5. Image and Video Databases
5. Image and Video Databases
Image and video databases have particular requirements and characteristics, the most important of which will be outlined in this Section and described in much more detail along other chapters in this Handbook. Some of the technical challenges are common to both types of media, such as the realization that raw contents alone are not useful, unless they are indexed for further query and retrieval, which makes the effective indexing of images and video clips an ongoing research topic.
After having been catalogued, it should be possible to query and retrieve images and video clips based on their semantic meaning, using a measure of similarity between the query terms (textual or otherwise) and the database contents. Since in most cases there is no exact matching between the query and its expected result, there is a need to extend the information retrieval approaches to search based on similarity to the case where the mapping between visual and semantic similarity is not straightforward. These issues will be explored within the realm of image databases in Section 5.1. An extension to video and its specific challenges and complexities will be presented in Section 5.2.
5.1 Image Databases
The design of image databases brings about the need for new abstractions and techniques to implement these abstractions.
Since raw images alone have very limited usefulness, some technique must be devised to extract and encode the image properties into an alphanumerical format that is amenable to indexing, similarity calculations, and ranking of best results. These properties can be extracted using state-of-the-art computer vision algorithms. Examples of such properties include: shape, color, and texture. These descriptors are recognizably limited and very often fail to capture the semantic meaning of the image, giving rise to the well-known semantic gap problem. Moreover, some of these descriptors are only useful if applied to the relevant objects within an image, which calls for some sort of segmentation to occur. Automatic segmentation of a scene into its relevant objects is still an unresolved problem, and many attempts in this field get around this problem by including the user in the loop and performing a semi-automatic segmentation instead.
Storing a set of images so as to support image retrieval operations is usually done with spatial data structures, such as R-trees and a number of variants (e.g., R+ trees, R* trees, SS-trees, TV-trees, X-trees, M-trees) proposed in the literature.
Indexing of images is another open research problem. Raw images must have their contents extracted and described, either manually or automatically. Automatic techniques usually rely on image processing algorithms, such as shape-, color-, and texture-based descriptors. Current techniques for content-based indexing only allow the indexing of simple patterns and images, which hardly match the semantic notion of relevant objects in a scene. The alternative to content-based indexing is to assign index terms and phrases through manual or semi-automatic indexing using textual information (usually referred to as metadata), which will then be used whenever the user searches for an image using a query by keyword.
The information-retrieval approach to image indexing is based on one of the three indexing schemes [2]:
-
Classificatory systems: images are classified hierarchically according to the category to which they belong.
-
Keyword-based systems: images are indexed based on the textual information associated with them.
-
Entity-attribute-relationship systems: all objects in the picture and the relationships between objects and the attributes of the objects are identified.
Querying an image database is fundamentally different from querying textual databases. While a query by keyword usually suffices in the case of textual databases, image databases users normally prefer to search for images based on their visual contents, typically under the query by example paradigm, through which the user provides an example image to the system and (sometimes implicitly) asks the question: "Can you find and retrieve other pictures that look like this (and the associated database information)?" Satisfying such a query is a much more complex task than its text-based counterpart for a number of reasons, two of which are: the inclusion of a picture as part of a query and the notion of "imprecise match" and how it will be translated into criteria and rules for similarity measurements. The most critical requirement is that a similarity measure must behave well and mimic the human notion of similarity for any pair of images, no matter how different they are, in contrast with what would typically be required from a matching technique, which only has to behave well when there is relatively little difference between a database image and the query [7].
There are two main approaches to similarity-based retrieval of images [8]:
-
Metric approach: assumes the existence of a distance metric d that can be used to compare any two image objects. The smaller the distance between the objects, the more similar they are considered to be. Examples of widely used distance metrics include: Euclidean, Manhattan, and Mahalanobis distance.
-
Transformation approach: questions the claim that a given body of data (in this case, an image) has a single associated notion of similarity. In this model, there is a set of operators (e.g., translation, rotation, scaling) and cost functions that can be optionally associated with each operator. Since it allows users to personalize the notion of similarity to their needs, it is more flexible than the metric approach; however, it is less computationally efficient and its extension to other similar queries is not straightforward.
