Examples of Commercial Operations Managers
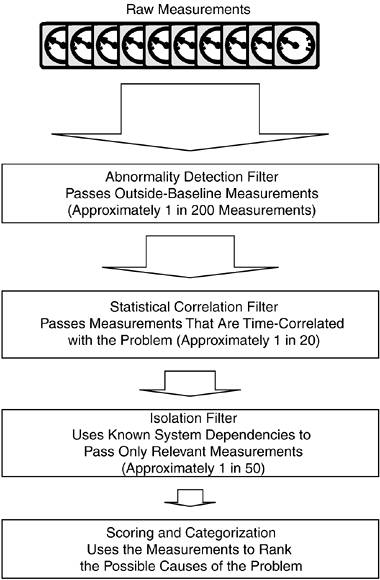
| There's a growing set of new technologies with a range of approaches to finding the root-cause of a service problem. Examples discussed here are tools from Tavve, ProactiveNet, and Netuitive, along with two specialized tools from Arbor Networks and NetScaler that handle Distributed Denial of Service (DDoS) attacks. There are many other tools available, of course. Among them are tools from Identify Software, OC Systems, Micromuse, Computer Associates, Tivoli, and Mercury Interactive, among others. Tavve Software's EventWatchTavve Software has a root-cause tool that is focused on Layer 2 connectivity; it builds a topology model with the connectivity relationships included. When an alert is received, Tavve EventWatch first verifies that a performance or availability problem exists. (In many cases, an element will have been temporarily marked "down" by instrumentation just because a single probe of that element failedpossibly because a brief spike in network congestion temporarily interfered with access.) EventWatch uses active tests, or synthetic transactions, to measure the same response several times in a row. If it determines that a problem actually exists, persisting beyond a brief period, the topology model is then used to determine a root-cause. The EventWatch software uses the topology model to traverse the paths from the active collector to the target server. It has information about each element in the path and it conducts more detailed measurements to assess each element's health. A failure or overload is detected quickly. If it discovers that all elements subordinate to a single key element have failed and that the key element is also unavailable, it quickly reports failure of the key element instead of producing a large number of individual, uncorrelated reports of subordinate element failures. EventWatch has the capability to detect topology changes and incorporate them into the topology model. The logic for traversing the possible paths and checking each element is straightforward and leads to quick root-cause detection. ProactiveNetProactiveNet was an early player in the active monitoring and management of complex e-business infrastructures. ProactiveNet bases its approach on statistical quality control principles. It uses sampling and analysis to track behavioral shifts and identify root causes. Sampling is more efficient than measuring everything all of the time. The key is selecting the variables to sample; they should be ones whose changes are the most influential. (Netuitive, discussed later, uses a similar approach with its "strongly correlated variables.") The sampling interval is a basic parameter that determines the granularityevery five minutes, for example. The trade-off between granularity and volume is a major issue to decide. Frequent samples will detect smaller shifts in behavior, but at the expense of generating huge amounts of data to store, manage, and protecton top of the additional sampling traffic. Sampling of service behavior establishes the operational envelope: the average, maximum, and minimum values of a behavior (response time, utilization, or help desk calls, for example) over a period of time. These baselines represent the ranges of normal behavior. ProactiveNet builds intelligent thresholds from its baselines. It determines a practical threshold value after the baseline is created and the maximum and minimum ranges are determined. Thresholds are adjusted as the baseline changes, always providing an accurate warning at any time without manual staff adjustments. Adjusting thresholds on the fly is a critical feature because it accounts for the full range of motion in the environment and reduces the likelihood of both false positives (reporting problems that don't exist) and false negatives (failing to report real problems). A large variety of other management tools leverage the collected data. They determine thresholds, test for SLA compliance, isolate failures, or produce business metrics, for example. ProactiveNet monitors a variety of devices, applications, servers, and other infrastructure components. The baselines and intelligent thresholds provide the warning and identify the cause if resource usage shifts toward a potential service disruption. These techniques are very powerful for dealing with single elements. However, web-based services are composed of a highly interrelated set of elements distributed across multiple organizations. More information is needed for tracking down service disruptions in a complex infrastructure. ProactiveNet therefore provides a pre-built set of dependency relationships for most common applications so that customers are spared the effort of building them. This feature alone makes a significant contribution to reducing deployment cycle time with ProactiveNet. When searching for the root cause of a problem, ProactiveNet uses a sequential filtering approach, progressively eliminating elements as the root cause until only those likely to be a cause of the disruption remain. As shown in Figure 6-5, each filtering step removes a portion of the remaining candidates. The steps that are taken are initiated by an alarm reporting degraded performance. Figure 6-5. ProactiveNet Root-Cause Filtering
