Parsing and Transformation
In order to explore some of the parsing and transformation options available for XML documents, let us create a sample XML message. The following might be sent to a simple stock trading system, to buy 1000 share of Wrox stock:
<?xml version="1.0" encoding="UTF-8"?> <Envelope> <Header> <Service name="buy"/> </Header> <Body> <Trade> <Stock> Wrox </Stock> <Number> 1000 </Number> </Trade> </Body> </Envelope>
We will store this in the file buy. xml, so it can be used in some examples that follow. As we examine some real messaging standards, it will become apparent how much this is over simplified. It does follow a typical message design pattern and for the purposes we hope to illustrate, it is sufficient. Note that we have a packaged the message in an XML envelope; this implies that any data we intend to transmit must be valid XML or the receiver's message handler will throw an exception. We will not deal with packaging non-XML data here (see the previous section). The envelope contains both header sections, which define the remote service we are targeting, and a body, which contains any parameters to pass to the service. Here, we have essentially created a serialized XML version of the following simple Java class:
public class Trade { public String stock; public int number; public Trade (String stock, int number) { this.stock = stock; this.number = number; } }
JAXP
All the parsing examples in this chapter will make use of the Java API for XML Parsing (JAXP). There are in fact a large number of different parsers available. Some of these emphasize speed; others small memory footprint; others conformance to the various parsing specifications that are available. For example, Crimson, the default parser that comes with the distribution, emphasizes a fairly small memory footprint. In contrast, a popular open source parser Xerces (http://xml.apache.org), which also will ultimately be accessible using JAXP, is highly feature rich, but with a larger footprint. The point of JAXP is not to be yet another parser, but to be a pure Java API that can abstract away the implementation details of the common parsers. This way, programmers developing with the JAXP API could later easily substitute in an alterative parser – perhaps to finely tune the balance between performance and resource consumption – without breaking their existing code. Specification of the actual parser instance to instantiate can be made at run time using properties on the Java command line.
| Note | JAXP is registered as JSR 000063 in the Java Community Process (it is actually a follow-up to JSR 000005, adding support for newer specifications and technologies). Download the JAXP distribution from http://www.javasoft.com/xml/download.html. As mentioned above, the distribution comes with an implementation of Sun's Crimson parser (previously known as Project-X), which is a small-footprint parser supporting SAX 2.0 and the DOM level 2 core recommendations.<u> |
DOM and SAX are the two most popular parsing technologies in the XML community. Each approaches parsing in different way. DOM provides an API to traverse and manipulate an XML document as a tree structure. SAX, in contrast, is an event-driven parser. Developers create event handlers that respond to parsing events such as the start or end of the document, an element, a processing instruction, character data, etc. Each has its strengths and limitations, and some parsing applications will naturally lend themselves to one or the other.
| Note | Note that JAXP also supports an abstract transformation interface called TraX. The TraX API allows arbitrary XML transformation engines to be plugged into it. The current version of the JAXP distribution includes the Xalan 2 XSLT parser. XSLT is a transform language for XML. It is extremely powerful, but also a complex language. Wrox has some excellent books covering XSLT.<u> |
At the time of writing, we used JAXP 1.1, early access 2, for all the examples in this chapter.
Tree-Based Parsing
The Document Object Model (DOM) is an API defined by the W3C to inspect and modify XML and HTML documents in a standardized way. The DOM API is actually platform- and language-neutral; implementations of the DOM exist in Java, C++, Visual Basic, and ECMAScript. Documents can be in XML format, or as a special case of this, traditional HTML. The later allows languages like JavaScript to have a standard API to access and manipulate documents residing in the context of a browser. Information about the DOM can be found at http://www.w3.org/dom. The DOM level 1 became a W3C Recommendation in Oct 1998. The DOM level 2, adding support for namespaces and a stylesheet model, was awarded Recommendation status in November 2000.
DOM parsing involves parsing a textual document into a tree of nodes. All the components of the document, including elements, attributes, values, CDATA sections, etc. are contained in node objects; this entire tree of nodes is kept in memory at all times, so large documents can consume considerable memory space and take a while to parse (the lazy DOM was developed to deal with this, and will be explained later). The DOM provides interfaces to inspect each node, alter its contents, get its child nodes, remove nodes, append nodes, etc. Most DOM implementations require a lot of navigation code to walk through this tree, and as a result can become difficult to understand and maintain.
