data didn't produce an error. Various people have proposed various methods of covering the bases efficiently, and several of these methods are discussed in the following sections. Structured Basis TestingIn spite of the hairy name, structured basis testing is a fairly simple concept. The idea is that you need to test each statement in a program at least once. If the statement is a logical statement an if or a while, for example you need to vary the testing according to how complicated the expression inside the if or while is to make sure that the statement is fully tested. The easiest way to make sure that you've gotten all the bases covered is to calculate the number of paths through the program and then develop the minimum number of test cases that will exercise every path through the program. You might have heard of "code coverage" testing or "logic coverage" testing. They are approaches in which you test all the paths through a program. Since they cover all paths, they're similar to structured basis testing, but they don't include the idea of covering all paths with a minimal set of test cases. If you use code coverage or logic coverage testing, you might create many more test cases than you would need to cover the same logic with structured basis testing. Cross-Reference This procedure is similar to the one for measuring complexity in "How to Measure Complexity" in Section 19.6. You can compute the minimum number of cases needed for basis testing in this straightforward way:
Here's an example: Simple Example of Computing the Number of Paths Through a Java ProgramStatement1; <-- 1 Statement2; if ( x < 10 ) { <-- 2 Statement3; } Statement4;
In this instance, you start with one and count the if once to make a total of two. That means that you need to have at least two test cases to cover all the paths through the program. In this example, you'd need to have the following test cases:
The sample code needs to be a little more realistic to give you an accurate idea of how this kind of testing works. Realism in this case includes code containing defects.  The following listing is a slightly more complicated example. This piece of code is used throughout the chapter and contains a few possible errors. Example of Computing the Number of Cases Needed for Basis Testing of a Java Program1 // Compute Net Pay <-- 1 2 totalWithholdings = 0; 3 4 for ( id = 0; id < numEmployees; id++ ) { <-- 2 5 6 // compute social security withholding, if below the maximum 7 if ( m_employee[ id ].governmentRetirementWithheld < MAX_GOVT_RETIREMENT ) { <-- 3 8 governmentRetirement = ComputeGovernmentRetirement( m_employee[ id ] ); 9 } 10 11 // set default to no retirement contribution 12 companyRetirement = 0; 13 14 // determine discretionary employee retirement contribution 15 if ( m_employee[ id ].WantsRetirement && <-- 4 16 EligibleForRetirement( m_employee[ id ] ) ) { 17 companyRetirement = GetRetirement( m_employee[ id ] ); 18 } 19 20 grossPay = ComputeGrossPay ( m_employee[ id ] ); 21 22 // determine IRA contribution 23 personalRetirement = 0; 24 if ( EligibleForPersonalRetirement( m_employee[ id ] ) ) { <-- 5 25 personalRetirement = PersonalRetirementContribution( m_employee[ id ], 26 companyRetirement, grossPay ); 27 } 28 29 // make weekly paycheck 30 withholding = ComputeWithholding( m_employee[ id ] ); 31 netPay = grossPay - withholding - companyRetirement - governmentRetirement - 32 personalRetirement; 33 PayEmployee( m_employee[ id ], netPay ); 34 35 // add this employee's paycheck to total for accounting 36 totalWithholdings = totalWithholdings + withholding; 37 totalGovernmentRetirement = totalGovernmentRetirement + governmentRetirement; 38 totalRetirement = totalRetirement + companyRetirement; 39 } 40 41 SavePayRecords( totalWithholdings, totalGovernmentRetirement, totalRetirement );
In this example, you'll need one initial test case plus one for each of the five keywords, for a total of six. That doesn't mean that any six test cases will cover all the bases. It means that, at a minimum, six cases are required. Unless the cases are constructed carefully, they almost surely won't cover all the bases. The trick is to pay attention to the same keywords you used when counting the number of cases needed. Each keyword in the code represents something that can be either true or false; make sure you have at least one test case for each true and at least one for each false. Here is a set of test cases that covers all the bases in this example:
If the routine were much more complicated than this, the number of test cases you'd have to use just to cover all the paths would increase pretty quickly. Shorter routines tend to have fewer paths to test. Boolean expressions without a lot of ands and ors have fewer variations to test. Ease of testing is another good reason to keep your routines short and your boolean expressions simple. Now that you've created six test cases for the routine and satisfied the demands of structured basis testing, can you consider the routine to be fully tested? Probably not. This kind of testing assures you only that all of the code will be executed. It does not account for variations in data. Data-Flow TestingConsidering the last section and this one together gives you another example illustrating that control flow and data flow are equally important in computer programming. Data-flow testing is based on the idea that data usage is at least as error-prone as control flow. Boris Beizer claims that at least half of all code consists of data declarations and initializations (Beizer 1990). Data can exist in one of three states:
In addition to having the terms "defined," "used," and "killed," it's convenient to have terms that describe entering or exiting a routine immediately before or after doing something to a variable:
