| Obviously, when dealing with documents that may reside in different places, it saves time to have a local copy of the data contained in these documents to search. This data originates from different document formats, such as Microsoft Word or HTML. Storing this data in a common, optimized format will further improve the times necessary to search. This local copy is called an index, which in effect is a database optimized for searching textual information. Such a copy of data, though, will create new challenges in terms of keeping the indexed information up to date and accurate.  For more information on the algorithms and approaches used to overcome the challenges of indexing, see "Keeping the Index Up to Date," p. 497. For more information on the algorithms and approaches used to overcome the challenges of indexing, see "Keeping the Index Up to Date," p. 497. NOTE Since the index is a copy of data that still continues to exist elsewhere, it requires additional storage. Due to the dedicated common index format, this size can be reduced to about 30% of all searchable text, though.
The Coordinator can specify which documents need to be indexed. And of course there is no need to specify each individual document; instead, the Coordinator can benefit from typical document storage modelsa hierarchical model (such as in a file system) or a linked model where references to other documents are made (such as in a Web site). The Coordinator simply specifies a content source, which is defined by the first (or top) document and the crawl depth. CAUTION Multiple content sources can be specified. Some of them may overlap, however. This might cause some problems, such as multiple references to the same document, or missing documents if one of the overlapping content sources is removed.
As we discussed previously, one major design goal of SPS was to be self-serviceable. Allowing a Coordinator to specify the content sources crawled and updated by SharePoint Portal Server might be appropriate in some cases. However, the real work of identifying and updating the content of the index is often best left to subject matter experts, or SMEs. SharePoint Portal Server facilitates this well. Instead of requiring a pure administrator, the department leveraging SPS may now self-service its environmentwithin the boundaries set by the administrator. For more details on the administrator's tasks , see "Index Housekeeping," p. 488. A key benefit of the SharePoint Portal Server architecture is that a clear split between the content source and the document format is made. And that comes in handy, because now the component responsible for retrieving the searchable text can be reused. For example, Microsoft PowerPoint documents can reside in different places, but the logic to "crack" the document format always remains the same. Separating Document Location and Document Content So let's take a closer look under the hood. For every content source from which the documents are gathered, the Microsoft Search Service processMSSearch, or the process that maintains the indexlaunches a dedicated task. These tasks are implemented as a Protocol Handler, which retrieves document content through the protocol (hence the name ) required to access the repository in which the document resides. Such protocols include, for example, HTTP for Web sites or MAPI for Exchange 5.5 public folders. Note the difference between a Protocol Handler and a content sourcethe Protocol Handler is the method used to access the content source, which is really just the basis of the data that will eventually find itself indexed. Out-of-the-box Content Sources SharePoint Portal Server provides out-of-the-box support for the following types of content sources: -
SharePoint Portal Server workspaces -
Microsoft Exchange public folders (both Exchange 2000 and Exchange 5.5) -
File shares -
Web sites -
Lotus Notes -
FTP (File Transfer Protocol) sites (included in the Resource Kit for SharePoint Portal Server) -
SharePoint Team Services (added in Service Pack 1) NOTE You cannot crawl secured Web sites, i.e. sites that are only accessible through the HTTPS protocol.
Each of these content sources are covered in greater detail elsewhere in this book, from different perspectives like features and capabilities (Chapter 2), to accessing content (Chapter 8), to security considerations (Chapter 11), to crawling (Chapter 18). Out-of-the-box IFilters Now that we understand the role of Protocol Handlers, we need to understand how the searchable information is obtained. This is the responsibility of filters (also known as IFilters) that are loaded by the Protocol Handler. That is, data pulled from the Protocol Handler is passed to the various filters, which then extract the text data from the content sources and send it off to the index. This architecture allows filters, which are responsible for the actual retrieval of text within the document, to be reused by any Protocol Handler, while the Protocol Handler knows nothing about the content. The set of document formats that are supported out-of-the-box are -
Plain text files -
Microsoft Word -
Microsoft Excel -
Microsoft PowerPoint -
HTML -
MIME (Multipurpose Internet Mail Extensions) encoded Mail Messages, as for example stored in Exchange 2000 -
TIFF (Tagged Image File Format) files using Optical Character Recognition, or OCR, technology to retrieve textual content, for example from facsimile messages -
RTF (Rich Text Format) (included in the SharePoint Portal Server Resource Kit) -
XML (included in the SharePoint Portal Server Resource Kit) -
Various third-party data formats, as developed and supported by those third parties NOTE Optical character recognition will only work for Latin, Cyrillic, and Greek character sets. This covers European languages but excludes Thai, Japanese, Chinese, and others (often referred to as "double-byte" languages, given their complexity).