Here is a node tree for the simple buy.xml document described above:
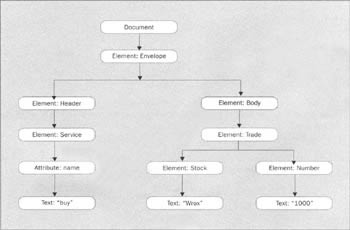
The DOM defines an inheritance hierachy of objects that are used to access nodes in this tree. When a document is parsed using the DOM, the user is returned a root object implementing the org.w3c.dom.Document interface. This object can be thought of as the root of the tree, and is represented above by the Document node. The document interface provides factory methods to create objects in the tree, such as elements, text nodes, attributes, etc. The interface also provides two important navigation methods: getDocument Element() – a convenience routine that returns the document's root element (in our example, element Envelope); and getElementsByTagName () -returns a NodeList, which is a collection of nodes from anywhere in the node tree matching the tag provided as a parameter. As we will see, this is useful for navigating directly to an element.
The following code shows how we might navigate the tree, using DOM interfaces in the JAXP API from Sun:
import java.io.File; import java.io.IOException; // JAXP import javax.xml.parsers.FactoryConfigurationError; import javax.xml.parsers.ParserConfigurationException; import'javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.DocumentBuilder; // DOM import org.w3c.dom.Document; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; import org.w3c.dom.Element; public class DOMExample { public static void main(String[] args) { if (args.length != 1) { System.err.println("Usage: java DOMExample [filename]"); System.exit(1); } DOMExample domExample = new DOMExample(); Document document = domExample.parse(args[0]); if (document != null) domExample.analyze(document); } First of all, let's define the key import statements we will need for the JAXP implementation of a DOM parser, and a basic main () method to get us going. This program will take a single filename as a parameter. Right now, this is just for convenience. Later we can show how the parser can work from a java.lang.String, which would be more likely in a messaging application.
Our main routine simply parses the contents of the file, and then analyses it. In the analysis routine, we will show how we can extract the key serialized parameters of the Trade object. Let's have a look at the parse() method:
public Document parse(String filename) { Document document = null; try { DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance(); documentBuilderFactory.setValidating(false); DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder(); document = documentBuilder.parse(new File(filename)); } catch (ParserConfigurationException e) { System.out.println("Parser does not support feature"); e.printStackTrace(); }catch (FactoryConfigurationError e) { System.out.println("Error occurred obtaining DocumentBuilderFactory."); e.printStackTrace(); } catch (SAXException e) { System.out.println("Caught SAX Exception"); e.printStackTrace(); } catch (IOException e) { System.out.println("Error opening file: " + filename); } return document; } The DocumentBuilderFactory is a JAXP class that abstracts away the instantiation of a parser instance. It allows us to plug in alternative parsers, and choose which parser to instantiate at run time. Right now, we will just take the default parser, which in JAXP 1.1, is Sun's Crimson parser.
Since we have not defined a DTD or schema for our file, we will explicitly turn off validation. The actual parsing is done using the DocumentBuilder.parse() method. This routine returns a document, that we in turn pass back to main().
