Training Procedure
| Training procedure uses weight optimization to produce the desired neural network. Effectively, the aim of the training procedure is to satisfy an objective function. The objective function determines the quality of a network, based on a high-level metric: Measure the performance for numerous examples, or just compare the total weight adjustments to a threshold. The objective function mainly determines when the training process is complete. Data SetsThe training of a perceptron requires example data, namely an existing collection of input data with the desired output. Each of these input/output pairs is known as a sample, a single training case. Together, these samples form the data set. Typically, not all the data set is used for training; it is split into two or three different subsets. Only one of these is used for training. The other two can be potentially used for validation (checking the results of the training to improve it), and testing (the final performance analysis of the network). Because of the simplicity of single-layer perceptrons, this is not always necessary, but this method comes in handy for more complex problems.
Training AlgorithmsTraining a perceptron usually adjusts the weights together using the optimization techniques presented. The key difference between training algorithms is how to process the samples, and there are two different approaches:
Regardless of the approach used, the aim of the training process is to adjust the weights into a near optimal configuration, which will allow the network to perform well when evaluated. Perceptron TrainingThe perceptron training algorithm is an incremental approach, but makes use of gradient information for better convergence (see Listing 17.2). This is done using the steepest descent technique, which computes the necessary adjustment Dwi for each weight wi: This equation expresses the necessary change to a weight in terms of the learning rate h, the output difference between the actual output y and the desired target t, and the current value of the input xi. The learning rate h is a small constant, usually chosen by the AI engineer, as discussed for the gradient methods. Formally, this is gradient descent on the error surface. Listing 17.2 The Perceptron Training Algorithminitialize weights randomly while the objective function is unsatisfied for each sample simulate the perceptron if result is invalid for all inputs i delta = desired output weights[i] += learning_rate * delta * inputs[i] end for end if end for end while Testing of the result's validity is usually based on Boolean logic. The inputs and outputs are also usually set to 0 or 1. The interesting point to notice is that only the misclassified patterns are used to update the weights of the network. Delta RuleThe delta rule is the equation expressing the gradient of the error in each weight, but it has also given its name to a training algorithm (see Listing 17.3). (It is also the basis of preceding solution.) A batch approach processes all the training samples before updating the weights. Listing 17.3 The Delta Rule Applied as a Batch Learning Algorithmwhile termination condition is not verified reset steps array to 0 for each training sample compute the output of the perceptron for each weight i delta = desired output steps[i] += delta * inputs[i] end for end for for each weight i weights[i] += learning_rate * steps[i] end for end while Mathematically, this corresponds to gradient descent on the quadratic error surface. In practice, it means the error is minimized globally for the entire data set, and provably so! The best result is always reached, so no validation is needed. SynopsisPerceptrons are an incredibly simple model providing a solution to linear problems. As such, there are very straightforward and efficient ways to teach it. The main decision is between the perceptron training algorithm and a batched delta rule. Both methods are proven to find solutions if they exist, given a small enough learning rate h. The perceptron training will just make sure that all the outputs are correct in binary terms. On the other hand, the delta rule will minimize the error over all the training samples in continuous space. This guarantees that there is one single global minimum, and that the learning will converge (given a suitable h). This has many advantages, including the ability to deal with noise and provide a good approximation for nonlinear functions. As such, the delta rule used in batch mode should be chosen whenever possible. The main requirement for this is to have all the data sets available for training (for instance, a log of wins and losses from the game). If this is not the case, and the perceptron needs to be learned using a stream of incoming data samples, the only option is an incremental one (for instance, learning tactics from experience during the game). Once again, just a simple application of the delta rules suffices; discarding samples classified correctly as in perceptron training can be useful in this case to prevent favoring recently learned samples. |
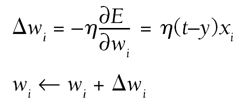
EAN: 2147483647
Pages: 399