Section 8.9. Validating HTML with Multiple Patterns Per Matcher
8.9. Validating HTML with Multiple Patterns Per Matcher Here's a Java version of the Perl program to validate a subset of HTML (˜ 132). This snippet employs the usePattern method to change a matcher's pattern on the fly. This allows multiple patterns, each beginning with Pattern pAtEnd = Pattern.compile("\\G\\z"); Pattern pWord = Pattern.compile("\\G\\w+"); Pattern pNonHtml = Pattern.compile("\\G[^\\w<>&]+"); Pattern pImgTag = Pattern.compile("\\G(?i)<img\\s+([^>]+)>"); Pattern pLink = Pattern.compile("\\G(?i)<A\\s+([^>]+)>"); Pattern pLinkX = Pattern.compile("\\G(?i)</A>"); Pattern pEntity = Pattern.compile("\\G&(#\\d+;\\w+);"); Boolean needClose = false; Matcher m = pAtEnd .matcher( html ); // Any Pattern object can create our Matcher object while (! m .usePattern( pAtEnd ).find()) { if ( m .usePattern( pWord ).find()) { ... have a word or number in m. group () can now check for profanity, etc ... } else if ( m .usePattern( pImgTag ).find()) { ... have an image tag can check that it's appropriate ... } else if (! needClose && m .usePattern( pLink ).find()) { ... have a link anchor can validate it ... needClose = true; } else if ( needClose && m .usePattern( pLinkX ).find()) { System.out.println("/LINK [" + m .group() + "]"); needClose = false; } else if ( m .usePattern( pEntity ).find()) { // Allow entities like > and { } else if ( m .usePattern( pNonHtml ).find()) { // Other (non-word) non-HTML stuff simply allow it } else { // Nothing matched at this point, so it must be an error. Grab a dozen or so characters // at our current location so that we can issue an informative error message m .usePattern(Pattern.compile("\\G(?s).{1,12}")).find(); System.out.println("Bad char before '" + m .group() + "'"); System.exit(1); } } if ( needClose ) { System.out.println("Missing Final </A>"); System.exit(1); } Because of a java.util.regex bug causing the "non-HTML" match attempt to " consume " a character of the target text even when it doesn't match, I moved the non-HTML check to the end. The bug is still there, but now manifests itself only in the error message, which is updated to indicate that the first character is missing in the text reported. I've reported this bug to Sun. Until the bug is fixed, how might we use the one-argument version of the find method to solve this problem? Turn the page for the answer.
8.9.1. Parsing Comma-Separated Values (CSV) TextHere's the java.util.regex version of the CSV example from Chapter 6 (˜ 271). It's been updated to use possessive quantifiers (˜ 142) instead of atomic parentheses, for their cleaner presentation. String regex = // Puts a double quoted field into group(1), an unquoted field into group(2) . " \\G(?:^,) \n"+ " (?: \n"+ " # Either a double-quoted field ... \n"+ " \" # field's opening quote \n"+ " ([^\"]*+ (?: \"\" [^\"]*+)*+) \n"+ " \" # field's closing quote \n"+ " # ... or ... \n"+ " # some non-quote/non-comma text ... \n"+ " ([^\",]*+) \n"+ ") \n"; // Create a matcher for the CSV line of text, using the regex above . Matcher mMain = Pattern.compile( regex , Pattern.COMMENTS).matcher( line ); // Create a matcher for This is more efficient than the original Java version shown on page 217 for two reasons: the regex is more efficient as per the Chapter 6 discussion on page 271, and a single matcher is used and reused (via the one-argument form of the reset method), rather than creating and disposing of new matchers each time. |
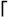 \G
\G  , to "tag team their way through a string. See the text on page 132 for more details on the approach.
, to "tag team their way through a string. See the text on page 132 for more details on the approach. EAN: 2147483647
Pages: 113