The first filter discriminates between normal and abnormal behaviors. Processing is very efficient because ProactiveNet has already established the adaptive resource baselines. Only abnormal behaviors are selected, resulting in a significant reduction in candidates, on the order of 200:1. The second filter applies time-based correlation to the remaining candidates. The premise at this stage is that the probability of simultaneous, unrelated baseline deviations is unlikely. Time correlation associates a set of abnormal baselines with a single cause, as yet undetermined. System dependencies are the focus of the third filtering stage. ProactiveNet uses the relationship information stored for common transactions to further isolate the root-cause. The dependencies point back to the root-cause because the transaction depends on these resources. For example, given a sluggish transaction, anomalies in e-mail performance metrics are set aside if the transaction doesn't depend on the e-mail service. Finally, the filtered element data is examined in detail and ranked, if possible, by the probability that it is the cause of the problem. It is then presented to the operators for evaluation. With a ranked set of potential causes computed automatically, administrators and troubleshooters can get to work applying professional judgment much more quickly than if they had to work through the root-cause triage manually. NetuitiveNetuitive specializes in predicting future behavior. The company's offerings build predictive models that are used to identify behaviors that may lie outside the range of expected activity thresholds. The models are derived from correlation inputs in combination with configurations set by subject matter experts. Most services have a large number of parameters that characterize their behavior. Any root cause or triage strategy needs to determine which variables are the most useful in understanding and predicting behavior. Typically, there is an overabundance of variables from which to choose, confounded by a lack of understanding of their relationships to each other. Netuitive proceeds through a set of steps as they build a predictive model. The tool collects operational information, refines the variables, incorporates expert knowledge, and refines the model. The process begins by baselining the range of operational behavior, collecting operational data for a 14-day period as a first step in modeling for a new application. Netuitive captures all the variables the application provides as it builds a representation of average, maximum, and minimum values for the operational envelope. Netuitive then identifies strongly correlated variablesthose whose behavior is tightly coupled to other variables that define the operational envelope. A change in one variable will be reflected in other strongly correlated variables and is therefore a good predictor of change. Conversely, tracking a variable with low correlation does not provide any indication of its impact on overall application behavior. The goal is to determine a small set of strongly correlated variables that are accurate indicators of behavioral change. This enables the model to be as simple as possiblebut not so simple that it provides inaccurate predictions. Netuitive also facilitates incorporation of input from experts that understand the modeled application. These are usually members of the original development team or those who have extensive practical experience with using the application. Such subject matter experts provide the root-cause information, using their knowledge to link specific variable changes with their likely causes. The final stage in predictive model development is verifying the capabilities and usefulness of the model. Anomalous events are introduced to validate that the model detects them and provides the correct root-cause analysis for them. The assessment also tracks the numbers of false alarms that are generated as a measure of the model's accuracy. The application model is now ready for production use; it shows how the various measurement inputs are correlated and how they can be used to predict performance problems. In production, the Netuitive Analytics Core System Engine calculates dynamic thresholds for models' variables using their workload and the time as the basis. The threshold values defining the operational envelope are updated continuously. The Netuitive system also calculates imputed values for the model's variables based on the actual variable values and history. In other words, it evaluates the expected value if the variables follow their normal relationships and the correlation between them holds. Real-time alerts are generated when actual measurements differ from the imputed values by an amount that indicates a possible problem. Predictive alerts indicate that a forecasted value will exceed the forecasted baseline range. The alerting module also has a parameter that defines the number of alerts that trigger an alarm to other management elements, such as a management platform. Netuitive's approach offers a peek into the future. A possible drawback is keeping the models current with application enhancements. Changes in the application may introduce new correlations between variables. New behavior must also be incorporated after finding the needed experts. This may represent an ongoing effort that should be balanced against the gains of predictive tools. Handling DDoS AttacksDDoS attacks are another real-time phenomenon that must be dealt with because security concerns continue to draw a high profile. Such attacks are designed to overwhelm a site with a load that causes failures and brownouts. As a result, legitimate customers are prevented from carrying out their normal