Application of the Statistical Methods
| This section includes an example of how the statistical principles can be used in network management. It begins with some preliminary information about response times and simulation models that you need to understand for the example. If you already are familiar with these topics, you may wish to skip these sections. Response time was chosen as an example because it is an issue that interests most users. The section concludes with a discussion of the moving exponential average for calculation of Cisco routers' CPU, another application of statistical measures. Response TimesIntranets have several delay components and are generally more complex than campus networks. An intranet will usually have multiple Wide Area Network (WAN) links as well as many distributed Local Area Networks (LANs). A WAN is made up of full-duplex links between two end-points, usually between routers. Because full-duplex means that there are two independent simplex links, it is possible to have a link congested in only one direction while lightly utilized in the other. Network delay components include propagation delay, transmission delay, queuing delay, and router latency. Propagation delay is the time it takes for an electrical or optical signal to travel from one point to another. Delay is defined as a function of the speed of light through copper or fiber. Essentially, data signals will travel through telecommunications networks at approximately 2/3 the speed of light in a vacuum, or 192,000 kilometers per second. Obviously, this is not instantaneous. In fact, as networks grow nationally and internationally, propagation delay becomes the largest component of total delay and cannot be reduced. Propagation delay is the main reason that WANs can never have the performance of LANs. The larger the distance between sites or nodes, the slower a WAN is. Transmission delay is the time it takes to send a given amount of data at a given transmission speed. The mathematics for this are straightforward. For example, a line with a speed of 100 kbps will take ten seconds to transmit 1000 kilobits of data (one million bits of data) and a line at 500 kbps will take only two seconds. You can create a table for the transmission rates within your network. As you will see, transmission delay becomes particularly significant when large amounts of data are sent. NOTE Increasing the bandwidth of a WAN link does reduce transmission delay, but not propagation delay. If you use the analogy of a pipe that has both width and length, increasing the width of the pipe is similar to a bandwidth increase, but it doesn't reduce the length. Therefore, if an application is bandwidth-constrained, increasing the bandwidth will improve performance. However, our experience shows that most interactive client/server applications send relatively small amounts of data and therefore are more affected by the propagation delay. Queuing delay in a network occurs when many devices (including clients and servers) are trying to send data over the intranet at the same time. In the case of media access delay, each network device holds onto its own data packets until it gets an opportunity to transmit. In the case of queuing delay, all the data packets are sent to a device (usually a router), which has the access to the WAN. Transmission bandwidth is one of the main factors in determining the time that it takes for a router to transmit all the queued packets. For instance, if a router had a backlog of 10 KB, it would take more than a second to drain the queue over a 56-kbps link. On the other hand it would take less than 1/10 of a second over a T-1 line that transmits 1544 kbps. Router latency is a measurement of the time it takes the router to move a data packet from one interface to another. This is normally a small constant. Router latency can be reduced on Cisco routers through the use of different switching paths. Although the delay is small in itself, end-to-end router latency can become a significant factor if there are many hops. Minimizing router latency can be a significant design challenge on large networks. Router latency is usually more of an issue on a campus network than on a corporate intranet. The time for a transaction is spent in three ways: by packets traversing the network, by the server retrieving data, and by the client accepting data and asking for more data. The network component is referred to as network delay, discussed previously. The server and client delays are sometimes referred to as think times. The delays can be measured for the whole transaction or per-packet. The important point is to determine the fraction of the transaction delay attributed to network, server, and client. Our primary assumption is that the client is requesting data from the server. Therefore at least two points of measurement are needed: the client local network and the server local network. On the client side, you will measure client delay. At the packet level, this is the delay between the time the client receives a frame of data until it requests the next frame. Also on the client network, you measure the combined (network + server) delay. The second measurement is on the server network and measures the server delay. Given all the delay components, the response time for an application is given by Equation 7-20: Equation 7-20
