Section 1.4. Change Management
1.4. Change ManagementChange management deals with, well, managing change. In other words, you need to plan for both scheduled and emergency changes to your network. Not doing so can cause networks and systems to be unreliable at best and can upset the very people you work for at worst. The following sections provide a high-level overview of change management techniques. The following techniques are recommended by Cisco. See the end of this section for the URL to this paper and others on the topic of network management. 1.4.1. Planning for ChangeChange planning is a process that identifies the risk level of a change and builds change planning requirements to ensure that the change is successful. The key steps for change planning are as follows:
1.4.2. Managing ChangeChange management is a process that approves and schedules the change to ensure the correct level of notification with minimal user impact. The key steps for change management are as follows:
1.4.3. High-Level Process Flow for Planned Change ManagementThe steps you'll need to follow during a network change are represented in Figure 1-2.[*] The following sections briefly discuss each box in the flow.
1.4.3.1. ScopeScope is the who, what, where, and how for the change. In other words, you need to detail every possible impact point for the change, especially its impact on people. 1.4.3.2. Risk assessmentEverything you do to or on a network, when it comes to change, has an associated risk. The person requesting the change needs to establish the risk level for the change. It is best to experiment in a lab setting if you can before you go live with a change. This can help identify problems and aid in risk evaluation. Figure 1-2. Process flow for planned change management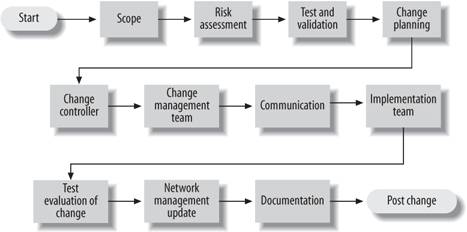 1.4.3.3. Test and validationWith any proposed change, you want to make sure you have all of your bases covered. Rigorous testing and validation can help with this. Depending upon the associated risk, various levels of validation may need to be performed. For example, if the change has the potential to impact a great many systems, you may wish to test the change in a lab setting. If the change doesn't work, you may also need to document backout procedures. 1.4.3.4. Change planningFor a change to be successful, you must plan for it. This includes requirements gathering, ordering software or hardware, creating documentation, and coordinating human resources. 1.4.3.5. Change controllerBasically, a change controller is a person who is responsible for coordinating all details of the change process. 1.4.3.6. Change management teamYou should create a change management team that includes representation from network operations, server operations, application support, and user groups within your organization. The team should review all change requests and approve or deny each request based on completeness, readiness, business impact, business need, and any other conflicts.
1.4.3.7. CommunicationMany organizations, even small ones, fail to communicate their intentions. Make sure you keep people who may be affected up-to-date on the status of the changes. 1.4.3.8. Implementation teamYou should create an implementation team consisting of individuals with the technical expertise to expedite a change. The implementation team should also be involved in the planning phase to contribute to the development of the project checkpoints, testing, backout criteria, and backout time constraints. This team should guarantee adherence to organizational standards, update DNS and network management tools, and maintain and enhance the tool set used to test and validate the change. 1.4.3.9. Test evaluation of changeOnce the change has been made, you should begin testing it. Hopefully you already have a set of tests documented that can be used to validate the change. Make sure you allow yourself enough time to perform the tests. If you must back out the change, make sure you test this scenario, too. 1.4.3.10. Network management updateBe sure to update any systems like network management tools, device configurations, network configurations, DNS entries, etc., to reflect the change. This may include removing devices from the management systems that no longer exist, changing the SNMP trap destination your routers use, and so forth. 1.4.3.11. DocumentationAlways update documentation that becomes obsolete or incorrect when a change occurs. Documentation may end up being used by a network administrator to solve a problem. If it isn't up-to-date, he cannot be effective in his duties. 1.4.4. High-Level Process Flow for Emergency Change ManagementIn the real world, change often comes at 2 a.m. when some critical system is down. But with some effort, your on-the-fly change doesn't have to cause heartburn for you and others in the company. Documentation means a lot more during emergency changes than it does in planned changes. In the heat of the moment, things can get lost or forgotten. Accurately recording the steps and procedures taken will ensure that troubles can be resolved in the future. If you have to, take short notes while the process is unfolding. Later, write it up formally; the important thing is to remember to do it. Figure 1-3 shows the process flow for emergency changes.[*]