activities, and business processes are interrupted or halted. DDoS attacks are characterized by large volumes of sham transactions solely intended to overtax infrastructure elements. A SYN Flood attack is a classic example. The SYN bit in an incoming packet header indicates an offer to establish a connection. Receipt of a header with the SYN bit set initiates the establishment of a connection, but the attacker never completes it. The server will eventually discard the pending connection, but a flood of such connection attempts will cause overflows inside the server system before the pending connections can be discarded. The server may therefore be unable to handle legitimate connection requests. Other attacks establish hundreds or thousands of connections simultaneously by accessing the same URL or application. These attacks are attempting to oversubscribe resources and disrupt legitimate activity. Attackers maintain their anonymity by using other systems to launch their DDoS attacks against a targeted site. They scan the Internet for computer systems that have security flaws and exploit them to insert their own software. The first thing the software does is hide traces of its insertion. It then goes dormant, awaiting a directive to begin an attack. Attackers can amass thousands of such sleeper agents, called zombies, and scale their attacks to take down even the most robust Internet sites. The attacker unleashes the attack by sending the zombies a directive specifying the target system and the attack parameters (some actually select from a repertoire of attacks). The sudden onslaught of a DDoS attack can quickly disrupt operations. There is often no warning, such as a more gradual increase in loading might provide. The performance and availability collapse can be very sudden if elements are operating with little headroom. Traditional Defense Against DDoS SituationsThe traditional defense in DDoS situations is to determine the address of the attackers and then to create filters that network devices and firewalls use to screen traffic. This process is time consuming, and service disruptions can last for extended periods of time (from hours to several days to full recovery) while the culprits are located and screened out. Unfortunately, attackers are aware of this defense, and they add another level of anonymity by using IP spoofingthe attack packets do not use the zombie's address as the source, but use a randomly created address instead. This makes tracing the packets to their source difficult because the address is counterfeit.
The traditional defense against DDoS attacks entails these steps:
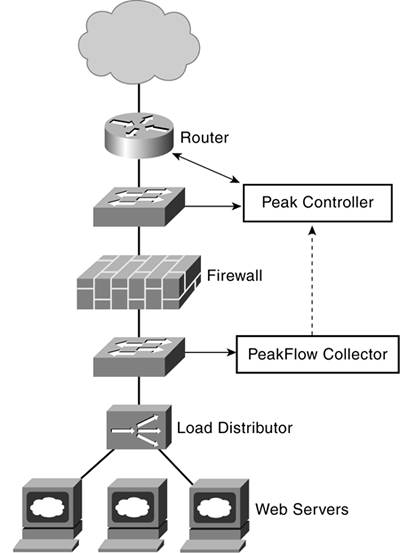
This is an incredibly tedious, labor-intensive, and frustrating process, especially when multiple organizations must coordinate and cooperate quickly for the defense to succeed. It is made more difficult because these steps must be applied for each of thousands of attackers. By constantly changing their addresses, attackers elude screening and force the management team to constantly adjust their filters. Overwhelming the management team creates a secondary denial of servicethe management team must neglect other tasks while defending against DDoS attacks. Most management teams under attack are too overwhelmed and unable to take the time and effort to trace every individual attack. They must resort instead to faster and less precise responses such as blocking an entire subnet if an attacker's origin is traced to it. Although this stops the attack, it also blocks any legitimate traffic originating from that subnet. Organizations are clearly at the mercy of these attacks. The fatalists believe the only defense is to avoid as much notice as possible, staying off the attacker's radar, in effect. However, building a strong Internet presence and avoiding notice is an impossible balancing act. Attackers will continue extending their advantage as long as they use automated attacks against manual defenses. Defense Through Redundancy and BufferingOrganizations with large online business activities use many types of redundancies to protect themselves from disruptions of all types. Using several Internet providers is a hedge against wide-scale disruptions that might impact the operations of a single provider. Multiple data centers, physical redundancy, and global load balancing offer additional buffers. Unfortunately, attackers are limited only by the number of unsecured systems they can penetrate and use as zombies. As long as that remains the case, a DDoS attack can be scaled to overwhelm any finite set of resources. Organizations and providers cannot over-provision and hope they have enough spare capacity to cushion the effects of an attack while they track its origins. Redundancy is used primarily to support high availability and high performance. Still, redundancy can help buffer some of the initial impact of an attack, buying additional time for defensive measures. For example, the global load balancing system is often the first place the loads are concentrated as new connection attempts begin to accelerate. It may be able to spread the attacking traffic to different sites, cushioning its impact and buying time with an early warning. Some load balancing vendors now include DDoS attack detection and some attack defense capabilities in their products. Automated DefensesOne of the continuing threats that DDoS attacks pose is the shock of a sudden traffic surge that disrupts services for lengthy periods. All too often, rapidly deteriorating