Creating the XSD Schema
| for RuBoard |
As you saw yesterday , you can create a strongly typed DataSet using the graphical designer. When you do so, the designer is actually creating an XSD document behind the scenes that is visible by clicking on the XML pane at the bottom of the designer. This is shown in Listing 7.4. In the XML pane, you can edit the XML being produced and even take advantage of IntelliSense.
Note
When you right-click on the XML designer and select the Generate DataSet option, the msdata namespace (defined by the URN schemas-microsoft-com:xml-msdata ) is added to the definition of the XML document in the root schema element, as is shown in Listing 7.4. Attributes from this namespace are used to add supplementary information to the schema that the DataSet generator will use to write the code for the derived DataSet class. For example, the IsDataSet attribute is added and set to True for the top-level element in the DataSet . In addition, as you'll see shortly, these attributes are maintained internally by the DataSet and can be seen when using the GetXmlSchema , WriteXmlSchema , and WriteXml methods of the DataSet . Essentially, the msdata attributes are what allow an XSD schema to be mapped to a DataSet behind the scenes.
Listing 7.4 The XSD document. This XSD was produced by the XML Schema Designer for the TitlesDs strongly typed DataSet .
<?xml version="1.0" encoding="utf-8"?> <xs:schema id="TitlesDs" targetNamespace="http://www.computebooks.com/TitlesDs" elementFormDefault="qualified" attributeFormDefault="qualified" xmlns="http://www.computebooks.com/TitlesDs" xmlns:mstns="http://www.computebooks.com/TitlesDs" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" version="1.0"> <xs:element name="TitlesDs" msdata:IsDataSet="true"> <xs:complexType> <xs:choice maxOccurs="unbounded"> <xs:element name="Reviews"> <xs:complexType> <xs:sequence> <xs:element name="ReviewID" msdata:DataType="System.Guid, mscorlib, Version=1.0.3300.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" type="xs:string" /> <xs:element name="ISBN" type="xs:string" /> <xs:element name="ReviewText" type="xs:string" /> <xs:element name="Stars" type="xs:unsignedByte" /> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="Titles"> <xs:complexType> <xs:sequence> <xs:element name="ISBN" type="xs:string" /> <xs:element name="Title" type="xs:string" /> <xs:element name="Description" type="xs:string" minOccurs="0" /> <xs:element name="Author" type="xs:string" /> <xs:element name="PubDate" type="xs:dateTime" /> <xs:element name="Price" type="xs:decimal" /> <xs:element name="Discount" type="xs:decimal" minOccurs="0" /> <xs:element name="BulkDiscount" type="xs:decimal" minOccurs="0" /> <xs:element name="BulkAmount" type="xs:short" minOccurs="0" /> <xs:element name="CategoryName" type="xs:string" minOccurs="0" /> <xs:element name="PubName" type="xs:string" minOccurs="0" /> </xs:sequence> </xs:complexType> </xs:element> </xs:choice> </xs:complexType> <xs:unique name="TitlesDsKey2" msdata:PrimaryKey="true"> <xs:selector xpath=".//mstns:Reviews" /> <xs:field xpath="mstns:ReviewID" /> </xs:unique> <xs:unique name="TitlesDsKey3" msdata:PrimaryKey="true"> <xs:selector xpath=".//mstns:Titles" /> <xs:field xpath="mstns:ISBN" /> </xs:unique> <xs:keyref name="TitlesReviews" refer="TitlesDsKey3" msdata:AcceptRejectRule="Cascade" msdata:DeleteRule="Cascade" msdata:UpdateRule="None" msdata:IsNested="true"> <xs:selector xpath=".//mstns:Reviews" /> <xs:field xpath="mstns:ISBN" /> </xs:keyref> </xs:element> </xs:schema>
| | You'll notice in Listing 7.4 that the XSD is simply an XML document with a root-level schema tag that contains tags such as complexType , element , attribute , and keyref that define the structure of an XML document based on the XSD. You'll also notice that the schema is annotated with attributes from the msdata namespace that control how the schema will map to specific features of the DataSet class. |
Although the syntax for XSD documents is beyond the scope of this book, the XML Schema Designer makes it easy to get started writing schemas by providing the XML Schema tab in the Toolbox. The descriptions of the items in the tab found in Table 7.1 coupled with the online documentation should be enough to get you started designing your own schema that can be generated as a strongly typed DataSet or used simply with XML documents.