In order to perform this calculation, you would need to collect packet-arrival times for each packet in a transaction. The transaction of interest should be easily determined through your knowledge of the critical applications for your organization or through discussions with your users. This type of analysis cannot be made for every link or, in most organizations, for every application. It is essential to identify the critical applications based on your network's operational objectives, as discussed in Chapter 2. The determination of the number of turnaround times often can be accomplished through the software within the analyzer being used. It involves comparing packets, comparing window sizes, and calculating the differences (delta) for the transaction. The following are typical client/server applications:
The more interaction between the client and server, the more packets go back and forth, and the more sensitive the application is to network delay. This sensitivity is in part because there is a turnaround time associated with each exchange. For example, the client sends and waits for the server to respond before it sends again. Thus, for any increase in network delay, the turnaround time increases by a factor of two; first for the network delay going from the client to server, and then for the return. In a campus LAN, this turnaround time can be a few milliseconds. However, on a corporate WAN that spans a country or the globe, the turnaround time can be factors of ten or hundreds of milliseconds. Obviously, the effect of this increased turnaround time for an application can be dramatic. This delay is one of the primary reasons that many application deployment projects fail. For instance, a 50ms network delay (100ms turnaround delay, which is a fairly typical delay between Raleigh, NC and San Jose, CA) will add two seconds to an application response time. Some of the questions that need to be asked in analyzing response-time performance are the following:
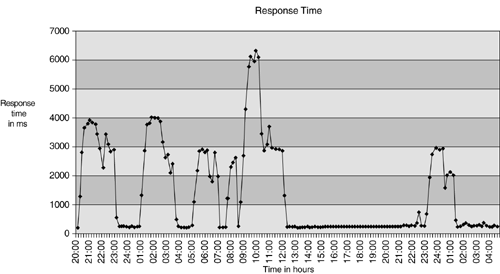
Another way to look at it is that when you are evaluating an application for use across a WAN, the more data it sends is bad; less data is good. This is particularly true with larger and slower WANs. They will be much less tolerant of applications sending a lot of data and requiring multiple transactions. Therefore, in looking at application response time, it is necessary to examine the application protocol behavior, network performance, and the client/server performance and scalability. Using Network Simulations to Analyze Response TimeThe entire process just described is complicated and takes a great amount of time. Most network managers find themselves facing very short deadlines and the demand to roll out new client-server applications, or just to improve current network performance. Simulation of the new application or of the current environment can help ensure that network changes meet user needs. As discussed in Chapters 2 and 3, one of the first and most critical steps is to baseline your network. You have a grasp of the critical applications from the operational concept. Now, it is important to understand how those applications perform within the network. One way to gain this understanding is to choose a small group of users to be monitored. They should not necessarily be from the engineering group in the NOC, but they do need to be fairly savvy users. Gather data from this group, taking into account the statistics of the source and including such parameters as peak and average bytes per second, peak and average frames per second, and the time intervals between peaks. In this case, the sampling of the data needs to be relatively high and a time resolution for these measurements should be one second. At this point, you have the data needed to create and run a simulation model. The model should incorporate the network topology and the background traffic that you have collected from your sample users. With your knowledge of your end users' needs, your network's operational objectives, and the baseline data, you have the information needed to evaluate how the simulation runs. This evaluation is called a test of simulation validity and is essential to successfully running a simulation of your network. The aim of simulations is to exactly duplicate the packet conditions on the network. One simulation method used is a probability distribution. In order to use a simulation that uses statistical processes, you need to understand what statistical parameters are needed. For instance, each of the distributions mentioned previously poisson, exponential, uniform, lognormal, and fixed have specific statistical parameters and equations. So, given the data that you have collected, you must now "fit" it into a distribution. An example of this was shown in Figure 7-1 and 7-2. It is imperative that you understand the statistical calculations that are valid for the distribution chosen. Again, in the earlier example, Table 7-1 and Equation 7-11 show the use of the statistics for a lognormal distribution. Although simulation may sound too difficult to possibly apply, it is not. By following the development of the statistics discussed in this chapter and using off-the-shelf, curve-fitting software for a PC, most of the work that initially deters people is done. Further, after you have created a simulation model of your current network (and validated that the simulation runs are within your expected parameters), you can use the model