service quality is the earliest indication that an attack is underwayin fact, such a degradation shows it is already succeeding. Earlier detection clearly helps the defensedetecting the early signs, or signatures, of an impending attack and activating the appropriate defensive measures in time. A warning from any source is helpful, but those that provide the longest lead time are the most valuable. Longer lead times are attained with some trade-off with accuracy. A sudden surge of 100,000 connection attempts within the last minute has a very high likelihood of being a DDoS attack, but your lead time is very short. Conversely, detecting a smaller perturbation that predicts an incipient attack increases your lead time and options for countering the attack. However, the longer lead time might also come with an occasional false alarm when some perturbation was not actually indicative of an attack. Two examples of defense solutions are described in the following sections to show the range of automated approaches available. Arbor Networks PeakFlowArbor Networks is representative of companies (Mazu Networks and others) that are using sophisticated detection tools to automatically drive problem attack analysis and defense. Figure 6-6. Arbor Networks' PeakFlow Architecture
The Arbor PeakFlow system is a set of distributed components for defending against DDoS attacks. Collectors gather statistics from Cisco and Juniper routers and from other network components, such as switches. They also monitor routing update messages to follow changes in the routing fabric. Periodic sampling is used to build a normal activity baseline for each collector. Collectors detect anomalous changes in the traffic patterns and characterize them for the PeakFlow controllers. (This is where each vendor has their "secret sauce": proprietary algorithms for mining the changing operational patterns and extracting better predictions of future problems.) The distributed PeakFlow collectors provide the detailed analysis that identifies particular attack signatures. Knowing the type of attack helps direct the defensive response more accurately. Remote collectors also capture new anomalies that may prove to be new attack signatures. New signatures are added to provide faster diagnosis if the same attack is attempted in the future. A PeakFlow controller integrates the reports from a set of collectors and determines if a DDoS attack is indicated in the anomalies. The controller traces the attack to its source and constructs a set of defensive filters. The controller can then automatically load and activate the defensive filters, or they can be initiated after staff inspection. The Arbor Networks approach uses a centralized correlation engine to pick out attack indicators from the collector anomaly reports. Centralized correlation aids accuracy because the distributed nature of attacks may be obscured when looking at each point of attack; the aggregate pattern is more revealing. NetScaler Request SwitchesNetScaler is an example of a DDoS defense system that is based on a load balancing product. The NetScaler RS 6000 and RS 9000 products are front-end processors for web servers. They create persistent connections with the end user and with the web servers. The connections are primarily used for load management; thousands of end-user connections are managed by NetScaler and condensed into far fewer connections to the web servers. The connection-management technology can also be used as part of a DDoS defense. The established connections to the end users are prioritized and maintained despite incoming bursts of new traffic, some of which may be part of a DDoS attack. Distinguishing the traffic streams ensures legitimate users will maintain access and will be able to carry out their activities. In contrast to the automated anomaly detectors used by Arbor Networks, the NetScaler switches do not actively trace attackers to their origin. Instead, they maintain stable services while reporting the attack to the management staff for further attention. Organizational Policy for DDoS DefenseResponding to DDoS attacks by tracking the source and denying further access is a critical part of the process, but other concerns must also be included. To handle such a threat effectively, management teams must establish a comprehensive policy for dealing with these potentially debilitating attacks, policies that deal with organizational function and communications for contingencies such as DDoS. In this fashion, if and when an attack happens, all participants have a clear picture of their respective roles and obligations. Communications plans are the foundation. Notification policies must be defined and implemented. Management planners must determine who is notified at the first indication of an attack, what notification escalation procedures are invoked if the attack is verified, and the specific staff skills that are needed. Response policies must also be in place; management teams need clearly defined policy steps. These procedures also need to be practiced so that they work as expected when a real attack occurs. Some policy questions that need discussion and agreement prior to the attack itself include the following:
Increasingly sophisticated DDoS attacks demand more sophisticated defenses. This area merits continuous attention, as attackers will not rest once their current methods have been defeated. Detectors and the policies they activate must be reviewed and refined to meet evolving threats. |
EAN: 2147483647
Pages: 128