Combinations of Data StatesThe normal combination of data states is that a variable is defined, used one or more times, and perhaps killed. View the following patterns suspiciously:
Check for these anomalous sequences of data states before testing begins. After you've checked for the anomalous sequences, the key to writing data-flow test cases is to exercise all possible defined-used paths. You can do this to various degrees of thoroughness, including
Here's an example: Java Example of a Program Whose Data Flow Is to Be Testedif ( Condition 1 ) { x = a; } else { x = b; } if ( Condition 2 ) { y = x + 1; } else { y = x - 1; }To cover every path in the program, you need one test case in which Condition 1 is true and one in which it's false. You also need a test case in which Condition 2 is true and one in which it's false. This can be handled by two test cases: Case 1 (Condition 1=True, Condition 2=True) and Case 2 (Condition 1=False, Condition 2=False). Those two cases are all you need for structured basis testing. They're also all you need to exercise every line of code that defines a variable; they give you the weak form of data-flow testing automatically. To cover every defined-used combination, however, you need to add a few more cases. Right now you have the cases created by having Condition 1 and Condition 2 true at the same time and Condition 1 and Condition 2 false at the same time: x = a ... y = x + 1 and x = b ... y = x - 1 But you need two more cases to test every defined-used combination: (1) x = a and then y = x - 1 and (2) x = b and then y = x + 1. In this example, you can get these combinations by adding two more cases: Case 3 (Condition 1=True, Condition 2=False) and Case 4 (Condition 1=False, Condition 2=True). A good way to develop test cases is to start with structured basis testing, which gives you some if not all of the defined-used data flows. Then add the cases you still need to have a complete set of defined-used data-flow test cases. As discussed in the previous section, structured basis testing provided six test cases for the routine beginning on page 507. Data-flow testing of each defined-used pair requires several more test cases, some of which are covered by existing test cases and some of which aren't. Here are all the data-flow combinations that add test cases beyond the ones generated by structured basis testing:
Once you run through the process of listing data-flow test cases a few times, you'll get a sense of which cases are fruitful and which are already covered. When you get stuck, list all the defined-used combinations. That might seem like a lot of work, but it's guaranteed to show you any cases that you didn't test for free in the basis-testing approach. Equivalence PartitioningA good test case covers a large part of the possible input data. If two test cases flush out exactly the same errors, you need only one of them. The concept of "equivalence partitioning" is a formalization of this idea and helps reduce the number of test cases required. Cross-Reference Equivalence partitioning is discussed in far more depth in the books listed in the "Additional Resources" section at the end of this chapter. In the listing beginning on page 507, line 7 is a good place to use equivalence partitioning. The condition to be tested is m_employee[ ID ].governmentRetirementWithheld < MAX_GOVT_RETIREMENT. This case has two equivalence classes: the class in which m_employee[ ID ].governmentRetirementWithheld is less than MAX_GOVT_RETIREMENT and the class in which it's greater than or equal to MAX_GOVT_RETIREMENT. Other parts of the program might have other related equivalence classes that imply that you need to test more than two possible values of m_employee[ ID ].governmentRetirementWithheld, but as far as this part of the program is concerned, only two are needed. Thinking about equivalence partitioning won't give you a lot of new insight into a program when you have already covered the program with basis and data-flow testing. It's especially helpful, however, when you're looking at a program from the outside (from a specification rather than the source code) or when the data is complicated and the complications aren't all reflected in the program's logic. Error GuessingIn addition to the formal test techniques, good programmers use a variety of less formal, heuristic techniques to expose errors in their code. One heuristic is the technique of error guessing. The term "error guessing" is a lowbrow name for a sensible concept. It means creating test cases based upon guesses about where the program might have errors, although it implies a certain amount of sophistication in the guessing. Cross-Reference For details on heuristics, see Section 2.2, "How to Use Software Metaphors." You can base guesses on intuition or on past experience. Chapter 21, "Collaborative Construction," points out that one virtue of inspections is that they produce and maintain a list of common errors. The list is used to check new code. When you keep records of the kinds of errors you've made before, you improve the likelihood that your "error guess" will discover an error. The next few sections describe specific kinds of errors that lend themselves to error guessing. Boundary AnalysisOne of the most fruitful areas for testing is boundary conditions off-by-one errors. Saying num 1 when you mean num and saying >= when you mean > are common mistakes. The idea of boundary analysis is to write test cases that exercise the boundary conditions. Pictorially, if you're testing for a range of values that are less than max, you have three possible conditions: 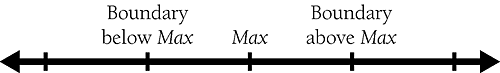 As shown, there are three boundary cases: just less than max, max itself, and just greater than max. It takes three cases to ensure that none of the common mistakes has been made. The code sample on page 507 contains a check for m_employee[ ID ].governmentRetirementWithheld < MAX_GOVT_RETIREMENT. According to the principles of boundary analysis, three cases should be examined:
Compound BoundariesBoundary analysis also applies to minimum and maximum allowable values. In this example, it might be minimum or maximum grossPay, companyRetirement, or PersonalRetirementContribution, but because calculations of those values are outside the scope of the routine, test cases for them aren't discussed further here. A more subtle kind of boundary condition occurs when the boundary involves a combination of variables. For example, if two variables are multiplied together, what happens when both are large positive numbers? Large negative numbers? 0? What if all the strings passed to a routine are uncommonly long? In the running example, you might want to see what happens to the variables totalWithholdings, totalGovernmentRetirement, and totalRetirement when every member of a large group of employees has a large salary say, a group of programmers at $250,000 each. (We can always hope!) This calls for another test case:
A test case in the same vein but on the opposite side of the looking glass would be a small group of employees, each of whom has a salary of $0.00:
Classes of Bad DataAside from guessing that errors show up around boundary conditions, you can guess about and test for several other classes of bad data. Typical bad-data test cases include
Some of the test cases you would think of if you followed these suggestions have already been covered. For example, "too little data" is covered by Cases 2 and 12, and it's hard to come up with anything for "wrong size of data." Classes of bad data nonetheless gives rise to a few more cases:
Classes of Good DataWhen you try to find errors in a program, it's easy to overlook the fact that the nominal case might contain an error. Usually the nominal cases described in the basis-testing section represent one kind of good data. Following are other kinds of good data that are worth checking. Checking each of these kinds of data can reveal errors, depending on the item being tested.
The minimum normal configuration is useful for testing not just one item, but a group of items. It's similar in spirit to the boundary condition of many minimal values, but it's different in that it creates the set of minimum values out of the set of what is normally expected. One example would be to save an empty spreadsheet when testing a spreadsheet. For testing a word processor, it would be saving an empty document. In the case of the running example, testing the minimum normal configuration would add the following test case:
The maximum normal configuration is the opposite of the minimum. It's similar in spirit to boundary testing, but again, it creates a set of maximum values out of the set of expected values. An example of this would be saving a spreadsheet that's as large as the "maximum spreadsheet size" advertised on the product's packaging. Or printing the maximum-size spreadsheet. For a word processor, it would be saving a document of the largest recommended size. In the case of the running example, testing the maximum normal configuration depends on the maximum normal number of employees. Assuming it's 500, you would add the following test case:
The last kind of normal data testing testing for compatibility with old data comes into play when the program or routine is a replacement for an older program or routine. The new routine should produce the same results with old data that the old routine did, except in cases in which the old routine was defective. This kind of continuity between versions is the basis for regression testing, the purpose of which is to ensure that corrections and enhancements maintain previous levels of quality without backsliding. In the case of the running example, the compatibility criterion wouldn't add any test cases. Use Test Cases That Make Hand-Checks ConvenientLet's suppose you're writing a test case for a nominal salary; you need a nominal salary, and the way you get one is to type in whatever numbers your hands land on. I'll try it: 1239078382346 OK. That's a pretty high salary, a little over a trillion dollars, in fact, but if I trim it so that it's somewhat realistic, I get $90,783.82. Now, further suppose that the test case succeeds that is, it finds an error. How do you know that it's found an error? Well, presumably, you know what the answer is and what it should be because you calculated the correct answer by hand. When you try to do hand-calculations with an ugly number like $90,783.82, however, you're as likely to make an error in the hand-calc as you are to discover one in your program. On the other hand, a nice, even number like $20,000 makes number crunching a snap. The 0s are easy to punch into the calculator, and multiplying by 2 is something most programmers can do without using their fingers and toes. You might think that an ugly number like $90,783.82 would be more likely to reveal errors, but it's no more likely to than any other number in its equivalence class. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 1066
1066| < Free Open Study > |
EAN: 2147483647
Pages: 334
- Integration Strategies and Tactics for Information Technology Governance
- Linking the IT Balanced Scorecard to the Business Objectives at a Major Canadian Financial Group
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- The Evolution of IT Governance at NB Power
- Governance Structures for IT in the Health Care Industry