Figure 1-3. Emergency change process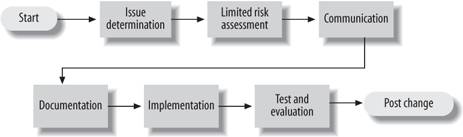 1.4.4.1. Issue determinationKnowing what needs to change is generally not difficult to determine in an emergency. The key is to take one step at a time and not rush things. Yes, time is critical, but rushing can cause mistakes to be made or even bring about a resolution that doesn't fix the real issue. In some cases, the outage can be unnecessarily prolonged. 1.4.4.2. Limited risk assessmentRisk assessment is performed by the network administrator on duty, with advice from other support personnel. Her experience will guide her in how the change is classified from a risk perspective. For example, changing the version of software on a router has much greater impact than changing a device's IP address. 1.4.4.3. Communication and documentationIf at all possible, users should be notified of the change. In an emergency situation, it isn't always possible. Also, be sure to communicate any changes with the change manager. The manager will wish to add to any metrics he keeps on changes. Ensuring that documentation is up-to-date cannot be stressed enough. Having out-of-date documentation means that the staff cannot accurately troubleshoot network and systems problems in the future. 1.4.4.4. ImplementationIf the process of assigning risk and documentation occurs prior to the implementation, the actual implementation should be straightforward. Beware of the potential for change coming from multiple support personnel without their knowing about each other's changes. This scenario can lead to increased potential downtime and misinterpretation of the problem. 1.4.4.5. Test and evaluationBe sure to test the change. Generally, the person who implemented the change also tests and evaluates it. The primary goal is to determine whether the change had the desired effect. If it did not, the emergency change process must be restarted. 1.4.5. Before and After SNMPNow that you have an idea about what SNMP and network management are, we should look at the before and after pictures for implementing these concepts and technologies. Let's say that you have a network of 100 machines running various operating systems. Several machines are fileservers, a few others are print servers, another is running software that verifies credit card transactions (presumably from a web-based ordering system), and the rest are personal workstations. In addition, various switches and routers help keep the network going. A T1 circuit connects the company to the Internet, and a private connection runs to the credit card verification system. What happens when one of the fileservers crashes? If it happens in the middle of the workweek, the people using it will notice and the appropriate administrator will be called to fix it. But what if it happens after everyone has gone home, including the administrators, or over the weekend? What if the private connection to the credit card verification system goes down at 10 p.m. on Friday and isn't restored until Monday morning? If the problem was faulty hardware and it could have been fixed by swapping out a card or replacing a router, thousands of dollars in web site sales could have been lost for no reason. Likewise, if the T1 circuit to the Internet goes down, it could adversely affect the amount of sales generated by individuals accessing your web site and placing orders. These are obviously serious problemsproblems that can conceivably affect the survival of your business. This is where SNMP comes in. Instead of waiting for someone to notice that something is wrong and locate the person responsible for fixing the problem (which may not happen until Monday morning, if the problem occurs over the weekend), SNMP allows you to monitor your network constantly, even when you're not there. For example, it will notice if the number of bad packets coming through one of your router's interfaces is gradually increasing, suggesting that the router is about to fail. You can arrange to be notified automatically when failure seems imminent so that you can fix the router before it actually breaks. You can also arrange to be notified if the credit card processor appears to get hungyou may even be able to fix it from home. And if nothing goes wrong, you can return to the office on Monday morning knowing there won't be any surprises. There might not be quite as much glory in fixing problems before they occur, but you and your management will rest more easily. We can't tell you how to translate that into a higher salarysometimes it's better to be the guy who rushes in and fixes things in the middle of a crisis, rather than the guy who makes sure the crisis never occurs. But SNMP does enable you to keep logs that prove your network is running reliably and show when you took action to avert an impending crisis. 1.4.6. Staffing ConsiderationsImplementing a network management system can mean adding more staff to handle the increased load of maintaining and operating such an environment. At the same time, adding this type of monitoring should, in most cases, reduce the workload of your system administration staff. You will need:
There is no way to predetermine how many staff members you will need to maintain a management system. The size of the staff will vary depending on the size and complexity of the network you're managing. Some of the larger Internet backbone providers have 70 or more people in their NOCs and others have only one. |

EAN: 2147483647
Pages: 165
- An Emerging Strategy for E-Business IT Governance
- Measuring and Managing E-Business Initiatives Through the Balanced Scorecard
- A View on Knowledge Management: Utilizing a Balanced Scorecard Methodology for Analyzing Knowledge Metrics
- Governance in IT Outsourcing Partnerships
- Governance Structures for IT in the Health Care Industry