Table 7.1. XML Schema toolbox items. The icons and their descriptions visible in the XML Schema tab of the Toolbox when designing a DataSet (XSD).
| Class | Description |
|---|---|
| | Used to declare an element. When dropped on the design surface, it creates an element tag with a child complex type that can be filled with other elements or attributes. Used to define the highest-level DataTable classes in a DataSet . |
| | Used to declare an attribute of an element. When dropped independently on the design surface, it creates an attribute for the highest-level element in the document. |
| | Used to group a set of attribute definitions so that they can be used inside a complex type definition. In a DataSet , the attributes are simply added to the DataTable defined by the complex type. Enables reuse of the attributes. |
| | Used to define the set of elements and attributes defined by one of the following child elements: simpleContent (contains a simpleType or text with attributes but no elements), complexContent (contains only elements or is empty), group (contains a reference to a group), sequence (contains the specified elements in the given order), choice (contains only one of the elements), or all (contains any or none of the elements). In a DataSet , it is used to represent the DataTable structure. Can also be used to define abstract contents used as the basis for derived complex types (analogous to a base class). |
| | Used to define a type derived from a built-in data type or another simple type. Can be defined with facets such as restrictions for min and max values and length, a list of whitespace-separated values, or an enumeration. The DataSet generator maps only restrictions to properties that have equivalents in the DataColumn ; it does not create enumerations as defined in the XSD. |
| | Used to group a set of element definitions to be used in a complex type. Can be defined by choice , sequence , or all . In a DataSet , the elements of the group are simply added to the DataTable . Enables reuse of the set of the elements. |
| | Used to enable any element to appear from this namespace or any other. Can also specify whether the XML processor should attempt to validate the contents of this element. Not used in a DataSet . |
| | Used inside of a simple type to define the restrictions that can be placed on it. Facets such as maxLength are read by the DataSet generator and used to populate the MaxLength property of the DataColumn object. |
| | Used to enable any attribute to appear from this namespace in a complex type or attribute group. Can also specify whether the XML processor should attempt to validate the attribute. Not used in a DataSet . |
| | Used to define an element or attribute as unique, non-nullable, and always present data for the define scope. When selected, a dialog is displayed where you can define the key. In a DataSet , the key is mapped to the primary key of the DataTable using the PrimaryKey attribute of the msdata namespace. Primary keys can also be defined using the unique element. |
| | Used to define the data relation and invokes the dialog shown in Figure 2.6 of Day 2, "Getting Started." In the XSD, a keyref element is created that refers to the key or unique element from the parent. Its attributes from the msdata namespace control the rules for cascading updates and deletes and automatically accepting changes. |
As a rule, keep in mind that each time you define a complex type, you are defining a DataTable , and that the elements and attributes within the complex type will be represented as columns in that table. To nest complex types, you have two options. First, you could create them separately and then create relations between them with the IsNested property set to True . In that way, the XML generated from the DataSet will be nested. However, this has the downside of not actually being represented in the XSD because setting the IsNested property simply adds the IsNested attribute from the msdata namespace to the keyref element in the XSD.
Alternatively, you have the option of defining a nested complex type directly by choosing the Unnamed complexType option from the Type drop-down when defining the element. Then you can name and create the elements and attributes of the child type. In this case, the DataSet generator will automatically create a hidden column ( MappingType.Hidden ) and a DataRelation in the child DataTable that refers to the primary key column of the parent type and whose Nested property is set to True . Creating the Reviews complex type for the TitlesDs DataSet using this technique would look like the diagram in Figure 7.1 (contrasted with Figure 6.2).
Figure 7.1. Nested complex types. This is a screenshot of the XML Schema Designer when the Reviews element is created as a child element of Titles .
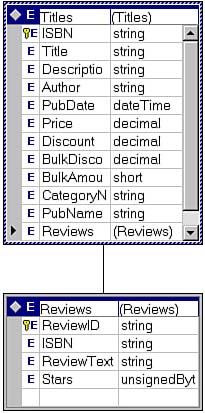
Note
Although the diagram in Figure 7.1 doesn't show it, the relationship between the two complex types is, of course, predicated on the ISBN element of each.
Creating the Schema Dynamically
Although creating a schema to serve as the basis for a strongly typed DataSet at design time using the schema designer is recommended and ensures a correct schema, there are scenarios in which this is not practical. For example, consider the situation in which you want to dynamically create schemas based on database tables in order to send those schemas to a trading partner. Or when you receive a schema, or simply an XML document, from a trading partner and want to create a DataSet to handle the incoming data. In these scenarios, you can use the FillSchema method of a data adapter, or the ReadXmlSchema and InferXmlSchema methods of the DataSet class.
