5.3 Client/Server Architecture: The Upstart Crow The client/server architecture is perhaps the upstart crow of computer architectures. The term comes from a quote of Robert Greene about Shakespeare: "For there is an upstart crow, beautified with our feathers, that with his tiger's heart wrapped in a players hide, supposes he is as well able to bumbast out a blank verse as the best of you: and being an absolute Iohannes fac totum , is in his own conceit the only Shake-scene in a country." The irony is that the upstart crow, Shakespeare, is a long- remembered staple of English literature, while the others are long forgotten. [2] After all, who in Hollywood is planning to make the film Greene In Love ? [2] I suppose there are people who are aware of Christopher Marlowe, that other guy who got stabbed in the eye in a bar fight, but they would be hard pressed to connect his name with the "Jew of Malta." Actually, one of the few things Hollywood got right in the film Shakespeare in Love was Marlowe's death; apparently, the thespians of Shakespeare's time were similar to the rappers of our own. In our industry, the upstart crow is the client/server architecture. There is, however, a general misunderstanding of the term client/server. In the minds of most people, client/server means a somewhat powerful system on an individual's desktop, connected over a LAN to a much more powerful backroom system that runs some database or other application. The desktop system runs an application and does most of the computing. The client makes requests of the backroom system, the server, for data upon which it will perform some operation. While this may be a particular implementation of client/server, it is just that: a specific implementation. It is not a description of the client/server architecture. This misconception has tremendous implications not only for the Internet-enabled infrastructure, but for IEBI as well. Figure 5.1 presents the client/server architecture. A client/server architecture is composed of client and server processes. Both the client and the server are processes; they are not necessarily discrete systems. A client/server application really is a multiprocess application, as shown in the figure. It is composed of two general types of processes. The first is the client process. The client process is proactive ; it generates requests that are then passed to the server. The server is reactive . Its only reason for existence is to process the requests sent to it by clients . Given this scheme, the server process is a constant. It runs, theoretically, forever. This background process is the heart of the system; if the server process goes down, the entire system is down. Who in the business world today at one point or another has not suffered from a crashed server? The client process is different. The client process has a limited life span. It executes only as long as the user has need of it. If a client process goes down, it does not affect the entire system, simply the individual user . Figure 5.1. The client/server architecture. 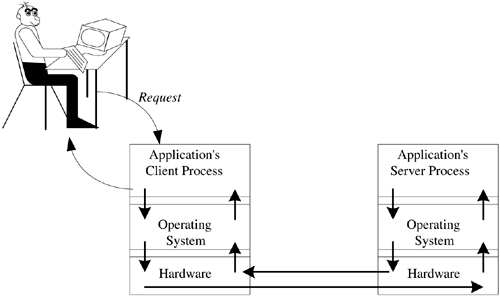 Note that this architectural layout is a conceptual design. As such, it does not define specific implementation details, such as hardware or software requirements. Those details are best left to the detailed design phase. There is nothing inherent to the client/server architecture requiring these processes to run on separate systems. We show this in more detail in Figure 5.2. Let's take Oracle's SQL Plus as an example. This is a tool on the user's system through which the user writes SQL commands to access data in the database. The tool can access any database on the network, whether it is on the same system as SQL Plus or on some backend server. If I were to run SQL Plus on the user's system and the database on another, there would be little disagreement that I have a client/server application. Basically, this is the layout shown in Figure 5.1. Suppose we run the client process on the same system as the server process. Is it still a client/server application? Has anything in the application, with the possible exception of a few initialization parameters, changed at all? Of course not; it is the exact same application! Nothing has changed. We are simply running the different parts of the client/server application on the same box, which is an implementation detail and not something inherent to the design of the system. Figure 5.2. Single-system client/server implementations . 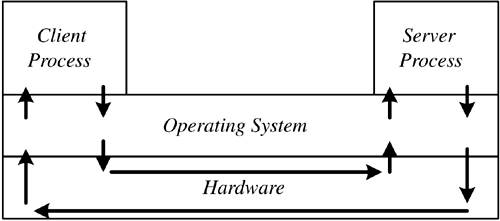 Let's take this analysis one step further. The architecture does not mandate any specifics on which requests are generated by the client or who initiates the request. Referring to Figure 5.3, we see that this has some interesting implications for the application designer. There are times when a client is actually a server, and there are other times when the server is actually a client. When a user logs on to an application, the first thing that the application does is validate the user. The application server submits a request to the access server for validation of the user. At that point, the application server is a client of the access server. Once the user has been validated , he or she will begin to process transactions or perform data analysis. The application server then begins to make requests of the database server. Again, we see that the application server is a client to the database server. Some database servers' only clients are intermediary servers, such as an application or Web server. Figure 5.3. Who is the client, and who is the server? 