Note that we are providing a java.io.File object to parse. This method has other signatures, including DocumentBuilder.parse(java.io.Inputs Stream). For example, a valid alternative would have been:
String textInputMsg = "<?xml version=\"1.0\"?> (The rest of the document)"; StringReader stringReader = new StringReader(textInputMsg); InputSource inputSource = new InputSource(stringReader); Document document = documentBuilder.parse(inputSource);
Now that we have our Document instance, let's have a look at the analyze() method, which will navigate this document, extracting some useful data from it. We will do two things: isolate the service name, which is an attribute of the service element, and unserialize the Trade object. The correct term for this is "unmarshaling", but more on that in the upcoming section on data binding:
public void analyze(Document document) { Element rootElement = document.getDocumentElement(); System.out.println("Root element of document is:" + rootElement.getTagName()); First, walk through children looking for the Element node with name Header (bear in mind that XML is case-sensitive):
NodeList nodeList = rootElement.getChildNodes(); Node node = null; Element header = null; int i = 0; while (i < nodeList.getLength()) { node = nodeList.item(i); if (node.getNodeType() == Node.ELEMENT_NODE) { header = (Element) node; if (header.getTagName().compareTo("Header") == 0) break; } i++; } if (i > nodeList.getLength()) { System.err.println"Parse Error: Can't find Header element"); System.exit(0); } Now walk through Header's children looking for the Element node with name Service:
nodeList = header.getChildNodes(); Element service = null; i = 0; while (i <nodeList.getLength()) { node = nodeList.item(i); if (node.getNodeType() == Node.ELEMENT_NODE) { service = (Element) node; if (header.getTagName().compareTo("Service") == 0) break; } i++; } if (i > nodeList.getLength()) { System.err.println("Parse Error: Can't find Service element"); System.exit(0); } // Get attribute value from service String serviceName = service.getAttribute("name"); System.out.println("Service name is: " + serviceName); Unmarshal the Trade object:
nodeList = document.getElementsByTagName("Trade"); if (nodeList.getLength() != 1) { System.err.println("Parse Error: Can't find trade element or multiple " + "trade elements found"); System.exit(0); } Element trade = (Element) nodeList.item(0); //Get stock name nodeList = trade.getElementsByTagName("Stock"); if (nodeList.getLength() != 1) { System.err.println("Parse Error: Can't find Stock element or " + "multiple Stock elements"); System.exit(0); } Node stock = nodeList.item(0); nodeList = stock.getChildNodes(); if (nodeList.getLength()!= 1) { System.err.println("Parse Error: Stock element has multiple children"); System.exit (0); } Node textNode = nodeList.item(0); String stockName = textNode.getNodeValue().trim(); System.out.println("Stock name is: " + stockName); // Get number of shares nodeList = trade.getElementsByTagName("Number"); if (nodeList.getLength() != 1) { System.err.println( "Parse Error: Can't find Number element or multiple Number elements"); System.exit(0); } Node number = nodeList.item(0); nodeList = number.getChildNodes(); if (nodeList.getLength()!= 1) { System.err.println("Parse Error: Number element has multiple children"); System.exit(0); } textNode = nodeList.item(0); String numberStr = textNode.getNodeValue().trim(); int numberValue = (new Integer(numberStr)).intValue(); System.out.println("Number is:" + numberValue); Trade tradeOrder = new Trade(stockName, numberValue); } } First, the code demonstrates the Document.getDocumentElement() convenience routine. Here, we are simply using it so we can gain access of the root element. This is where we will start walking the tree by accessing its children using the method Node.getChildNodes() (remember that the Element interface, like the document interface, extends Node). Tree-walking code is not hard, but it can get a little ugly. In particular, you will quickly discover that our node tree diagram above has been over simplified, and there are a number of additional nodes that complicate the picture, but will still have to be accounted for as we walk the tree. For example, the line feeds and whitespace we added to our buy.xml file are processed quite literally by the parser; this means that a typical element node actually looks like this:
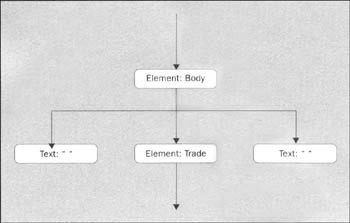
It is up to the application to decide what to do with extra whitespace.
The first part of the code walks down through elements in the order Envelope, Header, Service. Note where we cast a Node into an Element so we can make use of the Element.getTagName() method to make sure we have located the right element. We are casting the service Node to an Element to take advantage of that interface's getAttribute (String) method. Casting may not be an efficient operation in some languages.
| Note | The DOM acknowledges this with support for two perspectives on interfaces: both an inheritance-based object-oriented view, and a "flattened" view, where everything is represented as a Node. An alterative would have been to use the Node.getAttributes() method, which returns a NamedNodeMap that has a similar query function (as well as functions to examine attributes by index), but it returns the attribute again as a Node, so additional steps are still required. |
Once we have found the service name, we try to unserialize (or reconstitute the object from its representation in XML) the Trade object. This time, rather than tree-walking, we will simplify things by making use of the getElementsByTagName() method on the Document and Element interfaces. These return a NodeList, which is a container holding references to the all nodes underneath the Document or Element that match the tag name. This is both good and bad: while it greatly simplifies navigation, it also means that you may inadvertently pull out unexpected elements from deep within your structure. One of the reasons namespaces were invented was to avoid these kinds of element name collisions. Be careful though, DOM level I does not support them (DOM level 2, used here, does). (A better way of querying documents is to use XPath expressions, which we will not cover here. Have a look at http://www.w3.org/TR/xpath.)