for many different tasks. For instance, simulation models can be used to evaluate WAN link capacity, LAN technologies, and server performance. The simulation run takes from minutes to hours, depending on the complexity of the model and the speed of the computer systems running the simulation. However, in a matter of only a few days, it is possible to generate a series of simulations that can help to definitively evaluate a network or application issue (new solution deployment or problem resolution). Quantitative results are generated for network utilization, router buffer utilization, dropped packets, serial line utilization, statistical distribution of application response times, effects of prioritization (or precedence) on response times, and effects of window size on throughput, as well as many other variables that you can select. The quantitative results of a simulation can be compared to the baseline data and statistics that you have collected. This comparison can be initially used to validate the simulation model, but it also provides the data needed to actively provide the capacity planning that will keep your network performance at its peak. Applying Statistical Analysis to Response Time in an Example NetworkMost corporate intranets are provisioned with sufficient bandwidth. However, without adequate data, you may not be able to rule out network congestion as a contributor to poor application performance. One of the clues for congestion or errors is if the poor performance is intermittent or dependent on time of day, like the network in Figure 7-6. The graph shows that performance is adequate late in the evening, but very slow in the morning and during peak business hours. Figure 7-6. Response Time in a Case Study Network
Figure 7-6 is based on an actual troubleshooting problem that we dealt with. On the graph, the round-trip ping times are displayed in milliseconds on the vertical axis. The average round-trip ping time is 1460ms, with a maximum round-trip time of 6420ms and a minimum of 232ms. Looking at the performance of this link, we found that the highest response times were from 8 p.m. to 9 a.m. Eliminating those hours, the average was reduced to about 500ms, with a peak of 2837ms. Investigation revealed that the cause of the abnormally high ping times was due to a number of application backups that started at 8 p.m. We could talk with the local site system administrator and work out a better backup strategy. After these backups were dealt with locally, the response time to the site fell to relatively reasonable levels. This example shows the need to view the data by at least average, minimum, and maximum data. When we looked at just the average (1460ms) it provided a very skewed view of the data. As we began viewing the average, maximum, and minimum values for several weeks worth of data, we obtained the data in Table 7-7.
The value of the variance and the fact that the standard deviation is larger than the mean were indications that the data needed to be examined in detail. Moving Exponential Average for Cisco Routers CPU CalculationAnother application of statistical methods is being able to understand the differences between the 5sec/1min/5min averages used on Cisco devices. This section discusses the use of the moving exponential average, as used by Cisco. A moving average is basically a smoothing mechanism. Trying to make sense of data is often difficult if the data contains wild spikes in one direction or the other. It is often useful to apply a tool such as a moving average to smooth the data so it is easier to spot trends. There are five basic types of moving averages:
The basic difference between these types is the weight assigned to the most recent data. Cisco IOS uses the exponential moving average to give a five-minute average to following statistics (among others):
The five-minute average is calculated by taking difference every 5 seconds. Here is the algorithm for the five-minute moving average: Equation 7-21
The values in Equation 7-21 are as follows:
The equation takes the average from the last sample less the quantity gathered in the current sample, and weights that down by the decay factor. The result is a variable that changes more slowly than the actual data. Therefore, it is smoothed out and not subject to the wild spikes that are inherent in LAN traffic and CPU load. If the value of the quantity being measured (that is, CPU utilization) is increasing, the average value in the previous calculation will be a negative number and will cause the "newaverage" value to rise less quickly on traffic spikes. And if the value of the quantity being measured is decreasing, the average value in the calculation will be a positive number and will make sure that the "newaverage" value falls less rapidly if there is a sudden stoppage of traffic. For example, if utilization were at 100 percent for some time and then instantaneously went to 0 percent, the exponential moving average would show a different picture. Over five-second intervals, the exponentially weighted utilization would go from 1.0 .983 .9832 .9833 - …. .983n Or 1.0 .983 .95 0.9 0.86 and so on. In this example, utilization drops from 100 percent to 1 percent in 90 intervals, or 450 seconds or 7.5 minutes. The exponential moving average is a good example of how to utilize statistical methods to massage the data to make it easier to interpret. |
EAN: 2147483647
Pages: 200