There are many (content-based) image retrieval systems currently available, in the form of commercial products and research prototypes. For the interested reader, Veltkamp and Tanase [9] provide a comprehensive review of existing systems, their technical aspects, and intended applications.
5.2 Video Databases
The challenges faced by researchers when implementing image databases increase even further when one moves from images to image sequences, or video clips, mostly because of the following factors:
-
increased size and complexity of the raw media (video, audio, and text);
-
wide variety of video programs, each with its own rules and formats;
-
video understanding is very much context-dependent;
-
the need to accommodate different users, with varying needs, running different applications on heterogeneous platforms.
As with its image counterpart, raw video data alone has limited usefulness and requires some type of annotation before it is catalogued for later retrieval. Manual annotation of video contents is a tedious, time consuming, subjective, inaccurate, incomplete, and - perhaps more importantly - costly process. Over the past decade, a growing number of researchers have been attempting to fulfill the need for creative algorithms and systems that allow (semi-) automatic ways to describe, organize, and manage video data with greater understanding of its semantic contents.
The primary goal of a Video Database Management System (VDBMS) is to provide pseudo-random access to sequential video data. This goal is normally achieved by dividing a video clip into segments, indexing these segments, and representing the indexes in a way that allows easy browsing and retrieval. Therefore, it can be said that a VDBMS is basically a database of indexes (pointers) to a video recording [10].
Similarly to image databases, much of the research effort in this field has been focused on modeling, indexing, and structuring of raw video data, as well as finding suitable similarity-based retrieval measures. Another extremely important aspect of a VDBMS is the design of its graphical user interface (GUI). These aspects will be explored in a bit more detail below.
5.2.1 The main components of a VDBMS
Figure 1.3 presents a simplified block diagram of a typical VDBMS. Its main blocks are:
-
Digitization and compression: hardware and software necessary to convert the video information into digital compressed format.
-
Cataloguing: process of extracting meaningful story units from the raw video data and building the corresponding indexes.
-
Query / search engine: responsible for searching the database according to the parameters provided by the user.
-
Digital video archive: repository of digitized, compressed video data.
-
Visual summaries: representation of video contents in a concise, typically hierarchical, way.
-
Indexes: pointers to video segments or story units.
-
User interface: friendly, visually rich interface that allows the user to interactively query the database, browse the results, and view the selected video clips.
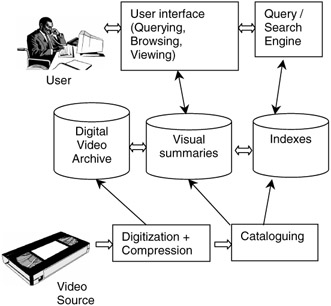
Figure 1.3: Block diagram of a VDBMS.
5.2.2 Organization of video content
Because video is a structured medium in which actions and events in time and space convey stories, a video program must not be viewed as a non-structured sequence of frames, but instead it must be seen as a document. The process of converting raw video into structured units, which can be used to build a visual table of contents (ToC) of a video program, is also referred to as video abstraction. We will divide it into two parts:
-
Video modeling and representation
-
Video segmentation (parsing) and summarization
Video modeling and representation
Video modeling can be defined as the process of designing the representation for the video data based on its characteristics, the information content, and the applications it is intended for. Video modeling plays a key role in the design of VDBMSs, because all other functions are more or less dependent on it.
The process of modeling video contents can be a challenging task, because of the following factors:
-
video data carry much more information than textual data;
-
interpretation is usually ambiguous and depends on the viewer and the application;
-
the high dimensionality of video data objects;
-
lack of a clear underlying structure;
-
massive volume (bytes);
-
relationships between video data segments are complex and ill-defined.
When referring to contents of video data, the following distinctions should be made, according to their type and level [11]:
-
Semantic content: the idea or knowledge that it conveys to the user, which is usually ambiguous, subjective, and context-dependent.
-
Audiovisual content: low-level information that can be extracted from the raw video program, usually consisting of color, texture, shape, object motion, object relationships, camera operation, audio track, etc.
-
Textual content: additional information that may be available within the video stream in the form of captions, subtitles, etc.