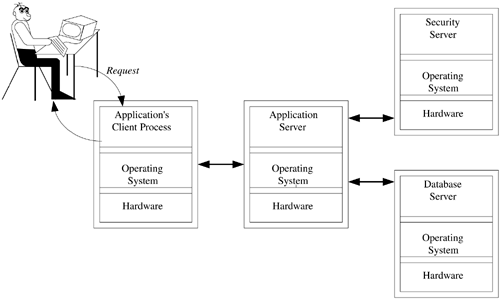 In Figure 5.1 we see what is described as a two- tier architecture: The client is the first tier and the server is the second. Figure 5.3 shows a three-tier architecture, where the middle tier is an application server. We could almost look at the processes that reside on these intermediate tiers as server/client processes at times they are servers and at other times they are clients. Typically, these processes are referred to as servers, since this is their main function. In many environments, we have simply stopped counting the tiers and now refer to them as n-tier implementations. Generally, we see the client process as the part that interacts with the user. Although it is not a requirement, we usually see clients implement a Graphical User Interface (GUI) for accepting commands and data from the user. The client, therefore, manages the mouse clicks, keyboard entries, and data validation. The client must also deal with error recovery. This is especially true with IEBI. The client must not lose context if an error occurs in the midst of a drill-down or rotation. When possible, the system needs to recover and continue processing. Just as the client process has certain requirements, so too does the server. Theoretically, the server has one specific function. Perhaps the server is an access server, as shown in Figure 5.3, or a database server. This is a theoretic view of the server, however. There are times when the system architect for implementation considerations may combine multiple functions in one server. In either case, the server must maintain service. As we noted earlier, if the server dies, the entire system is dead. The level of uptime is based on how critical the application is to the operation of the organization. The highest level of system availability is a fault-tolerant system in which there is 99.999 percent system uptime. This is also referred to as five 9s. This works out to a downtime of approximately 5.25 minutes per year. If our server processes orders for our Web store, we would probably want to maintain this level of system availability. Other applications may require a high availability system, where system uptime is only 99.9 percent. A high availability system can be down roughly 9 hours per year. When considering how critical a system is to the operation of your organization, do not be too quick to label it as nonessential. It wasn't that long ago that email was considered a luxury; now many organizations are stopped dead in their tracks without it. 5.3.1 BENEFITS OF CLIENT/SERVER COMPUTING There were several driving forces behind the adoption of client/server architectures. Some of these forces were technological, some economic, and others political. Client/server architectures were touted as delivering innumerable benefits in each area. Again, quoting our good friend Claudius, "Within every lie, there is a truth, and within every truth, there is a lie." Quite often the enthusiasm to fulfill political needs drove managers to find technological and economic benefits that may not have actually existed. The technological drive behind client/server was, simply stated, that we could do it. Technology up to that point did not make client/server a reasonable alternative for most applications. The dawn of the PC was the first step in making client/server a reality. The PC gave us a platform upon which we could run the client process. This may seem in conflict with what we stressed earlier, that client/server does not necessarily mean a PC for the client and a separate system for the server processes. This isn't really the case. The PC simply made the solution more practical, which is perhaps the origin of the misconception behind the nature of client/server. Consider the alternatives for implementing a client prior to the PC. The first alternative was to create separate processes on the same system, such as a mainframe. In most, if not all, cases this simply did not make sense. Why go through the additional development complexity? There would have to be additional processes to manage the multiple clients and the server process. An easier solution was to create one process that did everything. A second alternative was to use minicomputers and distribute the processing across these systems. Actually, some of the first client/server applications were implemented using this technology, although they may not have been referred to as such. The first client/server system in which I was involved was back in 1978. At that time, we used minicomputers as our clients. The communications protocol was proprietary, and much of the interaction between the client and server processes had to be custom developed. We continued developing applications like this until the mid-1980s. They were large and expensive, which was great for consultants like me. In 1993, I met a systems analyst for a large aerospace company in southern California. He received a very large bonus because he had recognized the expense behind a system I had developed in 1988. It seems that he was able to replace these expensive minicomputers with low-end UNIX workstations. The costs of the new systems were less than the annual maintenance costs for minicomputers. It is more than just the PC that has provided new client alternatives. It is also the rate at which the power of the PC has increased over the years . It wasn't that long ago that a system with a 100-MHz CPU, 64MB RAM, and a 4-GB hard drive was a hefty system. Today we discuss systems with a 2-GHz CPU and 80 GB of disk space. As the power increases , so too does the functionality that we can build into the client-side applications. In 1980, on a small ranch outside Ojai California, I had dinner with a forward-thinking system designer. We had met to plan a way to start a company. We weren't quite sure what it was we wanted to do, but we wanted to do something. I was especially excited about the then burgeoning field of computer graphics. During the course of the evening, he kept repeating the same line: "You don't get it, Bill. Stop thinking of graphics as the output and start thinking of it as the input." He was right on both counts. Initially, most PC application interfaces were character-based, as were their mainframe and mini predecessors. In the mid-1980s, however, we saw the rise of the GUI. Graphics were now the input as well as the output. Client/server applications took advantage of this new way of interacting with the system. In the Character User Interface (CUI) world, users interacted with the system in one of three ways: by command, by menu, or by function keys. The output