Note
Although the methods discussed in this section also work with the XML Data Reduced (XDR) grammar that Microsoft introduced before XSD became a World Wide Web Consortium (www.w3c.org) recommendation, you should use XSD whenever possible because it's the standard and because support for XDR is not guaranteed in future releases of the .NET Framework.
Filling from a Database
When you want to dynamically create schemas based on database tables in order to send those schemas to a trading partner, you could create a method that writes the XSD schema to a file based on the result set returned from a SQL Server stored procedure, as shown in Listing 7.5.
Listing 7.5 Creating the schema from a database. The WriteSqlSchema method populates the structure of a DataSet using the FillSchema method of the data adapter.
Public Sub WriteSqlSchema(ByVal storedProc As String, _ ByVal filePath As String, ByVal tableNames() As String) Dim con As New SqlConnection(_connect) Dim da As New SqlDataAdapter(storedProc, con) Dim ds As New DataSet() da.SelectCommand.CommandType = CommandType.StoredProcedure Try If Not tableNames Is Nothing Then ' Add the table mappings Dim t, dsTab As String Dim i As Integer For Each t In tableNames If i = 0 Then dsTab = "Table" Else dsTab = "Table" & i.ToString End If da.TableMappings.Add(dsTab, t) i += 1 Next End If ' Fill the DataSet da.FillSchema(ds, SchemaType.Mapped) ds.WriteXmlSchema(filePath) Catch e As SqlException ' Handle SQL Server errors Catch e As Exception ' Handle other errors here (IO) End Try End Sub
| | The WriteSqlSchema method in Listing 7.5 first creates the connection and data adapter that will be used to communicate with the data store; in this case, with SQL Server. In addition to being passed the name of the stored procedure to execute and the path of the file to write to, the method accepts an array of table names that will be used to map the tables returned from the database to DataTable objects created in the DataSet . As you can see, the array of table names is traversed and each is added to the TableMappings collection of the data adapter using the Add method. The dsTab variable denotes the default name in the DataSet that each table will be given by the data adapter, whereas t denotes the new name. By adding new table mappings, you override the default behavior in which the data adapter creates tables named Table, Table1, and so on for each result set returned from the SelectCommand of the data adapter. |
The FillSchema method is then called and passed both a DataSet object to fill and a value from the SchemaType enumeration. FillSchema automatically opens and closes the database connection, and is also overloaded to accept a single DataTable as well as an entire DataSet along with a specific table mapping to use. In this case, SchemaType.Mapped instructs the FillSchema method to use any existing table mappings and schema for the DataSet rather than ignoring them, as can be done by passing the SchemaType.Source value to the method.
Note
Although not used in Listing 7.4, the FillSchema method also returns either a single DataTable object or an array of DataTable objects depending on whether the SelectCommand of the data adapter returns one or more than one result set.
When FillSchema executes, it populates the AllowDBNull , AutoIncrement , MaxLength , ReadOnly , and Unique properties of the DataColumn objects from data provided by the data source while not returning any data. In SQL Server, this is accomplished by the data adapter executing the SET NO_BROWSETABLE ON statement before executing the command and turning it off afterward. If a primary key is present, it creates a unique element in the XSD to represent it. In the case where a primary key is not present, it looks for unique constraints and uses their combination as the primary key as long as none of them allows nulls. Columns that are not named are simply named Column1, Column2, and so forth as you might expect.
Tip
Unfortunately, the OleDbDataAdapter creates a DataTable object for only the first result set returned, while SqlDataAdapter can handle multiple result sets. However, if you must use OLE DB, you can use the Fill method of the OleDbDataAdapter and make sure that the MissingSchemaAction property is set to AddWithKey .
As you probably would have guessed, the FillSchema method cannot create relationships between tables even if more than one result set is returned by the SelectCommand and the base tables have a foreign key relationship. This is because it does not retrieve foreign key constraints from the database.
Finally, the XSD is written to the file using the WriteXmlSchema method, which we'll explore in more detail shortly.
Loading from a Schema
Of course, in addition to programmatically constructing the schema from a database, you could also create it directly from an existing XSD using the ReadXmlSchema method of the DataSet class. This technique might come in handy if you need to dynamically create DataSet objects that correspond to schemas that cannot be specified at design time. It can also be used in derived DataSet classes to maximize flexibility and maintainability in your application.