Optical Character Recognition of TIFF Files As OCR is an extremely resource- intensive task, it is not enabled by default. Before enabling it, ensure that you understand the impact of doing so on your particular SharePoint Portal Server deployment. Hardware resources like CPU, RAM, Pagefile, and disk space will be impacted. Work with your hardware vendor and systems integrator, if necessary, to characterize, size for, and perhaps even perform a pilot to better understand this impact. Once the magnitude of the impact is understood and addressed, enable OCR recognition by double-clicking tiff_ocr_on.reg in the Support\Tools directory of the Microsoft SharePoint Portal Server CD. You may also enable OCR within TIFF files by performing the following: -
From the SPS server, click Start, Run. -
Type regedit, and then press Enter or click OKthe Registry Editor starts. -
Navigate to HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\MSPaper, and right-click it. -
Click New, then click DWORD Valuea new key appears. -
Give the key the name PerformOCR. -
Right-click PerformOCR, and click Modifya dialog box named Edit DWORD Value is displayed. -
To actually enable OCR, enter a value of 1note that to disable OCR, type 0. -
Click OK, and then close the Registry Editor. -
At this point, it is necessary to restart the MSSearch service via the Control Panel. Now that OCR is enabled, you can enable automatic file rotation , where a TIFF is rotated in memory before being scanned. This greatly increases the scanning accuracy of files that are oriented sideways or even upside down (due to being initially scanned sideways or upside down). Of course, the trade-off is an even larger impact on the server's RAM and CPU resources. Be sure to test this impact prior to implementing automatic file rotation. Gathering Architecture This search engine and index is the successor to earlier Microsoft search products, such as the Index Server and Site Server. Based on this mature technology, the results of some advanced Microsoft-driven research projects have been integrated into this enhanced search engine, including auto categorization and an improved ranking algorithm. This origin is important to know, given that the search engine is a component that is also used by Microsoft SQL Server and Microsoft Exchange 2000. NOTE SharePoint Portal Server upgrades MSSEARCH.EXE, the process or service that largely implements the search engine. Due to dependencies, some problems exist with the uninstallation of Microsoft SQL Server or Microsoft Exchange 2000, if they are installed on the same server. Such configuration, though, is discouraged for production use due to the resource requirements for each of these products.
The following figure summarizes the core components involved when content is gathered. Access protocols, which typically include some network components and processing documents that may contain some unexpected characters , may cause a Protocol Handler or an IFilter to malfunction. To avoid this bringing down the entire search engine, these components run in separate MSSDMN processes that are started by the MSSearch process as needed. Let's illustrate this with an example of a content source which refers to a file share. This share is crawled using the Protocol Handler registered for the "file:" protocol. For each Office document found, the Office IFilter retrieves all information that is of interest or required to find the document in a later search: the text and Office properties. Figure 5.4. A schematic overview of the components that are involved in building and maintaining the index. 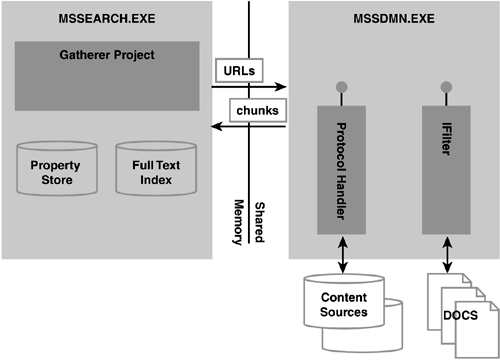 NOTE Protocol Handlers and filters can be written by anyone , though this is an advanced programming task. Filters have already been introduced with the Windows 2000 Index Server, and the required interfaces are documented in the Platform SDK. Third parties have successfully implemented filters, such as Adobe's filter for the PDF file format. The SharePoint Portal Server SDK includes documentation for creating a Protocol Handler. Unfortunately, the sample "Simple Protocol Handler" is not fully functional and is so "simple" that some of the important concepts such as property mapping and security are not covered at all.