Some of the requirements for a video data model are [11]:
-
Support video data as one of its data types, just like textual or numeric data.
-
Integrate content attributes of the video program with its semantic structure.
-
Associate audio with visual information.
-
Express structural and temporal relationships between segments.
-
Automatically extract low-level features (color, texture, shape, motion), and use them as attributes.
Most of the video modeling techniques discussed in the literature adopt a hierarchical video stream abstraction, with the following levels, in decreasing degree of granularity:
-
Key-frame: most representative frame of a shot.
-
Shot: sequence of frames recorded contiguously and representing a continuous action in time or space.
-
Group: intermediate entity between the physical shots and semantic scenes that serves as a bridge between the two.
-
Scene or Sequence: collection of semantically related and temporally adjacent shots, depicting and conveying a high-level concept or story.
-
Video program: the complete video clip.
A video model should identify physical objects and their relationships in time and space. Temporal relationships should be expressed by: before, during, starts, overlaps, etc., while spatial relationships are based on projecting objects on a 2-D or 3-D coordinate system.
A video model should also support annotation of the video program, in other words the addition of metadata to a video clip. For the sake of this discussion, we consider three categories of metadata:
-
content-dependent metadata (e.g., facial features of a news anchorperson);
-
content-descriptive metadata (e.g., the impression of anger or happiness based on facial expression);
-
content-independent metadata (e.g., name of the cameraman).
Video data models can usually be classified into the following categories [11] (Figure 1.4):
-
Models based on video segmentation: adopt a two-step approach, first segmenting the video stream into a set of temporally ordered basic units (shots), and then building domain-dependent models (either hierarchy or finite automata) upon the basic units.
-
Models based on annotation layering (also known as stratification models): segment contextual information of the video and approximate the movie editor's perspective on a movie, based on the assumption that if the annotation is performed at the finest grain (by a data camera), any coarser grain of information may be reconstructed easily.
-
Video object models: extend object-oriented data models to video. Their main advantages include the ability to represent and manage complex objects, handle object identities, encapsulate data and associated methods into objects, and inherit attribute structures and methods based on class hierarchy.
-
Algebraic video data models: define a video stream by recursively applying a set of algebraic operations on the raw video segment. Their fundamental entity is a presentation (multi-window, spatial, temporal, and content combination of video segments). Presentations are described by video expressions, constructed from raw segments using video algebraic operations. As an example of the algebraic approach to video manipulation, the reader is referred to Chapter 19 of this Handbook, where Picariello, Sapino, and Subrahmanian introduce AVE! (Algebraic Video Environment), the first algebra for querying video.
-
Statistical models: exploit knowledge of video structure as a means to enable the principled design of computational models for video semantics, and use machine learning techniques (e.g., Bayesian inference) to learn the semantics from collections of training examples, without having to rely on lower level attributes such as texture, color, or optical flow. Chapter 3 of this Handbook contains an example of statistical modeling of video programs, the Bayesian Modeling of Video Editing and Structure (BMoViES) system for video characterization, developed by Nuno Vasconcelos.
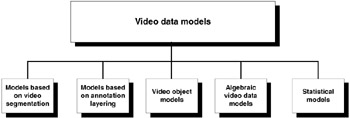
Figure 1.4: Classification of video data models.
Video segmentation
Video segmentation (also referred to as video parsing) is the process of partitioning video sequences into smaller units. Video parsing techniques extract structural information from the video program by detecting temporal boundaries and identifying meaningful segments, usually called shots. The shot ("a continuous action on screen resulting from what appears to be a single run of the camera") is usually the smallest object of interest. Shots are detected automatically and typically represented by key-frames.
Video segmentation can occur either at a shot level or at a scene level. The former is more often used and sometimes referred to as shot detection. Shot detection can be defined as the process of detecting transitions between two consecutive shots, so that a sequence of frames belonging to a shot will be grouped together. There are two types of shot transitions: abrupt transitions (or cuts) and gradual transitions (e.g., fade-in, fade-out, dissolve). Earlier work on shot detection addressed only the detection of cuts, while more recent research results report successful techniques for detection of gradual transitions as well.