For example, rather than create a strongly typed DataSet using the XML Schema Designer and the DataSet generator, you might want to create your own class that inherits from DataSet and then, in its constructor, call the ReadXmlSchema method to load a schema from the file system, as shown in Listing 7.6.
Listing 7.6 A weakly typed DataSet . This complete DataSet class loads its structure at runtime when the constructor is called.
<Serializable()> _ Public Class OrdersDs : Inherits DataSet Public Sub New() MyBase.New() initclass() End Sub Public Sub New(ByVal info As SerializationInfo, _ ByVal context As StreamingContext) MyBase.New() InitClass() Me.GetSerializationData(info, context) End Sub Private Sub InitClass() ' Read in the schema Try Me.ReadXmlSchema("OrdersDs.xsd") Catch e As Exception Throw New TypeInitializationException("Cannot load OrdersDs.xsd", e) End Try End Sub End Class | | In Listing 7.6, the OrdersDs DataSet is derived from DataSet and includes the private InitClass method that attempts to load the schema using the ReadXmlSchema method. Note that the file is hard-coded here, but that ReadXmlSchema is overloaded to accept an XmlReader , stream, or TextReader as well. If the file can't be loaded because it can't be found or is an invalid schema, an exception will be thrown and the exception will be caught and encapsulated as the InnerException of the standard TypeInitializationException . Although in this example the file passed to ReadXmlSchema ostensibly contains only the XSD, ReadXmlSchema can also read an in-line schema (one that is present along with the data) from an XML document. |
Note
The Serializable attribute and the constructor that accepts the SerializationInfo and StreamingContext objects from the System.Runtime.Serialization namespace must be present in the event the DataSet is passed between AppDomains.
If the DataSet already contained a schema, it would have been augmented by the ReadXmlSchema method by adding new tables and columns where appropriate. If, however, the data type of an existing column conflicts with the new schema information, an exception will be thrown. Data types will conflict if, for example, the XSD type in the new schema maps to a different .NET type, as shown in Table 7.2.
Table 7.2. XSD to .NET types. This table shows the XSD type and .NET equivalent.
| XSD Type | .NET Type |
|---|---|
| anyURI | System.Uri |
| base64Binary , hexBinary | System.Byte() |
| Boolean | System.Boolean |
| Byte | System.SByte |
| Date , dateTime , gDay , gMonthDay , gYear , gYearMonth , month , time , timePeriod | System.DateTime |
| decimal , integer , negativeInteger , nonNegativeInteger , nonPositiveInteger , positiveInteger | System.Decimal |
| Double | System.Double |
| duration | System.TimeSpan |
| ENTITIES , IDREFS , NMTOKENS | System.String() |
| ENTITY , ID , IDREF , language , Name , NCName , NMTOKEN , normalizedString , notation , string , token | System.String |
| Float | System.Single |
| int | System.Int32 |
| long | System.Int64 |
| QName | System.Xml.XmlQualifiedName |
| short | System.Int16 |
| unsignedShort | System.UInt16 |
| unsignedInt | System.UInt32 |
| unsignedLong | System.UInt64 |
Although all the rules for how an XSD maps to a DataSet are beyond the scope of this book and can be found in the online documentation, the following general rules apply:
-
A DataTable is created for each complexType element. Each element and attribute of the complexType are mapped to columns.
-
If one complexType is nested inside another, a foreign key constraint, data relation, and hidden column are created on the child table.
-
Data types in the schema map to the .NET types as shown in Table 7.2.
-
unique elements are mapped to unique constraints in the DataTable and the AllowDBNull property of the column is set to True .
-
key elements are mapped to unique constraints and the AllowDBNull property of the column is set to False .
-
keyref elements are mapped to a foreign key constraint and a corresponding data relation.
-
The maxLength restriction on a simpleType maps to the MaxLength property of the DataColumn .
Even though these rules are a good start, they obviously don't contain all the information that can be specified in a DataSet . As a result, you can also add to the XSD the attributes from the msdata namespace mentioned previously before you read it in using the ReadXmlSchema . This can be done either by editing the document directly, using a tool such as XML Spy or VS .NET, or programmatically, using the classes of the System.Xml namespace. For example, you can either stream through the XML using the XmlTextReader and XmlTextWriter or use the Document Object Model as exposed through the XmlDocument class. To give you an idea for how this would be accomplished, the AddPk method shown in Listing 7.7 adds the IsPrimaryKey attribute to a key element of the XSD document passed into the method. I'll leave it to you to explore the XmlDocument class and its members .