Site Path Rules The Coordinator can specify the crawl depth for content sources; for example, just the initial or home page or all pages on that site. URLs that include a question mark are by default excluded. You will encounter these kinds of URLs typically when you are indexing Active Server Pages, as the portion following the question mark is passed as a query string to the actual script that is executing. In other words, these parameterized Web pages will by default not be indexed. Using Site Path Rules, however, you can enable these types of complex links. They also allow for a much finer granularity with respect to the Web pages that get indexed. And finally, Site Path Rules allow defining a specific account to crawl a particular Web Site. To read more about how Site Path Rules can be applied, see "Keeping the Index Up to Date," p. 497. Respecting Security and Other Conventions SharePoint Portal Server will typically crawl under an administrative account, so that as much information as possible can be gathered in the index. Consequently, the index may contain information that should not be visible to a specific user when the search is issued. Even though opening the real document through the URL would be prohibited through the access checks enforced by the underlying repository, the existence aloneand more so the valueof some properties would make the result set not accurate. Therefore the security information from the original source is also copied into the index. For any search result, the security information is applied and documents to which users do not have read access are filtered out. Some Web site administrators prefer that their Web sites are not crawled. That is, they do not wish their site information to be stored in an indexand they may have good reasons for that, as their information may be highly volatile or confidential. To this end, SharePoint Portal Server will respect the conventions used in the robots.txt file on the top of the Web site (see http:// info .webcrawler.com/mak/projects/robots/norobots.html) and the HTML META robots tag within a document (<meta name="robots" content="no index">). For more discussion regarding the use of robots, see "Using Robots.txt and HTML Tags to Prevent Access," p. 213. Updating the Index With the introduction of the index as a local copy of the real data, a new problem has been introduced: the fact that the copy may quickly become out of date. Users expect that a search is accurate, or at least as accurate as possible. This means that the chance for both missed matches as well as incorrect matches must be minimized. Ideally, the content sources, or even better the underlying repository, would notify the index of changes. But this requires the existence of an event model that can be exploited, which is only available for the local SharePoint Portal Server content (as well as for any content on an NTFS file share). Unfortunately, most content sources will not notify the index of any changes. For this reason, SharePoint Portal Server was designed to leverage the following mechanisms: -
Full updates When a full update is performed, first all information about documents that were found in this content source is removed. Then the process of gathering all content starts. For a file system, for example, the "directories" will get enumerated, while for a Web site the new URLs found in the Web pages will get added to the list of documents. -
Incremental updates For an incremental update, SharePoint Portal Server will retrieve the last date of change from every document in the index. If that date is later than the last time of indexing, the information is out of date and the index will get updated. This method still is fairly resource intensive, as every indexed document is checked. But compared to the full update, clearly for large documents a substantial win is accomplished. Obviously, the incremental update is preferred over a full update. The following exceptions should be noted, however: If you are indexing a Web site, the Incremental Update will not notice if there is no link made to a specific document. This document thus remains searchable, although references no longer exist. Only if the document is removed with the last link will the Incremental Update notice the removal, and then update its index accordingly . Another scenario where a Full Update is required is a change of some global configuration information that is applied to all documents of a particular content source. As this information doesn't originate from the original document, but is added while indexing, unchanged documents will have the old information until they get re-indexed. -
Adaptive updates This is the most advanced mechanism to update the index, using a heuristic approach to determine if a document is to be indexed. While incremental updates do not eliminate the need to inspect the last modified date for each document, adaptive crawling takes this one step further. The algorithm coming from Microsoft research work is based on the assumption that information that changed frequently in the past is likely to get changed again in the near future. Therefore, SharePoint Portal Server gathers statistics regarding the rate of change for each document. To ensure that the indexed information of documents that have not changed for a long while remains accurate, an incremental crawl is scheduled once in a while as well. TIP Crawling for changed information is a resource-intensive operationnot only on the indexing side, but also on the remote server's side. Consider the usage of adaptive updates whenever possible. In Chapter 19, "Managing Indexing," more operational hints, such as the scheduling of updates, can be found.
|
