Pathfinding Algorithms
| As we've mentioned before, a pathfinding algorithm is one that finds any path between two points. Usually these two points are the centers of two different tiles in a tile-based world. (In fact, I can't think of an implementation of pathfinding that is not in a tile-based world.) To help get you started learning about pathfinding algorithms, here are a few of the most popular types. (Note: These algorithms perform the pathfinding all at once in memory and then give a complete path usually in the form of an array as the final result.)
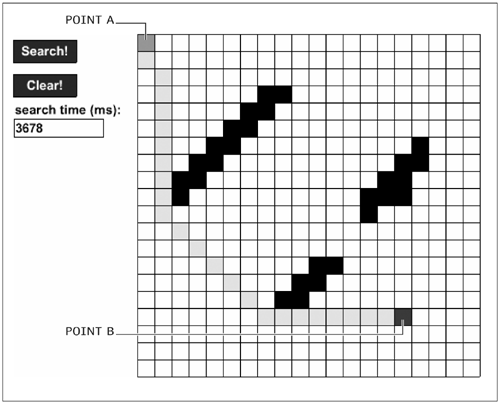
Each of these types of pathfinding algorithms has its benefits and weaknesses. Some are superfast to compute but can yield very long or odd-looking paths. Some give nice-looking paths under certain conditions, such as in an environment with no concave obstacles like closets. As always, you have to weigh the pros and cons and choose your trade-offs. The best-known pathfinding algorithm is A*. Provided that you fulfill some conditions (that we will discuss in a while), A* is guaranteed to return the shortest possible path between two points. Like the other pathfinding algorithms, however, A* also has a drawback: It is slow. The A* algorithm is one of the most (if not the most) CPU-intensive pathfinding algorithms. Still, regardless of its speed, A* is used more than any other pathfinding algorithm in games. When you play games like Diablo, and you click in an area on the screen, the character walks to that position. If there is an obstacle in the way, the character walks around the obstacle. In any game you play that has pathfinding ability like this, the game is probably using A*. In this section we're going to introduce you to that algorithm and walk you through it. In the image above you can see a basic implementation of the A* pathfinding algorithm. What you see is a 20-by-20 grid. The white cells are empty cells. The black cells contain walls. The gray cell at the top left (point A) is the starting position of a character; the dark gray cell at the bottom right (point B) is the ending position of that character. The light gray path that connects the two is the path created by the A* pathfinding algorithm. The A* pathfinding algorithm finds the way from point A to point B.
The A* AlgorithmBefore we continue on into that specific algorithm, however, you need to know a few more things about how we are going to proceed, and with what tools. I have written the A* algorithm in ActionScript and have included two example files on the CD that use that ActionScript but I will not be explaining the ActionScript to you line by line; instead, I'm going to tell you how to use what I have created. I will discuss in detail the algorithm itself using pseudo-code, and then make some general references to the ActionScript. Pseudo-code is a representation of an algorithm in a codelike form (sort of like an outline of a chapter). It mentions what you should do in code without giving you a specific syntax. This means that pseudo-code is not language-specific; Java programmers, ActionScript programmers, C++ programmers any kind of programmer can read and understand it. One of the beauties of pseudo-code is that it tends to be pretty short. For instance, the pseudo-code used here is just over 30 lines, but the algorithm written in ActionScript is nearly 170. In pseudo-code you might have a line that informs the reader to delete an element from an array, but in real code you would have to loop through the array to find the element and then delete it, which would take several lines of code.
Basic A* terminology and functionalityAs with many math-based concepts, the A* pathfinding algorithm uses a handful of terms you have to be familiar with in order to proceed. These terms describe the states, actions, and results that go along with this process:
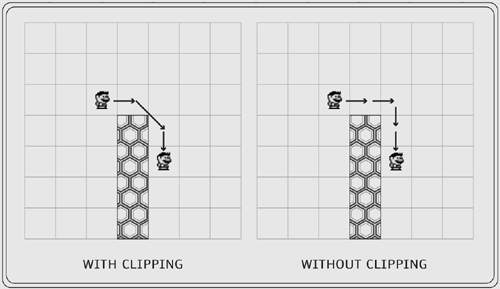
With these terms in place, let's see how they apply to the algorithm, and more generally, how A* works. As you now know, A* finds the shortest path between two points. But what measurement are we using? Time? Distance? Number of steps? While A* can be used to search according to pretty much any measurement, we choose to use distance. Other measurements might be time (to find the path that takes the shortest time to walk) or the number of tanks of gas used (to find the path that uses the smallest amount of gas in a car). To the cost of moving between one tile and its vertical or horizontal neighbor we will assign a value of 1 (1 foot, 1 mile, 1 tile it doesn't matter). The cost of moving between one tile and a neighboring diagonal tile is 1.41. The number 1.41 is the distance between the centers of two neighboring diagonal tiles. The heuristic is the best guess of how far the center of the current tile (that you are inspecting during the search) is from the destination tile. You can make this guess fairly easily using simple logic. When visited, each node is assigned a score of f: f = g + h The value h is the heuristic the best guess of the distance between that tile and the goal. The value g is the sum of the scores of every node visited along the path to the current node. This may be best understood with an analogy. Let's say you are planning a trip from New York to Paris. You are on a tight budget, so you want to find the path that will cost the least. You can think of New York, London, Lisbon, Brussels, Madrid, and Paris as nodes. In the course of your research, you calculate the cost from New York to London and store that. But you also calculate the