Tip
Alert readers will notice that the msdata namespace declaration is added to the key element directly rather than to the top-level schema element as is done by the XML Schema Designer. The code could easily be modified to add the namespace declaration first and then add the primary key attribute.
Listing 7.7 Modifying the XSD. This method marks one of the key elements of the XSD as the primary key prior to reading it into a DataSet .
Public Function AddPk(ByVal keyElement As String, _ ByVal xsdFile As String) As Boolean Dim xml As New XmlDocument() Dim key As XmlNode Dim keys As XmlNodeList Dim att As XmlAttribute Try xml.Load(xsdFile) att = xml.CreateAttribute("msdata", "IsPrimaryKey", _ "urn:schemas-microsoft-com:xml-msdata") att.Value = "true" keys = xml.GetElementsByTagName("xs:key") For Each key In keys If key.Attributes("name").Value = keyElement Then key.Attributes.Append(att) xml.Save(xsdFile) Return True End If Next Return False ' The keyelement was not found Catch e As XmlException ' Handle XML errors Catch e As Exception ' Others End Try End Function Loading from a Document
In the event the ReadXmlSchema method is not passed an XSD or an XML document with an in-line schema, it will automatically attempt to infer the schema from the document. This also can be accomplished directly by calling either the InferXmlSchema or the ReadXml method whose overloads accept an XML document through an XmlReader , file path, stream, or TextReader .
Regardless of the method used to infer the schema from a document, the framework uses certain inference rules, the most important of which are as follows :
-
Elements that have attributes or child elements map to tables. The attributes and child elements are mapped to columns.
-
Elements with multiple occurrences are mapped to a single table.
-
Attributes, and elements that have no attributes or child elements and that do not repeat, are mapped as columns.
-
If the root element of the document has no attributes and no child elements that map to columns, it is mapped to a DataSet . Otherwise , it is mapped to a table.
-
If a nested or child element is inferred as a table, a DataRelation and ForeignKeyConstraint are created between the child and parent table, and primary key columns are created in both tables.
-
If an element is mapped to a table and has a text value but no child elements, a column called tablename _Text is created for the text of the element. However, if the element has text and also has child elements, the text is ignored.
Something that might not be immediately obvious from these rules is that the process of inferring the schema is non-deterministic . By that, I mean that two XML documents created from the same schema will not necessarily create identically structured DataSet objects due to the presence or absence of data. This is the case because schemas can define optional elements and might or might not contain repeating elements. This is a good reason to use schemas wherever possible and resort to inference only where necessary.
To see these rules applied, consider the XML document shown in Listing 7.8, which represents sales information for ComputeBooks titles.
Listing 7.8 Sales data. The XML shown here represents sales figures by time period and title for ComputeBooks stores.
<Sales> <Title ISBN="06720001X"> <TimePeriod Date="1/2002"> <Store id="31B32710-C58A-4483-BB84-4D12865C7772"> <Units>16</Units> <BulkUnits>56</BulkUnits> <Revenue>456.50</Revenue> </Store> </TimePeriod> <TimePeriod Date="2/2002"> <Store> <Units>31</Units> <BulkUnits>75</BulkUnits> <Revenue>789.77</Revenue> </Store> </TimePeriod> </Title> <Title ISBN="06720002X"> <TimePeriod Date="1/2002"> <Store id="31B32710-C58A-4483-BB84-4D12865C7772"> <Units>321</Units> <BulkUnits>50</BulkUnits> <Revenue>6789</Revenue> </Store> <Store id="57E088EF-3929-41A6-B35F-79048B965489"> <Units>33</Units> <BulkUnits>0</BulkUnits> <Revenue>612.67</Revenue> </Store> </TimePeriod> </Title> </Sales>
The following code snippet could then be used to infer the schema from this document:
Dim sales As New DataSet() sales.InferXmlSchema("sales.xml", Nothing) The end result is a DataSet with no data and the following structure:
DataSet : TableName = Sales
Tables (3):
Title ( Title_Id , ISBN )
TimePeriod ( TimePeriod_Id , Date , Title_Id )
Store ( Units , BulkUnits , Revenue , id , TimePeriod_Id )
Relations (2):
TimePeriod_Store ( ForeignKeyConstraint that relates TimePeriod_Id columns in Store and TimePeriod )
Title_TimePeriod ( ForeignKeyConstraint that relates Title_Id columns in TimePeriod and Title )
You'll notice from the preceding description that when the DataSet is inferred, the Sales element (the root element) is mapped to the DataSet rather than being mapped to a table. This is because it has no attributes and its child elements are mapped to tables. Three tables are then created because the Title , TimePeriod , and Store elements all have both attributes and child elements that were mapped as columns. Because the Store element was nested inside the TimePeriod element and the TimePeriod inside the Title , two ForeignKeyConstraint objects were created and added to the DataRelationCollection . In addition, primary keys for each of the parent tables ( Title_Id and TimePeriod_Id ) were created as auto-incrementing integer columns. Within the DataTable objects, the columns each have their ColumnMapping property set appropriately. For example, the ISBN column is set to MappingType.Attribute , whereas the Title_Id column is set to MappingType.Hidden .