of these systems was equally uninteresting. The GUI changed how we work with systems. At first, this was not as readily accepted as you might think. The argument was that a true typist never took his or her hands off the keyboard. A GUI forced you to go to a mouse. Forget the fact that most of us aren't true typists a well-designed GUI didn't force you to reach for the mouse. Most continued to employ the use of function keys. Eventually, the obvious benefits of a GUI won out. It provided a richer means of working with applications. A GUI is more than just icons and images. It gives the user a means to visualize not only the data but also the flow of an application. While the benefits of visualization could fill a chapter in and of itself, suffice it to say that visualization is a more powerful means of communicating thoughts and ideas. A visual image leaves a much more lasting impression than mere text. As the old adage goes, a picture is worth a thousand words. The GUI is key for IEBI. One of the most important aspects of any well-designed BI application is that the decision maker is able to interact with the data. Consider for a moment the old way of doing things. A decision maker would ask for a report from IT. In anywhere from a week to a month, he or she would get the report. The report in turn would possibly generate additional questions. The answers to these questions may be embedded in the report in such a way that it would require the analyst to make hand calculations. In many instances, the answers would not be in the report at all, generating a need to request additional reports. There was no way for the IT department to anticipate what additional questions may be asked by the decision maker. With the high turnaround time for reports , the numbers were often stale, and the critical window for the business issue to be resolved had closed. For IEBI to work well, the decision maker needs the ability to interact with the data. In BI, it is easy to visualize what it means to interact with the data . When the decision maker looks at a set of numbers, he or she has an understanding of the significance of those numbers that a software engineer or programmer does not have. When decision makers interact with the data, they can take a number and drill down into the source of that number. They can rotate and aggregate the data to put the number in a different context. Once the numbers are viewed in that new context, the decision maker may gain a new perspective on their significance. He or she might decide to pull in additional information via an ad hoc report. If we look back at the old way of doing things, described in the previous paragraph, this interaction would never have been possible. This is the power of a GUI in an IEBI environment. It provides the decision maker with a means to truly explore the data describing the business environment. The PC, however, was not enough. There was also the development of standard communications protocols. This was an important innovation for the progress of client/server. Prior to standardized protocols, client/server systems custom built their own communications. This meant the development of low-level communications libraries for each new system. This task was further complicated when establishing communications between systems running different operating systems. Standardized communications protocols, such as TCP/IP, made it possible to share information between many varied systems. Developers can easily take advantage of these standardized protocols by integrating standard API (Application Program Interface) calls into their applications, simplifying the process of communicating between systems. Standardized communications freed the system architect to choose from a larger variety of servers. They were no longer limited to a particular vendor or a particular operating system. There was no reason a server running one operating system could not support clients of another. The server, the thing in the back room that no one saw, became a commodity. This was the dawn of the open systems environment . These technological benefits purportedly led to economic benefits. The move from propriety mainframes to standards-based commodity servers drove down the cost of the systems. The price per millions of instructions per second (MIP) for a desktop client was also much less than that of the mainframe. These cost-per-MIP comparisons, while interesting to some, were not very compelling outside the IT department. The large, absolute capital cost savings, however, were compelling to the folks in finance. The initial outlay for a mainframe was far greater than for a UNIX-based system, for example. Cynics might look at this line of reasoning and ask about the cost of the client. Shouldn't the cost of the client be added into the system cost as well? True, but in the interest of consistency, the cost of the client must be amortized over multiple applications. This not only reduces the cost of the client to the new system, but in most cases eliminates it. If the client system is already on the user's desktop, it is inappropriate to burden the cost of the new system with the entire cost of that PC. We are only concerned with the incremental costs. In addition, the move from a proprietary to a more open systems environment was believed to reduce overall system costs. In the proprietary environment, the systems were held hostage by the vendor. The cost of porting an application to another environment was simply too high. Once a vendor had a system installed, the vendor owned the account. In an open systems world, this is not the case. Although moving from one UNIX server to another wasn't always as simple as the proponents of open systems claimed, it was still significantly easier to switch between them. With low change over costs, there is increased competition, which in turn lowers prices. Prices have dropped to such an extent that we now have an open-source market with access to free high-quality software such as LINUX. A final economic benefit is what some call a soft number, not something directly reflected on