costs of traveling from Lisbon to New York, London to Paris, and so on. In the end, if you apply other rules (not yet discussed) with A*, you find the best path (for cost). Let's assume that this path turns out to be New York Madrid London Paris. In New York (as in all nodes), f = g + h. Remember that g is the sum of all the fs of the previous nodes. Since New York is the starting node, there are no parents, so g = 0 in New York. For Madrid, f = g + h also (as in all nodes). In this case, g is not 0 because Madrid was visited from another node. The g value is made up of the f from New York. So g is the running total of cost up to the current node. If you were actually on this trip, then g would be the amount of money spent up to your current position. At this point it is appropriate to mention one of the most amazing features of A* the way it handles terrain. Above, I said that the cost of going from one tile to the next is either 1 or 1.41. That is true if all tiles are of equal size, but that statement does not always have to be true. Let's say some of the tiles are made up of water. Chances are, you probably don't want to send your character through the water unless it is absolutely necessary. So you then assign a cost of, let's say, 10 to any node transition (moving from one node to another) that involves water. This will not guarantee that the path does not go through the water, but it will give extreme preference to paths that don't. If the water is a stream going completely through the map and there is no bridge, then A* will certainly end up giving you a path through the water. However, if there is a bridge, and it is close enough, then A* will give you a path that includes the bridge. Alternatively, if your character is half man and half fish, then he may prefer water. In this case, you may give land a lower cost than water. With all this in mind, I should probably modify my initial statement that A* always finds the shortest path. Now that you know more, I can further specify that A* will always find the path with the lowest score. In many cases (such as those of maps in which there is no terrain change, like the implementations used later in this section), the path with the lowest score also happens to be the shortest path. A* spelled out, almost in EnglishNow let's look at the algorithm itself in pseudo-code. 1 AStar.Search 2 create open array 3 create closed array 4 s.g = 0 5 s.h = findHeuristic( s.x, s.y ) 6 s.f = s.g + s.h 7 s.parent = null 8 push s into open array 9 set keepSearching to true 10 while keepSearching 11 pop node n from open 12 if n is the goal node 13 build path from start to finish 14 set keepSearching to false 15 for each neighbor m of n 16 newg = n.g + cost( n, newx, newy ) 17 if m has not been visited 18 m.g = n.f 19 m.h = findHeuristic( newx, newy ) 20 m.f = m.g + m.h 21 m.parent = n 22 add it to the open array 23 sort the open array 24 else 25 if newg < m.g 26 m.parent = n 27 m.g = newg 28 m.f = m.g + m.h 29 sort the open array 30 if m is in closed 31 remove it from closed 32 push n into the closed array 33 if search time > max time 34 set keepSearching to false 35 return path This algorithm makes use of two lists (which are arrays in Flash), open and closed. The open array contains the nodes that have at one time been visited. The closed array contains all nodes that have been expanded (that is, all of its neighbors have been visited). We use the open array as a priority queue. We use the open array not only to store nodes, but also to store nodes in a certain order. We keep the array sorted from lowest score (f) to highest score. Every time we add a node to the open array or change the value of g in a node in the open array, we must re-sort the array so that the nodes are in order from lowest to highest score. In lines 2 and 3 above we create the empty open and closed arrays. In pathfinding we need a starting place and a destination, so that comes next. S is an object that represents the starting node. We set s.g to 0, since the starting node has no parents, so the cost (g) to get to it is 0 (line 4). Next, we find the heuristic h for the start node. (Remember that the heuristic is the estimated cost from the current node to the goal.) We then store the value of f, which is the sum of s.g and s.h, on the starting node (line 6). Since s has no parents, we set s.parent to null. Next, we push the s node into the open array (line 8). The s node is now the first and only node in the open array. In line 9 we set the variable keepSearching to true. While it remains true, we will keep performing the A* search. When we have determined that we have found a path, that no path exists, or that we have been searching for too long, we will set keepSearching to false. In line 11 we take a node from the priority queue. We then check to see if this node is the goal. If it is, we have reached the goal; then we stop searching and build the path (lines 12 14). If it is not the goal, we expand the node. Expanding the node means that we visit each of the node's neighbors. In line 16 we find the g of the neighbor node, m, that we are currently looking at. We then check to see if this node has ever been visited. If it has not yet been visited, then we enter the portion of the algorithm in lines 18 23. We set the value of g on m; it is the f from its parent, n. Next we calculate and store the heuristic and f on m. Finally, we set the parent property to be that of the previous node, n. If this node has been visited before and now has a lower g, then we enter the portion of the algorithm in lines 25 31.