Most of the code for unserializing Trade is straightforward, but there are a few things to note. First, we isolate the Trade element from the document root; we then use this new Element root to search deeper in the structure for the Stock and Number elements. The point of this is to demonstrate how we can segment off parts of a tree to minimize the search space and in doing so create a more accurate search. Note that getNodeValue() is returning only strings, which are DOM's fundamental representation of everything, so we must cast where appropriate. It's not apparent here, but if we had any entity references in our document, DOM would have substituted these for their entity values internally during parsing. Thus, you cannot isolate entity references using DOM. For example, if we replaced the string "Wrox" with an entity reference, the value of element Stock would still be Wrox books:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE Envelope [ <!ENTITY stockName "Wrox"> ]> <Envelope> <Header> <Service name="buy"/> </Header> <Body> <Trade xmlns:n="http://www.infowave.com/nameSpaces"> <Stock> &stockName; books </Stock> <Number> 1000 </Number> </Trade> </Body> </Envelope>
To test the code, copy the DOMExample.java, Trade.java and buy.xml files to the same directory and make sure you have., jaxp.jar, and crimson.jar in your classpath:

Although this code works, and demonstrates two methods of navigating a DOM structure, it has some practical problems. This code is very brittle. Knowledge of the document organization is woven throughout the Java code: if we make any significant structural changes to our document, the code will have to be changed by hand. For example, suppose we added an inner envelope to our document structure:
<?xml version="1.0" encoding=UTF-8"?> <Envelope> <InnerEnvelope> <Header> ... </Header> <Body> ... </Body> </InnerEnvelope> </Envelope>
The first part of our example, where we walk the tree, would fail because it effectively has the previous structure hard-coded into it. The second part, however, which uses queries on the tag name, would still function correctly. Any changes to tag names would break both methods, which unfortunately have these embedded in the code.
This code is also difficult to follow, and contains a number of reoccurring patterns. It is not hard to imagine how difficult the maintenance of such a program would be. This does beg the question of why you would write the code in the first place. Since really the Java code is being driven by the message structure, couldn't we simply automatically generate this code based on knowledge of the message organization? This is the subject of the upcoming section on data binding.
Event-Based Parsing
Although the DOM is very flexible, it does have some drawbacks. We have seen how awkward tree walking code can become. There are also some practical considerations with using the DOM. When you parse a document, the entire structure is built in memory as a tree of nodes. Every node is an object that must be instantiated. This can consume a lot of memory if the document is large. It also isn't very fast. If a node has siblings, children, or a parent, links must be created to articulate these relationships. The DOM uses strings in its interfaces, which is not very efficient in most languages, Java included. DOM processing overhead can be a problem if the goal is to build a highly scalable application that is required to process a high volume of XML messages.
The Simple API for XML (SAX) was designed to address some of these issues. SAX is an event-based parser. Rather than creating a parse tree, SAX provides application designers with a callback interface. As the XML document is processed, these interfaces are called; designers can build their own handlers to responds to these events. The design of SAX was actually a collaborative effort by members of the XML-DEV mailing list, coordinated by David Megginson.
There are a few key advantages to parsing with SAX. SAX operates on streams, so does not need to keep a representation of the entire document in memory at one time. For the same reason, it is also very fast because there are no significant objects to initialize and assemble into a tree structure, like DOM. The parser's code typically also has a very small memory footprint, which is advantageous for resource-constrained devices. As we will see, SAX is very well suited for unmarshaling objects that have been serialized in documents. It is not so well suited for applications where you need random access to the document, or you want to modify the document significantly; in this case, use DOM.