a balance sheet. This is productivity. Control is taken away from the IT department and delivered to the individual users. They can now perform tasks on their own. More importantly, they are also able to perform tasks in their way. They are freed from the burden of communicating, and at times justifying, their needs to an IT department. An example of this in the IEBI world is the decision maker's ability to interact with the data. The decision maker is now more productive, since he or she has the necessary data when needed. Decision makers are more effective and ultimately more productive. Again we hear that old refrain, within every lie, there is a truth, and within every truth, there is a lie. As stated earlier, the real driving force behind client/server was neither technological nor economic. The true force behind the proliferation of client/server technology was political. The key for this political motivation is described in Bernard Liautaud's book e-Business Intelligence . [3] Liautaud describes the relationship between information dictatorships, information anarchy , and information democracy. Figure 5.4 shows the distinction between these information models. As we see in this figure, an organization's information governance is determined as a function of information control to information access. [3] Liautaud, Bernard, and Hammond, Mark, e-Business Intelligence: Turning Information into Knowledge into Profit , McGraw Hill, 2000. Figure 5.4. Information governance. 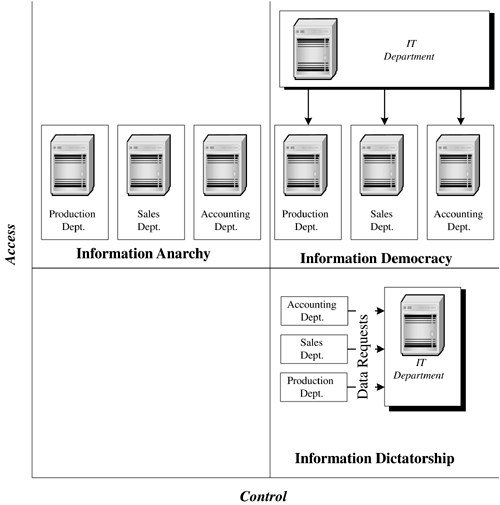 Liautaud cites three models of information governance. The first is information dictatorship. In this model, there is a high degree of control, yet limited access to information. These environments are reminiscent of the mainframe heyday, when requestors of the data approached IT departments as supplicants who petition the high priest of data for the blessings of information. The second model of information governance is information anarchy. In this model, there is a great deal of access to information, yet little if any control. Taken to the extreme, every department has its own server and standards. Applications and metadata vary from organization to organization. While every department has control over its own data, there is little if any sharing of information, making it difficult, if not impossible , to share data between departments. It is often a substantial challenge to glean an enterprise-wide view of the organization from the detritus of information anarchies. The ultimate environment, of course, is one in which there is open access to controlled information. These information governance models are information democracies. In addition to accurately describing the state of many information infrastructures , these models also demonstrate the evolution of information systems. As stated earlier, the true driving force behind the client/server architectures was political. Department managers were tired of struggling with IT to get at the information. There was a coup to overthrow the information dictatorships. Many revolutions in history promised a glorious new world of equality, liberty, and fraternity, but instead led to anarchy. Such was the case with the revolution of information systems. The plethora of departmental point solutions led organizations into information anarchy. It is important to consider the distinction between these different models and the effect they have on the value of an organization's information systems. In Chapter 2, we discussed Bob Metcalfe's description of the value of a network as the number of people on that network squared. Kevin Kelly maintains in New Rules for the New Economy [4] that in the Internet age, multiple simultaneous connections can be made. In such environments, the value of the network increases not by squaring the number of people on the network but by raising the number of people on the network to the power of that number. The key to all this value, however, is the ability to share information. Moving from an information dictatorship to an information anarchy still limits the overall value of the network. In anarchy, while there may be a way to send an electronic signal from one department to another, the ability to share meaningful information is still inhibited. Differing applications and metadata limit the practical sharing of information. This, of course, is all the more critical for IEBI, where the data from these many differing systems is consolidated into one centralized data repository. [4] Kelly, Keven, New Rules for the New Economy , Penguin Books, 1999. The ultimate objective of IEBI is to share information across the entire value chain. If the value of information increases with the number of people who share it, what of the value of IEBI? It is like putting wood on a firethe more wood you add, the hotter the fire. With IEBI, the more information you add, the more valuable the IEBI system. Whether the increase is squared or exponential, the value of the IEBI system is a function of the scope of the data contained within it. If we have a simple data mart whose scope is manufacturing, there is value delivered to the organization. If distribution is added to the scope of the data mart, its value increases. The expanded scope allows analyses that span both manufacturing and distribution. Manufacturing is able to understand both how distribution affects manufacturing and how manufacturing affects distribution. The understanding becomes a two-way street. The same holds true for the distribution department. Each department is better able to understand how its internal processes affect and are affected by other departments. As the IEBI system expands to include all departments throughout the organization, the two-way street evolves into a complex weave of connections between departments. The value of the network begins to rise exponentially. The question with which we are faced, however, is how to evolve the organization from an information anarchy to an information democracy. How do we establish control while providing open access to data throughout our organization? |