I have to be honest with you I'm not quite sure what lines 30 and 31 are for! It was in the pseudo-code from which I learned the A* algorithm, and I have included it in my ActionScript implementation. But it is a part of the algorithm that has never been visited during any of the example searches I have constructed (I put a trace action in that part of the code so that I would be informed if it was ever entered). Throughout my dozens and dozens of tests I have never experienced a use for this. The algorithm, written in ActionScript, to the best of my knowledge works exactly as it should, and always returns the path with the lowest score. However, I have kept that part of the algorithm around even though it seems to be unnecessary, just in case I someday realize when it would be needed. If you are an A* whiz, then let me know your thoughts! After all of the neighbors of n are visited, we move on to line 32. In this line we push n onto the closed array because it has been completely expanded. We then check the time to make sure that we haven't been searching for too long. If we have been searching too long, then we set keepSearching to false. Otherwise, we move on to the next node in the queue (line 11). If keepSearching is false, we stop searching and build the path. You have now been formally introduced to A*! Don't feel bad if you are having trouble understanding the algorithm; it is not the easiest thing in the world to grasp. It took me several articles on the Internet before I felt like I fully understood basic A*. Implementing A*You have seen the A* algorithm and should have at least a basic understanding of how it works. I have written the A* algorithm in ActionScript on an object called astar. Let's take a look at how it's implemented. Open astar.fla in the Chapter09 directory on the CD. Look at the actions on the A* layer. The astar object contains another object, called nodes. The nodes object contains information about certain tiles. For instance, the nodes object might contain an object called cell8_2 that contains information saying that the tile contains a wall. If a tile contains a wall, then no path can go through it.
To use the astar object to perform a path search, you must do the following:
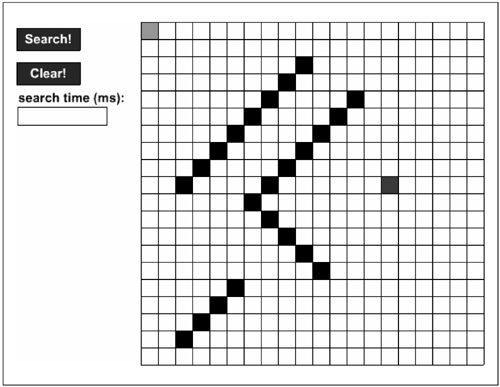
If no path is found, then the path is returned as null. If the search takes too long, then it is aborted and the path is returned as null. There is a variable called maxSearchTime on the astar object. By default, this variable is set to 5000 (5 seconds), but of course you can change it to suit yourself. Using Test Movie, take a look at the SWF of astar.fla. You will see a 20-by-20 grid of tiles. Click any tile to add a starting point, and then click any other tile to add a goal. Then click every tile you want to make into a wall. Finally, click the Search button. You will see a path appear on the screen. To search for another path, click the Clear button and start over.
Variations on A*You've now seen and experienced my version of the A* algorithm. For games that are similar to the isometric example shown in the previous section, my implementation is probably good enough for what you're doing. However, if you are going to be using maps that are larger than about 20 by 20 tiles (which is likely), you will quickly realize that my A* version is just not fast enough. Or you may want to take advantage of the multiterrain features of A* that I haven't included in my version. For a faster A* or one that handles multiple terrains, you'll have to modify my A* version, build your own, or use one that someone else has created. In the next two sections I briefly discuss both speed and multiterrain support. Not fast enough for you?As you may have noticed in astar.fla, the speed at which the path is found is very slow. In iso_ai_astar.fla the speed is barely acceptable. In that file the search tends to take (at least on my computer) from 80 milliseconds (ms) to 400 ms. In astar.fla a simple search with no walls going from the top-left to the bottom-right takes 3 to 4 seconds! When building this A* algorithm in ActionScript, I focused on getting it to work and making it easy to use not on speed. However, in the coming months I will probably optimize this ActionScript for speed (so feel free to check up on www.electrotank.com to see how I'm doing). If you are in a rush to get your hands on a blazingly fast implementation of A* in ActionScript, take a look in the astar_optimized folder. There you'll find some very fast A* files created by Casper Schuirink. What takes my A* 3 or 4 seconds, Casper's can do in 150 ms to 200 ms, and most typical searches are under 100 ms. As with all highly optimized files, they also have their disadvantages. One major con, in this case, is that the files are not necessarily easy to port over to your own applications. Ease of use is sacrificed for speed, so be cautious. Make mine an all-terrain vehicleIn the previous section I mentioned that you can modify my A* implementation to handle other terrains. You can do this in the cost() function. The cost() function is passed information on the parent node and the current node. With this information, A* calculates a cost. If you want to add different types of terrain, such as sand, water, or oil, then you would set a property of your choice (for example, terrain = "water") on the node that represents that tile. Then when the cost is calculated, you check to see what type of terrain the tile has, and then calculate a cost from that. Good luck! |
EAN: N/A
Pages: 163
- Chapter II Information Search on the Internet: A Causal Model
- Chapter IV How Consumers Think About Interactive Aspects of Web Advertising
- Chapter VI Web Site Quality and Usability in E-Commerce
- Chapter VII Objective and Perceived Complexity and Their Impacts on Internet Communication
- Chapter XIII Shopping Agent Web Sites: A Comparative Shopping Environment