SAX defines a number of callbacks, but the most commonly used are:
DefaultHandler.startDocument() DefaultHandler.endDocument() DefaultHandler.startElement(String uri, String locaName, String Qname, Attributes attr) DefaultHandler.endElement(String uri, String locaName, String Qname) DefaultHandler.characters(char[] ch, int start, int length)
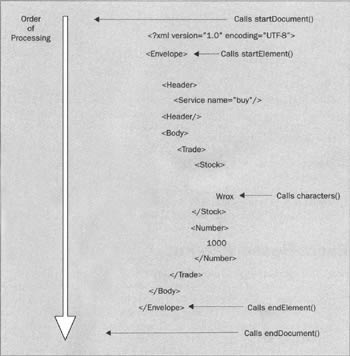
SAX provides the org.xml.sax.helpers.DefaultHandler class with empty methods. Application designers extend this class, overriding the handlers with their own customized implementation. An instance of this class is then registered with the SAX parser. The SAX parser processes the document as a stream, activating each callback at appropriate times. For example, given our test message, SAX would call methods at the following times (We are only showing a single example call for the Envelope element and the Wrox character text for clarity – in reality each element and string of character data would result in a call to the appropriate method):
This is all probably best demonstrated with an example. The following uses the SAX 2.0 conventions, which have changed slightly from the previous version, and so may not exactly match other examples you may come across:
import java.io.File; import java.io.IOException; import java.net.MalformedURLException; // SAX related classes import org.xml.sax.XMLReader; import org.xml.sax.InputSource; import org.xml.sax.SAXException; // JAXP related imports import javax.xml.parsers.SAXParser; import javax.xml.parsers.SAXParserFactory; import javax.xml.parsers.FactoryConfigurationError; import javax.xml.parsers.ParserConfigurationException; public class SAXExample { public static void main (String args[]) { if (args.length != 1) { System.err.println("Usage: java SAXExample [filename]"); System.exit(1); } SAXExample saxExample = new SAXExample(); saxExample.parse(args[0]); } public void parse(String filename) { // Create SAXParserFactory based on the JAXP distribution SAXParserFactory saxParserFactory = null; try { saxParserFactory = SAXParserFactory.newInstance(); } catch (FactoryConfigurationError e) { System.err.println("Factory does not recognize parser."); System.exit(0); } try { // Create SAXParser and XMLReader based on the JAXP distribution SAXParser saxParser = saxParserFactory.newSAXParser(); XMLReader xmlReader = saxParser.getXMLReader(); SAXExampleHandler saxExampleHandler = new SAXExampleHandler(); xmlReader.setContentHandler(saxExampleHandler); xmlReader.setErrorHandler(saxExampleHandler); // Parse file try { InputSource inputSource = new InputSource((new File (filename)).toURL().toString()); xmlReader.parse(inputSource); Trade tradeOrder = saxExampleHandler.getTrade(); System.out.println( "Trade order for " + tradeOrder.number + " shares of stock " + tradeOrder.stock); } catch (MalformedURLException e) { System.err.println("Bad filename: " + filename); } catch (IOException e) { System.err.println ("IO Exception on filename: " + filename); } } catch (ParserConfigurationException e) { System.err.println("Error configuring feature in parser."); } catch (SAXException e) { System.err.println("Received SAXException: " + e); } } } Like the DOM example, this program takes a file name as argument. The parse() method uses the JAXP API to instantiate a SAX parser (once again using Sun's Crimson parser underneath the hood). The code instantiates a SAXExampleHandler (which is our implementation of the DefaultHandler class) and registers it with the parser. Note that XMLReader.parse() method is expecting an org.xml.sax.InputSource object. The InputSource class allows us to wrap various sources, including a text string. Here, we are giving a string URL. To get this, we are taking advantage of the Java 1.2 modification to the File class that provides a toURL() method. As an alterative, the InputSource can wrap a text string. This would be a more likely scenario for a JMS application. For example:
String textInputMsg = "<?xml version=/"1.0/" ..."; StringReader stringReader = new StringReader(textInputMsg); try { InputSource inputSource = new InputSource(stringReader); xmlReader.parse(inputSource); } As the SAX parser processes the InputSource, it calls the methods of the handler. Here is what the handler code looks like:
// SAX related classes import org.xml.sax.Attributes; import org.xml.sax.helpers.DefaultHandler; public class SAXExampleHandler extends DefaultHandler { private java.lang.StringBuffer charBuffer = new StringBuffer(); private int numberValue; private java.lang.String serviceName; private java.lang.String stockName; private Trade tradeOrder; public void startDocument(){ System.out.println("Start document processing..."); } public void endDocument(){ System.out.println("End document processing"); // Create our Trade object tradeOrder = new Trade(stockName, numberValue); } public void startElement(String uri, String name, String qName, Attributes attributes) { if (name.compareTo("Service")==0){ serviceName=attributes.getValue(uri, "name"); } // Reset char buffer whenever we start a new element charBuffer.setLength(0); } public void endElement(String uri, String name, String qName) { // Record any serialized attributes of the Java Trade class if (name.compareTo("Stock") == 0) { stockName = charBuffer.toString().trim(); System.out.println("Stock is: " + stockName); } else if (name.compareTo("Number") == 0) { numberValue = (new Integer (charBuffer.toString().trim()).intValue(); System.out.println("Number is: " + numberValue); } } public void characters (char ch[], int start, int length){ // Append characters to the current char buffer charBuffer.append(ch, start, length); } Trade getTrade() { return tradeOrder; } } There are a couple of important things to notice here. SAX does not guarantee that a callback to characters() will return all the text between elements in a single call. Although in general you will observe that character data is aggregated in a single callback to characters(), SAX makes no promises about how characters could be broken up, or "chunked" by the SAX driver. Furthermore, you may not notice this behavior until the parser encounters a sequential character stream. For example, the following XML fragment:
<Stock> Wrox books </Stock>
Could potentially result in the following call sequence:
-
startElement() – Called for Stock opening tag
-
characters() – Called for \n\tWrox fragment
-
characters() – Called for books\n fragment
-
endElement() – Called for Stock closing tag
Here, rather than a single call to characters() with the char array \n\tWrox books\n, there are two separate callbacks. This is why we are actually collecting the character strings in the StringBuffer instance charBuffer, which is reset at on each startElement() callback and examined at each endElement() callback. Some newer SAX parsers may provide developers with a feature that can be set that forces aggregation of multiple sequential characters() calls into one.
Note also that we are checking element names in the endElement() callback, and storing the results as Java attributes of our handler class. When we have reached the end of our document, we take the stockName and numberValue elements and construct a Trade object, which is accessible via an accessor method getTrade() in the handler class. Thus, our main routine can get access to this unmarshaled object.
Locating the value of the name attribute in the Service tag is very simple. Here, we simply check the tag name any time the startElement() callback is active. One of the parameters of this method is an Attributes class, which has a number of convenience accessors for examining attributes and their values.
Overall, the code is much simpler and easier to follow – and will be similarly easier to maintain. Since we are targeting elements only by name, we are resilient against most structural changes that could occur in the message. Nevertheless, we still have the problem of potentially running into element naming conflicts. Namespaces offer one answer to this. Another is adding logic to track exactly where we are in the document, based on calls to startElement() and endElement().
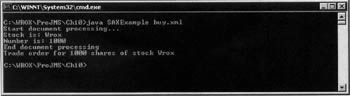
Test the code in exactly the same way as before, passing in the buy.xml file as argument, and the output should be the same:
SAX does have its drawbacks. In contrast to DOM, which provides CRUD (Create, Retrieve, Update, and Delete) interfaces for nodes, SAX is fundamentally a read-only technology. It also processes the stream using one pattern, effectively a depth-first search. There is no interface available to provide random access to the document. Furthermore, as documents become more complex, the handler can become elaborate, leaving us again with a difficult-to-maintain piece of code.
Java XML Data Binding
Both DOM and SAX provide flexible means to process XML documents. But as we saw in the last two sections, the Java code that does this can become very tedious. Notice, however, that with both the DOM and SAX implementations, there were many repeated code patterns; once you found one element, you could use the same tricks to find them all. The document structure also drove the code; this meant that the code was highly coupled to the document organization and thus intolerant to change (notwithstanding our opening assertion that XML is flexible under such conditions). It also forces Java programmers to learn about the details of XML, which is predicated on a very different data model from Java.
The key observation to make in the DOM and SAX examples is that the end result is really just to extract a Trade object from its serialized form in the XML document. And the steps to do this are quite mechanical, as shown.