An alternative to shot detection, scene-based video segmentation consists of the automatic detection of semantic boundaries (as opposed to physical boundaries) within a video program. It is a much more challenging task, whose solution requires a higher level of content analysis, and the subject of ongoing research. Three main strategies have been attempted to solve the problem:
-
Segmentation based on film production rules (e.g., transition effects, shot repetition, appearance of music in the soundtrack) to detect local (temporal) clues of macroscopic change;
-
Time-constrained clustering, which works under the rationale that semantically related contents tend to be localized in time;
-
A priori model-based algorithms, which rely on specific structural models for programs whose temporal structures are usually very rigid and predictable, such as news and sports.
Video segmentation can occur either in the uncompressed or compressed domain. In the uncompressed domain, the basic idea upon which the first algorithms were conceived involved the definition of a similarity measure between successive images and the comparison of successive frames according to that measure: whenever two frames are found to be sufficiently dissimilar, there may be a cut. Gradual transitions are found by using cumulative difference measures and more sophisticated thresholding schemes. Temporal video segmentation techniques that work directly on the compressed video streams were motivated by the computational savings resulting from not having to perform decoding/re-encoding, and the possibility of exploiting pre-computed features, such as motion vectors (MVs) and block averages (DC coefficients), that are suitable for temporal video segmentation.
Temporal video segmentation has been an active area of research for more than 10 years, which has resulted in a great variety of approaches. Early work focused on cut detection, while more recent techniques deal with gradual transition detection. Despite the great evolution, most current algorithms exhibit the following limitations [12]:
-
They process unrealistically short gradual transitions and are unable to recognize the different types of gradual transitions;
-
They involve many adjustable thresholds;
-
They do not handle false positives due to camera operations.
For a comprehensive review of temporal video segmentation, the interested reader is referred to a recent survey by Koprinska and Carrato [12].
Video summarization
Video summarization is the process by which a pictorial summary of an underlying video sequence is presented in a more compact form, eliminating - or greatly reducing - redundancy. Video summarization focuses on finding a smaller set of images (key-frames) to represent the visual content, and presenting these key-frames to the user.
A still-image abstract, also known as a static storyboard, is a collection of salient still images or key-frames generated from the underlying video. Most summarization research involves extracting key-frames and developing a browser-based interface that best represents the original video. The advantages of a still-image representation include:
-
still-image abstracts can be created much faster than moving image abstracts, since no manipulation of the audio or text information is necessary;
-
the temporal order of the representative frames can be displayed so that users can grasp concepts more quickly;
-
extracted still images are available for printing, if desired.
An alternative to still-image representation is the use of video skims, which can be defined as short video clips consisting of a collection of image sequences and the corresponding audio, extracted from the original longer video sequence. Video skims represent a temporal multimedia abstraction that is played rather than viewed statically. They are comprised of the most relevant phrases, sentences, and image sequences and their goal is to present the original video sequence in an order of magnitude less time. There are two basic types of video skimming:
-
Summary sequences: used to provide a user with an impression of the video sequence.
-
Highlights: contain only the most interesting parts of a video sequence.
Since the selection of highlights from a video sequence is a subjective process, most existing video-skimming work focuses on the generation of summary sequences.
A very important aspect of video summarization is the development of user interfaces that best represent the original video sequence, which usually translates into a trade-off between the different levels and types of abstractions presented to the user: the more condense the abstraction, the easier it is for a potential user to browse through, but maybe the amount of information is not enough to obtain the overall meaning and understanding of the video; a more detailed abstraction may present the user with enough information to comprehend the video sequence, which may take too long to browse.
Emerging research topics within this field include adaptive segmentation and summarization (see Chapters 11 and 12) and summarization for delivery to mobile users (see Chapter 14).
5.2.3 Video indexing, querying, and retrieval
Video indexing is far more difficult and complex than its text-based counterpart. While on traditional DBMS, data are usually selected based on one or more unique attributes (key fields), it is neither clear nor easy to determine what to index a video data on. Therefore, unlike textual data, generating content-based video data indexes automatically is much harder.
The process of building indexes for video programs can be divided into three main steps:
-
Parsing: temporal segmentation of the video contents into smaller units.
-
Abstraction: extracting or building a representative subset of video data from the original video.