Note
Obviously, the inferred DataSet in this case accurately represents the data, but it does so with the added baggage of columns that needn't have been created and data types that might not be preferred. The ISBN column of the Title table, the Date column of the TimePeriod table, and the id column of the Store table could just as well have served as primary keys. However, without being able to define them as such in a schema, the framework doesn't have any way of knowing which column is the key. In addition, columns that you would probably like to be numeric are mapped to the System.String data type because the inference process must assume the widest possible interpretation. These are also reasons to use schemas where possible rather than relying on inference.
You'll also notice from the code snippet following Listing 7.8 that the InferXmlSchema method accepts a second argument, which in this case was set to Nothing . The argument can contain an array of namespaces that are to be ignored during the creation of the DataSet . This allows you to read in a document and ignore namespaces that contain data meant for other purposes.
As mentioned previously, the InferXmlSchema method simply creates the schema and does not load any data. To both infer the schema and load the data, you can use the ReadXml method. This overloaded method accepts the same input ( XmlReader , TextReader , stream, and filename) as InferXmlSchema , but also accepts an optional second argument that specifies how the XML data is read into the DataSet through the XmlReadMode enumeration, as shown in Table 7.3.
Table 7.3. XmlReadMode enumeration. This enumeration is used to specify how the ReadXml method processes the XML it is given.
| Value | Description |
|---|---|
| Auto | The default. When set to Auto , the ReadXml method will automatically set the XmlReadMode appropriately, depending on the contents of the XML. It will use DiffGram when it detects a DiffGram, ReadSchema if the DataSet already has a schema or the document has an in-line schema, and InferSchema otherwise. |
| DiffGram | Reads the DiffGram and applies its changes to the DataSet using the same semantics as the Merge method. The DiffGram schema must match the schema of the DataSet or an exception will be thrown. |
| Fragment | Reads XML documents generated by the FOR XML statement in SQL Server 2000 using the default namespace as the in-line schema. |
| IgnoreSchema | Ignores an in-line schema if one exists. Data that does not match the existing DataSet schema is discarded (new schema information is not inferred). |
| InferSchema | Ignores an in-line schema if one exists and instead infers the schema and loads the data. If the DataSet contains a schema, it is extended and exceptions are thrown when existing tables or columns conflict. |
| ReadSchema | Reads an in-line schema if one exists and infers and loads the data, extending the schema of the DataSet . Unlike InferSchema , an exception is thrown if the DataSet already contains any of the tables from the in-line schema. |
Obviously, the XmlReadMode argument makes the ReadXml method the most flexible in terms of loading a DataSet from an XML document with or without an in-line schema. For example, you can use the ReadSchema value when you simply want to load additional tables to an existing DataSet or the IgnoreSchema when you want to load only data that matches the existing DataSet structure. The following snippet loads the sales data using the InferSchema value, which would be automatically set because the document doesn't contain an in-line schema and the DataSet doesn't contain a schema:
Dim sales As New DataSet() sales.ReadXml("sales.xml", XmlReadMode.InferSchema) Note
All the overloaded signatures of the ReadXml method return the XmlReadMode used during its processing. This is useful if you don't use the second argument or pass it Auto . In that way, you can tell from which read mode was used, and what the document and DataSet contained.
The DiffGram and Fragment values are particularly interesting because they can be used with XML generated in different ways. For example, the DiffGram value can be used to make changes to a DataSet by applying it through the ReadXml method. This would be useful if your application serializes the DiffGram to a file and then later needs to merge the DiffGram with new data retrieved from a data store. The Fragment value allows you to load partial XML documents like those produced by the FOR XML statement in SQL Server, which you'll learn more about on Day 10, "Using Commands."
| for RuBoard |
EAN: 2147483647
Pages: 158