Data binding is the process of mapping between objects in a language like Java (or C++, Visual Basic, etc.) and an XML document. It provides for a graph of Java objects to be marshaled into an XML document representation. It also provides for the reverse: to unmarshal an XML document into a graph of Java objects:
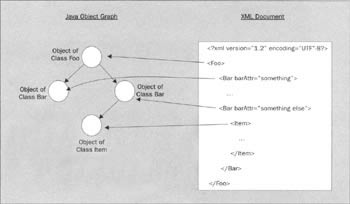
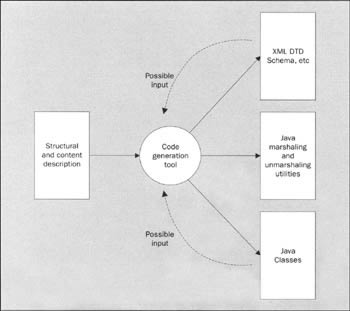
The key observation to make here is that the code needed to apply this is deterministic. The utility functions that affect these transforms (as well as Java code describing the data classes and a representation of the XML document schema) should be able to be automatically generated from a common underlying structural representation. This representation could be an XML Schema or DTD, a predefined set of Java classes, or some kind of generic modeling language, such as XMI, the XML Metadata Interchange. This is an XML language used mainly for exchanging model data between UML modeling tools.
| Note | The XMI specification is promoted by the Object Management Group (OMG), an industry organization responsible for standardizing object technologies. CORBA and UML are some of its higher profile efforts. Download the XMI specification from: ftp://ftp.omg.org/pub/docs/formal/00-11-02.pdf. |
If this sounds vaguely familiar, you've probably already used similar technology. It has become very common to use code generation to create a binding between Java objects and relational databases. EJB Entity Beans, Java Data Objects, and a host of proprietary vendor solutions do a similar thing: map between Java and SQL type systems. Java programmers simply work with Java objects, which are proxies for data residing in tables in the underlying database.
| Note | For more about Java Data Objects, registered as JSR-000012, see http://java.sun.com/aboutJava/communityprocess/jsr/jsr_012_dataobj.html. |
This sounds like a simple operation, but it is actually quite complex. XML on its own is very weakly typed – everything is a string. Once we impose typing on a document using a description like schema, we still have to map between this and the type system of the language we are using. There is not always a clean match. For example, consider enumerations, which exist in XML Schema. Enumerations exist in C/C++ and Visual Basic, but there is no equivalent base type in Java. Furthermore, our Java classes must enforce schema constraints such as minimum and maximum number of items (again assuming XML Schema); otherwise, an object graph may marshal into an invalid document. If constraints exist in preexisting Java code, these too should be mapped into schema equivalents to ensure that the document can be unmarshaled without causing an error.
There are some real benefits to data binding. Some of these make it particularly well suited for messaging applications. Java programmers simply work with Java classes, something to which they are accustomed. The utility classes encapsulate parsing complexity, so programmers really do not need to learn anything about XML. As we have observed, the utility classes should be code generated. This eliminates a significant potential source of errors. We still, of course, have a very tight coupling between document structure and Java code; however at least we can easily regenerate code when changes are mandated.
At present, XML/Java data binding tools are still uncommon. The XML Data Binding Specification also goes by the name Project Adelard. The Castor Project is developing code generation for bindings between XML, Java, and Java Data Objects (JDO). Breeze XML Studio, from The Breeze Factor is a commercial package that is available now that has much of the functionality described. It is anticipated that similar functionality will be made available in upcoming versions of Microsoft Visual Studio in support of its .NET initiative. In the emerging web services arena, toolkits are appearing that create proxy objects for Simple Object Access Protocol (SOAP) accessible web services. These implicitly marshal and unmarshal to SOAP style messages. Microsoft's ROPE a part of its SOAP toolkit – implements some of these features.
| Note | For more about Project Adelard, registered as JSR-000031 under the Java Community Process, see http://java.sun.com/aboutJava/communityprocess/jsr/jsr_031_xmld.html. For the Castor Project, see http://castor.exolab.org. For the Breeze Factor, see http://www.breezefactor.com. |
EAN: 2147483647
Pages: 154