The Purpose of Adapters
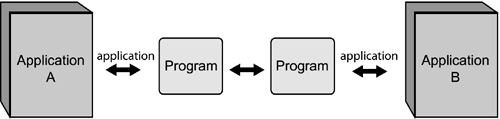
| In the past, when we sought to connect Application A to Application B, or Applications A and B to an integration server, we had to interact with that application using some sort of interface that the application (hopefully) provided. Interfaces into applications and databases vary greatly, including everything from simple well-defined APIs to complex and cryptic exit calls, or perhaps something one level above screen scraping. After hand-coding the interfaces to the middleware layer a few hundred times, in essence creating mini-applications between the source or target applications and the middleware layer, middleware vendors began to pitch the notion of adapters (see Figure 10.1). Figure 10.1. Before adapters, developers had to code the connections between the application interfaces and the middleware.
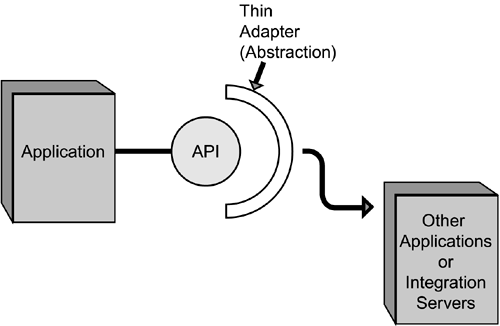
Adapters are layers between the integration server and the source or target application. For example, an adapter could be a set of "libraries" that map the differences between two distinct interfaces the integration server interface and the native interface of the source or target application and hide the complexities of those interfaces from the end user or even from the application integration developer using the integration server. An integration server vendor may have adapters for several different source and target applications (such as SAP R/3, Baan, and PeopleSoft), or for certain types of databases (such as Oracle, Sybase, or DB2), or even for specific brands and types of middleware. Over time, adapters have become more sophisticated. They began as a set of libraries that developers had to manipulate and evolved into binary interfaces that require little if any programming. Adapters are also getting smarter, with intelligence placed within the adapter, and with adapters running at the source and target systems in order to better capture events. Two types of adapters exist in the context of integration servers: thin adapters and thick adapters. These adapters may have two types of behavior: dynamic and static. Thin AdaptersToday's most popular integration servers offer thin adapters. In most cases, they are simply API wrappers, or binders, which map the interface of the source or target system to a common interface supported by the integration server (see Figure 10.2). In other words, they simply perform an API-binding trick, binding one API to another. Figure 10.2. Thin adapters don't provide sophisticated layers of software between the source or target systems and the integration server, and are really just simple abstractions on top of existing APIs.
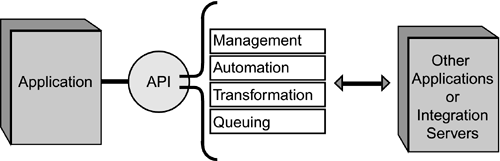
Thin adapters have the advantage of being simple to implement. With no additional, "thick" layer of software between source and target applications, there is greater granular control. Thin adapters have a number of disadvantages, however. Because using them accomplishes nothing more than trading one interface for another, thin adapters impact performance without increasing functionality. And a fair amount of programming is still required. To complicate matters, the common APIs that are being mapped are almost always proprietary. Thick AdaptersUnlike thin adapters, thick adapters provide a significant amount of software and functionality between the integration server infrastructure and the source or target applications. The thick adapter's layer of abstraction makes managing movement or invoking processes painless (see Figure 10.3). Because the abstraction layer and the manager negotiate the differences between all the applications requiring integration, almost no programming is needed. Figure 10.3. Thick adapters place a sophisticated abstraction layer on top of the application interfaces.
Thick interfaces accomplish this via the layer of sophisticated software that hides the complexities of the source and target application interfaces from the integration server user.The user sees only a businesslike representation of the process and the metadata information as managed by the abstraction layer and the adapter. In many cases, the user connects many systems through this abstraction layer and the graphical user interface, without ever having to resort to hand-coding. Repositories are major players in the thick-adapter scenario. As we noted, the repository understands much of the information about the source and target applications and can use that information as a mechanism to interact with the source and target applications on behalf of the integration server. In addition, several abstraction layers may be created around the types of applications to be integrated. For example, there may be an abstraction for common middleware services (such as distributed objects, message-oriented middleware, and transactional middleware). There may also be an abstraction layer for packaged applications, and another layer to address the integration of relational and nonrelational databases. This structure hides from the end user the complexities of the interfaces that each entity (middleware, packaged applications, and databases) employs. Another feature of a thick adapter is the ability to think and process information on its own, independent of the integration server. Processing performed by thick adapters may include
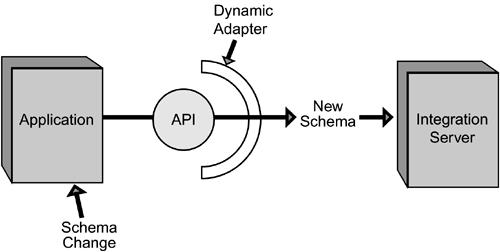
With the many advantages and conveniences of thick adapters, it should come as no surprise that integration server vendors are moving toward them. Their progress is slowed by the fact that thick adapters require a tremendous amount of time to develop, as much as six times that of a thin adapter. Right now, this time investment deters some vendors. However, as application integration becomes more sophisticated, enterprises will continue to look for more sophisticated solutions that require no programming and provide an easy, businesslike method to view the integration of the enterprise. Static and Dynamic AdaptersAs noted earlier, in addition to being thick or thin, adapters are also defined by being either static or dynamic. Static adapters, the most common adapters in play at this time, must be manually coded with the contents of the source and target systems. They have no mechanism for understanding anything about the schema of connected databases. As a result, they must be configured by hand (i.e., coded) to receive information from the source schema. If the connected database schema changes, static adapters have no mechanism to update their configuration with the new schema. In contrast to static adapters, dynamic adapters "learn" about the source or target systems connected to them through a discovery process that takes place when they are first connected to the application or data source (see Figure 10.4). This discovery process typically means reading the database schema information from the repository (or perhaps the source code) to determine the structure, content, and application semantics of the connected system. More important, dynamic adapters not only learn about the connected system, they also are able to relearn information if something changes within the connected system over time. A dynamic adapter automatically understands when a customer-number attribute name changes. Figure 10.4. When using dynamic adapters, information such as schema becomes visible to the integration server.
|
EAN: 2147483647
Pages: 220