-
Content analysis: extracting visual features from representative video frames.
Existing work on video indexing can be classified in three categories [11]:
-
Annotation-based indexing
Annotation is usually a manual process performed by an experienced user, and subject to problems, such as: time, cost, specificity, ambiguity, and bias, among several others. A commonly used technique consists of assigning keyword(s) to video segments (shots). Annotation-based indexing techniques are primarily concerned with the selection of keywords, data structures, and interfaces, to facilitate the user's effort. But even with additional help, keyword-based annotation is inherently poor, because keywords:
-
Do not express spatial and temporal relationships;
-
Cannot fully represent semantic information and do not support inheritance, similarity, or inference between descriptors;
-
Do not describe relations between descriptions.
Several alternatives to keyword-based annotation have been proposed in the literature, such as the multi-layer, iconic language, Media Streams [14].
-
-
Feature-based indexing
Feature-based indexing techniques have been extensively researched over the past decade. Their goal is to enable fully automated indexing of a video program based on its contents. They usually rely on image processing techniques to extract key visual features (color, texture, object motion, etc.) from the video data and use these features to build indexes. The main open problem with these techniques is the semantic gap between the extracted features and the human interpretation of the visual scene.
-
Domain-specific indexing
Techniques that use logical (high-level) video structure models (a priori knowledge) to further process the results of the low-level video feature extraction and analysis stage. Some of the most prominent examples of using this type of indexing technique have been found in the area of summarization of sports events (e.g., soccer), such as the work described in Chapters 5 and 6 of this Handbook.
The video data retrieval process consists of four main steps [11]:
-
User specifies a query using the GUI resources.
-
Query is processed and evaluated.
-
The value or feature obtained is used to match and retrieve the video data stored in the VDB.
-
The resulting video data is displayed on the user's screen for browsing, viewing, and (optionally) query refining (relevance feedback).
Queries to a VDBMS can be classified in a number of ways, according to their content type, matching type, granularity, behavior, and specification [11], as illustrated in Figure 1.5. The semantic information query is the most difficult type of query, because it requires understanding of the semantic content of the video data. The meta information query relies on metadata that has been produced as a result of the annotation process, and therefore, is similar to conventional database queries. The audiovisual query is based on the low-level properties of the video program and can be further subdivided into: spatial, temporal, and spatio-temporal. In the case of deterministic query, the user has a clear idea of what she expects as a result, whereas in the case of browsing query, the user may be vague about his retrieval needs or unfamiliar with the structures and types of information available in the video database.
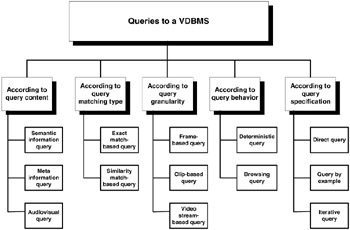
Figure 1.5: Classification of queries to a VDBMS.
Video database queries can be specified using extensions of SQL for video data, such as TSQL2, STL (Spatial Temporal Logic), and VideoSQL. However, query by example, query by sketch, and interactive querying/browsing/viewing (with possible relevance feedback) are more often used than SQL-like queries.
Query processing usually involves four steps [11]:
-
Query parsing: where the query condition or assertion is usually decomposed into the basic unit and then evaluated.
-
Query evaluation: uses pre-extracted (low-level) visual features of the video data.
-
Database index search.
-
Returning of results: the video data are retrieved if the assertion or the similarity measurement is satisfied.
As a final comment, it should be noted that the user interface plays a crucial role in the overall usability of a VDBMS. All interfaces must be graphical and should ideally combine querying, browsing summaries of results, viewing (playing back) individual results, and providing relevance feedback and/or query refinement information to the system. Video browsing tools can be classified in two main types:
-
Time-line display of video frames and/or icons: video units are organized in chronological sequence.
-
Hierarchical or graph-based story board: representation that attempts to present the structure of video in an abstract and summarized manner.
This is another very active research area. In a recent survey, Lee, Smeaton, and Furner [13] categorized the user-interfaces of various video browsing tools and identified a superset of features and functions provided by those systems.
EAN: 2147483647
Pages: 393